-
데이터 변경이력
데이터 변경이력 버전 일자 변경내용 비고 1.1 2023-12-15 데이터 최종 개방 1.0 2023-05-04 데이터 개방 (Beta Version) 데이터 히스토리
데이터 히스토리 일자 변경내용 비고 2023-12-15 산출물 전체 공개 2023-10-13 데이터명 변경 변경 전 데이터명: 문화유산 이미지 및 3D 데이터 소개
현실 공간의 문화유산 객체를 학습하여 가상현실 속 문화유산 객체 분류
구축목적
ㅇ 문화유산 3D 공간 데이터 축적과 보전ㆍ복원 관련 연구의 디지털화 - 기존의 인쇄매체, 2D 이미지 등의 문화재 정보ㆍ기록을 3D 데이터 형태로 구축 ㅇ 문화 콘텐츠 발굴 및 사용자 맞춤형 문화재 정보 서비스 구현 - 문화유산 정보를 사용자 요구에 따라 3D 디지털 공간에서 서비스로 구현
-
메타데이터 구조표 데이터 영역 문화관광 데이터 유형 3D 데이터 형식 las 데이터 출처 LiDAR 장비를 활용하여 자체 수집한 Point Cloud Data 라벨링 유형 바운딩박스(pcd) 라벨링 형식 json, csv 데이터 활용 서비스 AI의 Classification 모델을 사용하는 것으로 다양한 역사적 스토리와 문화적 가치가 있는 상징물을 사용자 카메라의 시야 안에서 탐지하는 것으로 다양한 서비스와 연결 가능 데이터 구축년도/
데이터 구축량2022년/104,660건 -
□ 데이터 구축 규모
구분 포맷 내용 구축량(건) PCD las 문화유산 객체 점군 데이터 104,660 속성정보 json 데이터셋 정보, 문화재 구분 정보 등 104,660 csv XYZ, RGB 정보 104,660 □ 테마별 분포
항목 구축량(건) 구성비(%) 주거생활 20,906 20 정치국방 10,774 10.3 교육,문화 10,534 10.1 유적,유물 10,337 9.9 무덤 5,119 4.9 산업생산 5,412 5.2 종교,신앙 15,549 14.9 역사 10,826 10.3 교통,통신 5,126 4.9 자연,유산 10,077 9.6 합계 104,660 100 □ 클래스별 분포
항목 구축량(건) 구성비(%) 조형물 10,061 9.6 탑, 비 5,750 5.5 도, 토기류 10,225 9.8 식생 15,560 14.9 벽 16,679 15.9 문 15,923 15.2 기둥 15,021 14.4 지붕 15,441 14.8 합계 104,660 100 □ 문화재 구분 분포
항목 구축량(건) 구성비(%) 지정문화재 61,998 59.2 비지정문화재 42,662 40.8 합계 104,660 100 -
-
AI 모델 상세 설명서 다운로드
AI 모델 상세 설명서 다운로드 AI 모델 다운로드□ 모델 학습
ㅇ 객체 분류 알고리즘에 대한 이미지 데이터 적용방안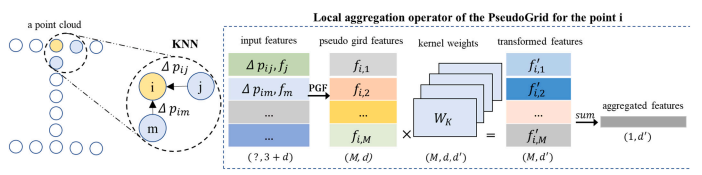
- ML기반 방법과 달리 DL기반 방법사용
- 복잡한 수동 기능 설계 또는 feature design을 자동적으로 진행
- 각각의 input point cloud data를 유사한 geometric shape으로 예측해주어 classification 진행□ 유효성 검증 환경
항목명 객체분류(한국 문화유산 3D데이터) 검증 방법 Docker image upload or evaluation 영상제출 목적 객체분류 지표 accuracy 측정 산식 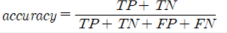
도커 이미지 docker hub, 22.3GB 실행 파일명 train_custom.py 유효성 검증 환경 CPU Intel(R) Core(TM) i7-10700K CPU @ 3.80GHz Memory 64GB 이상 GPU NVIDIA GeForce RTX 3060 이상 Storage 2TB 이상 OS Ubuntu 18.04 LTS 유효성 검증 모델 학습 및 검증 조건 개발 언어 Python 3.8.12 프레임워크 CUDA 11.3, pytorch 1.10.1+cu113 학습 알고리즘 [SE-PseudoGrid] 각각의 input point cloud data를 유사한 geometric shape으로 예측해주어 classification 진행 학습 조건 epoch: 50 batch: 8 optimizer: sgd 파일 형식 • 학습 데이터셋: csv • 평가 데이터셋: csv 전체 구축 데이터 대비 AI모델 사용 point cloud data 비율 및 수량 모델에 적용되는 비율 학습 : 검증 : 시험 = 7 : 2 : 1 = 73258 : 20925 : 10477 모델 학습 과정별 객체의 point cloud data 분류 기준 데이터 분류 및 비율 정보 - Training Set 비율 70% (73258장) - validation Set 비율 20% (20925장) - Test Set 비율 10% (10477장) 제한사항 -
데이터 성능 점수
측정값 (%)기준값 (%)데이터 성능 지표
데이터 성능 지표 번호 측정항목 AI TASK 학습모델 지표명 기준값 점수 측정값 점수 1 문화재 큐보이드 객체 분류 3D Object Classification SE-PseudoGrid Accuracy 85 % 99.1 %
※ 데이터 성능 지표가 여러 개일 경우 각 항목을 클릭하면 해당 지표의 값이 그래프에 표기됩니다.
※ AI모델 평가 지표에 따라 측정값의 범위, 판단 기준이 달라질 수 있습니다. (ex. 오류율의 경우, 낮을수록 좋은 성능을 내는 것으로 평가됩니다)
-
설명서 및 활용가이드 다운로드
데이터 설명서 다운로드 구축활용가이드 다운로드□ 데이터 포맷
구분 포맷 파일 이름 PCD las <테마>_<행정구역>_<문화재구분>_<객체>_<파일순번>.las 속성정보 json <테마>_<행정구역>_<문화재구분>_<객체>_<파일순번>.json csv <테마>_<행정구역>_<문화재구분>_<객체>_<파일순번>.csv □ 데이터 구성
ㅇ 카테고리 분류대분류(테마) 주거생활 정치국방 교육·문화 유적·유물 무덤 RE PD EC RR RM 산업생산 종교·신앙 역사 교통·통신 자연·유산 PI FO HI TC SA 중분류(행정구역) 서울특별시 경기도 강원도 5대광역시 1 2 3 4 충청도 전라도 경상도 제주 5 6 7 8 소분류(문화재 구분) 지정 문화재 비지정 문화재 1 2 세분류(객체) 문 도·토기류 탑·비 기둥 DO EA PA PI 지붕 조형물 식생 벽 RO ST VE WA ㅇ 어노테이션 포맷
- JSON구분 속성명 타입 필수여부 설명 범위 비고 1 DataSet_info object 데이터셋 정보 1-1 DataSet_ID string Y 데이터셋 명 1-2 creator string Y 구축기관명 1-3 date_created string Y 데이터 생성일자 2 Object object 파일 링크정보 2-1 object_file string Y 링크 파일명 3 categories object 카테고리 정보 3-1 cultural_heritage_category number Y 문화재 구분 정보 01월 02일 1:지정 2: 비지정 3-2 label string Y 클래스별 라벨링 정보 ST : 조형물 PA : 탑,비 EA : 도,토기류 VE : 식생 WA : 벽 DO : 문 PI : 기둥 RO : 지붕 3-3 theme string Y 테마별 정보 RE : 주거생활 PD : 정치국방 EC : 교육,문화 RR : 유적,유물 RM : 무덤 PI : 산업생산 FO : 종교,신앙 HI : 역사 TC: 교통,통신 SA : 자연,유산 4 cuboid_Annotations object 어노테이션 정보 4-1 bboxMax number Y bounding box 좌표정보 4-2 bboxMin number Y bounding box 좌표정보 - CSV
구분 속성명 타입 필수여부 설명 범위 비고 1 X number Y X축 좌표 정보 2 Y number Y Y축 좌표 정보 3 Z number Y Z축 좌표 정보 4 R number Y Red color value 0-255 5 G number Y Green color value 0-255 6 B number Y Blue color value 0-255 □ 데이터 실제 예시
ㅇ 라벨링데이터, CSV라벨링데이터 JSON데이터 


ㅇ CSV
CSV 데이터 (csv, 공간에 대한 데이터) CSV파일 
-
데이터셋 구축 담당자
수행기관(주관) : ㈜디타스
수행기관(주관) 책임자명 전화번호 대표이메일 담당업무 박준영 02-6283-0157 stream90@dtaas.co.kr 사업 총괄, 데이터 설계, 데이터 수집, 데이터 정제, 데이터 가공, 데이터 검사, 저작도구 개발, AI모델 개발, 데이터 활용 수행기관(참여)
수행기관(참여) 기관명 담당업무 ㈜엔가드 데이터 수집, 데이터 정제 ㈜리모샷 데이터 수집 지엔소프트㈜ 데이터 정제 ㈜포디비전 데이터 수집 공주대학교 산학협력단 데이터 수집, 데이터 정제, 데이터 검사 동아대학교 산학협력단 데이터 수집 제주관광대학교 산학협력단 데이터 수집 (사)한국지식서비스연구원 데이터 활용 ㈜지혜와비전 데이터 수집 데이터 관련 문의처
데이터 관련 문의처 담당자명 전화번호 이메일 박준영 02-6283-0157 stream90@dtaas.co.kr
-
인터넷과 물리적으로 분리된 온라인·오프라인 공간으로 의료 데이터를 포함하여 보안 조치가 요구되는 데이터를 다운로드 없이 접근하고 분석 가능
* 온라인 안심존 : 보안이 보장된 온라인 네트워크를 통해 집, 연구실, 사무실 등 어디서나 접속하여 데이터에 접근하고 분석
* 오프라인 안심존 : 추가적인 보안이 필요한 데이터를 대상으로 지정된 물리적 공간에서만 접속하여 데이터에 접근하고 분석 -
- AI 허브 접속
신청자 - 안심존
사용신청신청자신청서류 제출* - 심사구축기관
- 승인구축기관
- 데이터 분석 활용신청자
- 분석모델반출신청자
- AI 허브 접속
-
1. 기관생명윤리위원회(IRB) 심의 결과 통지서 [IRB 알아보기] [공용IRB 심의신청 가이드라인]
2. 기관생명윤리위원회(IRB) 승인된 연구계획서
3. 신청자 소속 증빙 서류 (재직증명서, 재학증명서, 근로계약서 등 택1)
4. 안심존 이용 신청서 [다운로드]
5. 보안서약서 [다운로드]
※ 상기 신청서 및 첨부 서류를 완비한 후 신청을 진행하셔야 정상적으로 절차가 이루어집니다. -
신청 및 이용관련 문의는 safezone1@aihub.kr 또는 02-525-7708, 7709로 문의
데이터셋 다운로드 승인이 완료 된 후 API 다운로드 서비스를 이용하실 수 있습니다.
API 다운로드 파일은 분할 압축되어 다운로드 됩니다. 분할 압축 해제를 위해서는 분할 압축 파일들의 병합이 필요하며 리눅스 명령어 사용이 필요합니다.
리눅스 OS 계열에서 다운로드 받으시길 권장하며 윈도우에서 파일 다운로드 시 wsl(리눅스용 윈도우 하위 시스템) 설치가 필요합니다.
※ 파일 병합 리눅스 명령어
find "폴더경로" -name "파일명.zip.part*" -print0 | sort -zt'.' -k2V | xargs -0 cat > "파일명.zip"
- 해당 명령어 실행 시, 실행 경로 위치에 병합 압축 파일이 생성됩니다.
- 병합된 파일 용량이 0일 경우, 제대로 병합이 되지 않은 상태이니 "폴더경로"가 제대로 입력되었는지 확인 부탁드립니다.
※ 데이터셋 소개 페이지에서 다운로드 버튼 클릭하여 승인이 필요합니다.