-
데이터 변경이력
데이터 변경이력 버전 일자 변경내용 비고 1.1 2022-01-14 데이터 추가 개방 1.0 2021-06-18 데이터 최초 개방 데이터 히스토리
데이터 히스토리 일자 변경내용 비고 2024-01-19 AI 모델 수정 도커이미지 추가 소개
상대적으로 성능 확보가 어려운 전문 분야에 대한 자연어 처리(Natural Language Processing) 학습용 말뭉치 데이터 구축
구축목적
전문분야 데이터셋을 활용한 기술 및 연관 연구 검색, 통역/번역과 특허, 의료, 행정 서비스, 법률, 조례, 금융업 등의 산업 분야 활용
-
메타데이터 구조표 데이터 영역 한국어 데이터 유형 텍스트 데이터 형식 데이터 출처 라벨링 유형 라벨링 형식 데이터 활용 서비스 데이터 구축년도/
데이터 구축량2020년/150만 건 -
구축 내용 및 제공 데이터량
- 말뭉치 학습용 데이터 셋은 아래의 기준으로 150만 건을 생성
- 학술(논문) 자료 : 초록의 문장 단위를 기준으로 함
- 법령 : 조문 기준
- 판결문 : 문장 단위이며 문장이 지나치게 길 경우 5~100개 어휘로 이루어진 문장을 한 개의 말뭉치로 생성하며 전문용어의 추출 병행
- 특허자료 : 요약문(초록) 문장단위, 청구항구축 내용 및 제공 데이터량 문서건수 말뭉치건수 개체명건수 문서당 평균 개체명 말뭉치당 평균 개체명 법령 6,356 217,592 3,358,788 528 15 판례 6,396 445,308 2,208,034 345 5 특허 71,796 780,580 9,442,396 132 12 논문 19,217 131,179 766,545 40 6 - 전문 문서 단위 말뭉치 150만 건 태깅
전문 문서 단위 말뭉치 150만 건 태깅 종류 수량 내역 특허 자료 830,000 특허 데이터를 구매하여 이를 말뭉치 원본 데이터로 활용 의안 자료 70,000 의안정보시스템을 크롤링하여 말뭉치 원본 데이터로 활용 법령, 자치법규, 행정규칙 300,000 법령 및 법령 제・개정문, 행정규칙 및 제개정문, 자치법규를 api를 사용하거나 크롤링하여 말뭉치 원본 데이터로 활용 논문 초록 300,000 논문 초록을 크롤링하여 말뭉치 원본 데이터로 활용 합계 1,500,000
- 말뭉치 학습용 데이터 셋은 아래의 기준으로 150만 건을 생성
-
-
AI 모델 상세 설명서 다운로드
AI 모델 다운로드 -
데이터 성능 점수
측정값 (%)기준값 (%)데이터 성능 지표
데이터 성능 지표 번호 측정항목 AI TASK 학습모델 지표명 기준값 점수 측정값 점수 1 전문분야 문장분류모델 유효성 Text Classification BERT F1-Score 0.9 점 0.93 점 2 개체유형 식별모델 유효성 (학술(논문)) Text Classification BERT F1-Score 0.85 점 0.9 점 3 개체유형 식별모델 유효성 (법령) Text Classification BERT F1-Score 0.85 점 0.99 점 4 개체유형 식별모델 유효성 (판례) Text Classification BERT F1-Score 0.85 점 0.99 점 5 개체유형 식별모델 유효성 (특허) Text Classification BERT F1-Score 0.85 점 0.85 점
※ 데이터 성능 지표가 여러 개일 경우 각 항목을 클릭하면 해당 지표의 값이 그래프에 표기됩니다.
※ AI모델 평가 지표에 따라 측정값의 범위, 판단 기준이 달라질 수 있습니다. (ex. 오류율의 경우, 낮을수록 좋은 성능을 내는 것으로 평가됩니다)
-
설명서 및 활용가이드 다운로드
데이터 설명서 다운로드 구축활용가이드 다운로드데이터 변경이력
데이터 변경이력 버전 일자 변경내용 비고 1.1 2022.01.14 데이터 추가 개방 1.0 2021.06.18 데이터 최초 개방 구축 목적
- 디지털 데이터의 확산과 기술의 발전으로 각 기술과 분야별 전문용어가 폭발적 증가로 상대적으로 성능 확보가 어려운 전문분야에 대한 자연어 처리(Natural Language Processing)용 말뭉치 데이터 구축
활용 분야
- 전문분야 데이터셋을 활용한 기술 및 연관 연구 검색, 통역/번역과 특허, 의료, 행정 서비스, 법률, 조례, 금융업 등의 산업 분야 활용
주요 키워드
- 한국어 텍스트, 말뭉치, 전문분야, 개체명, 개체인식
소개
- 본 과제에서 구축하는 전문문서는 학술 논문, 법령, 판례(판결문), 특허 자료 등으로 한정하며, 말뭉치 원본 데이터는 어느 정도 구조화된 체계를 갖춘 비정형 텍스트라고 할 수 있음
- 예를 들어, 특허의 경우 발명 명칭, 요약, 청구항 등과 논문의 경우 제목, 초록, 본문 등의 구분이 가능하며, 해당 구분 내에서의 비정형 텍스트를 말뭉치 대상으로 삼음
- AI를 활용한 기술 및 연관 연구 검색과 통역ㆍ번역 연구에의 활용을 위해 전문용어의 별도 식별 및 번역ㆍ통역 AI 학습을 위한 병렬 말뭉치로의 확대가 가능한 말뭉치 구조의 적용
- 전문 데이터의 분야와 문서 구분(특허, 논문, 보고서 등)에 따른 용어 구현 특성이 반영되어 분야별 학습이 가능한 말뭉치의 구축

구축 내용 및 제공 데이터량
- 말뭉치 학습용 데이터 셋은 아래의 기준으로 150만 건을 생성
- 학술(논문) 자료 : 초록의 문장 단위를 기준으로 함
- 법령 : 조문 기준
- 판결문 : 문장 단위이며 문장이 지나치게 길 경우 5~100개 어휘로 이루어진 문장을 한 개의 말뭉치로 생성하며 전문용어의 추출 병행
- 특허자료 : 요약문(초록) 문장단위, 청구항구축 내용 및 제공 데이터량 문서건수 말뭉치건수 개체명건수 문서당 평균 개체명 말뭉치당 평균 개체명 법령 6,356 217,592 3,358,788 528 15 판례 6,396 445,308 2,208,034 345 5 특허 71,796 780,580 9,442,396 132 12 논문 19,217 131,179 766,545 40 6 - 전문 문서 단위 말뭉치 150만 건 태깅
전문 문서 단위 말뭉치 150만 건 태깅 종류 수량 내역 특허 자료 830,000 특허 데이터를 구매하여 이를 말뭉치 원본 데이터로 활용 의안 자료 70,000 의안정보시스템을 크롤링하여 말뭉치 원본 데이터로 활용 법령, 자치법규, 행정규칙 300,000 법령 및 법령 제・개정문, 행정규칙 및 제개정문, 자치법규를 api를 사용하거나 크롤링하여 말뭉치 원본 데이터로 활용 논문 초록 300,000 논문 초록을 크롤링하여 말뭉치 원본 데이터로 활용 합계 1,500,000
대표도면
전문분야 말뭉치 대표도면 예시 유형 예시 데이터 항목 JSON 형식 특허
(초록/청구항)
텍스트
15가지 유형의 개체명 분류 태그 {
"1": {
"doc_type": "판례",
"doc_id": "LB88A005",
"title": "재산분할",,
"date": "2018. 6. 22.",
"reg_no": "2018스18",
"issued_by": "대법원",
"author": "",
"ipc": ""
"attr": "",
"claim_no": "",
"sentno": 3,
"text": "민법 제839조의2 제3항, 제843조에 따라 2년 제척기간 내에 재산의 일부에 대해서만 재산분할을 청구하고 제척기간이 지난 경우, 그때까지 청구 목적물로 하지 않은 재산에 대한 청구권이 소멸하는지 여부(적극)",
"NE": [
{"id": 0, "entity": "민법 제839조의2 제3항", "type": "CV", "begin": 1, "end": 14},
{"id": 1, "entity": "제843조", "type": "CV", "begin": 17, "end": 21}
{"id": 2, "entity": "2년", "type": "DT", "begin": 26, "end": 28},
{"id": 1, "entity": "제척기간", "type": "CV", "begin": 29, "end": 33},
{"id": 1, "entity": "재산분할", "type": "CV", "begin": 50, "end": 54},
{"id": 1, "entity": "제척기간", "type": "CV", "begin": 61, "end": 65},
{"id": 3, "entity": "청구권", "type": "CV", "begin": 100, "end": 103}
]
},
{
"2": {
"doc_type": "논문",
"doc_id": "ART002057337",
"title": "디지털 신호처리를 위한 고정소수점 하드웨어 설계자동화 시스템",
"date": "1996",
"reg_no": "",
"issued_by": "Telecommunications Review",
"author": "최정일; 황선영; 전홍신",
"ipc": "",
"attr": "",
"claim_no": "",
"sentno": 1,
"text": "본 논문은 디지털 신호처리용 VLSI의 자동설계를 위한 SODAS-DSP(SOgang Design Automation System-DSP) 시스템의 설계와 개발 결과에 대하여 기술한다",
"NE": [
{ "id": 1, "entity": "디지털 신호처리용 VLSI", "type": "TM", "begin": 6, "end": 20},
{ "id": 2, "entity": "자동설계", "type": "TM", "begin": 22, "end": 26},
{ "id": 3, "entity": "SODAS-DSP", "type": "TM", "begin": 31, "end": 40},
{ "id": 4, "entity": "SOgang Design Automation System-DSP", "type": "TM", "begin": 41, "end": 76}
]
}
}학술자료
텍스트
판결문
텍스트
법령정보
텍스트
메타데이터
(특허/학술/법령/판결문)
자료별 메타데이터 필요성
- 국내 AI 요약기술 개발과 관련된 다수의 연구들에서는 해당 텍스트의 제목을 본문의 요약문으로 가정하거나 뉴스 기사의 제목 혹은 첫 문장을 전체 기사의 요약문으로 가정하여 AI 요약기술을 위한 학습 데이터로 활용 중
- 이러한 조작적 정의는 본문 전체의 핵심 내용이나 의무 전달을 온전히 포함하지 못하는 한계점을 내포
- 선진국에서는 AI 요약기술 개발을 위한 다양한 문서요약 텍스트 데이터를 공개하고 있음
- 이에 한국어를 이해하고 지식을 추출하여 새로운 가치를 창출할 수 있는 문서요약 AI 기술개발을 위하여 검증된 학습용 데이터를 구축하고자 함
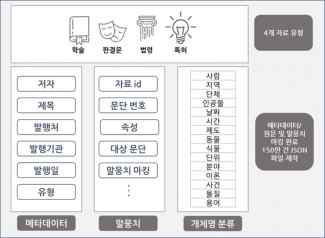
데이터 구조
- 데이터 구성
- 어노테이션 포맷
어노테이션 포맷 표 구분 요소명 예시 유형 필
수
여
부한글 영문명 메타
데이터문서종류 doc_type 학술, 특허, 법령, 판례 string Y 문서ID doc_id ART002057337 string Y 자료 제목 title 재산분할 string Y 일자 date 2018. 6. 22. string Y 등록번호 reg_no 법령공포일, 특허등록일, 논문게재연도,
판례사건번호string Y 발행자 issued_by 기계공학회(논문), 대법원(판례) string N 저자 author 최정일; 황선영 string N IPC코드 ipc B25J string N 본문 문장속성 attr 특허: 요약, 청구항
법령: 2 (제2조)string N 청구항번호 claim_no 1, 2, 3, ... int N 문장번호 sentno 1, 2, 3, ... int Y 말뭉치 본문 text 본 논문은 디지털 신호처리용 VLSI의
자동설계를 위한 SOCAS-DSP 시스템의
설계와 개발 결과에 대하여 기술한다string Y 개체명 번호 id 1, 2, 3, ... int Y 개체명 entity 자동회피방법 string Y 개체명 속성 type TM, QT (TTA개체명 태그 세트 및 태깅
말뭉치 표준 적용)string Y 개체명 시작 begin 0, 1, 2, ... int Y 개체명 종료 end 3, 10, ... int Y 개체명
분류인물 PERSON(PS) 인명 string 1개
이
상
은
반
드
시
포
함지역 LOCATION(LC) 지역, 국가, 도시, 수도, 바다 등 string 기관 단체 ORGANIZATION(OG) 경제, 교육, 군사 등의 기관 string 인공물 ARTIFACTS(AF) 문화재, 건축물, 도로, 작품명 등 string 날짜 DATE(DT) 날짜 기간, 절기, 달(월), 계절 등 string 시간 TIME(TI) 시간, 기간, 시각, 분, 초 등 string 제도 CIVILIZATION(CV) 민족, 종족, 제도, 언어, 직업 등 string 동물 ANIMAL(AM) 포유류, 조류, 파충류, 양서류 등 string 식물 PLANT(PT) 과일, 꽃, 나무, 풀 등 string 수량 QUANTITY(QT) 무게, 길이, 넓이, 개수, 온 string 학문 분야 STUDY_FIELD(FD) 철학, 의학, 예술, 사회과학 학파 string 이론 THEORY(TR) 철학 이론/사상, 예술 이론/양식 string 사건 EVENT(EV) 전쟁, 혁명, 스포츠 행사, 축제 string 물질 MATERIAL(MT) 금속, 암석, 화학물, 원소 string 용어 TERM(TM) 색, 방향, 질병, 이메일주소 string
-
데이터셋 구축 담당자
수행기관(주관) : 포티투마루
수행기관(주관) 책임자명 전화번호 대표이메일 담당업무 김동환 02-6952-9201 bd@42maru.ai · 사업 총괄 관리 수행기관(참여)
수행기관(참여) 기관명 담당업무 나라지식정보 · 데이터 정제
· 전문분야 말뭉치 라벨링(크라우드소싱 활용)
· 결과물 검수 및 검증단아코퍼레이션 · 데이터 정제
· 전문분야 말뭉치 라벨링(크라우드소싱 활용)
· 결과물 검수 및 검증이지메타 · 원문데이터 확보 및 제공
· 데이터 정제
· 전문분야 말뭉치 라벨링(크라우드소싱 활용)
· 온라인 작업도구(어노테이션 도구) 개발 및 운용유클리드소프트 · AI 요약모델 및 활용 서비스 개발
· 결과물 검수 및 검증연세대학교 산학협력단 · 품질검수 품질평가 서비스 데이터 관련 문의처
데이터 관련 문의처 담당자명 전화번호 이메일 정규상(나라지식정보) 02-3141-7644 nara@narainformation.com
-
인터넷과 물리적으로 분리된 온라인·오프라인 공간으로 의료 데이터를 포함하여 보안 조치가 요구되는 데이터를 다운로드 없이 접근하고 분석 가능
* 온라인 안심존 : 보안이 보장된 온라인 네트워크를 통해 집, 연구실, 사무실 등 어디서나 접속하여 데이터에 접근하고 분석
* 오프라인 안심존 : 추가적인 보안이 필요한 데이터를 대상으로 지정된 물리적 공간에서만 접속하여 데이터에 접근하고 분석 -
- AI 허브 접속
신청자 - 안심존
사용신청신청자신청서류 제출* - 심사구축기관
- 승인구축기관
- 데이터 분석 활용신청자
- 분석모델반출신청자
- AI 허브 접속
-
1. 기관생명윤리위원회(IRB) 심의 결과 통지서 [IRB 알아보기] [공용IRB 심의신청 가이드라인]
2. 기관생명윤리위원회(IRB) 승인된 연구계획서
3. 신청자 소속 증빙 서류 (재직증명서, 재학증명서, 근로계약서 등 택1)
4. 안심존 이용 신청서 [다운로드]
5. 보안서약서 [다운로드]
※ 상기 신청서 및 첨부 서류를 완비한 후 신청을 진행하셔야 정상적으로 절차가 이루어집니다. -
신청 및 이용관련 문의는 safezone1@aihub.kr 또는 02-525-7708, 7709로 문의
데이터셋 다운로드 승인이 완료 된 후 API 다운로드 서비스를 이용하실 수 있습니다.
API 다운로드 파일은 분할 압축되어 다운로드 됩니다. 분할 압축 해제를 위해서는 분할 압축 파일들의 병합이 필요하며 리눅스 명령어 사용이 필요합니다.
리눅스 OS 계열에서 다운로드 받으시길 권장하며 윈도우에서 파일 다운로드 시 wsl(리눅스용 윈도우 하위 시스템) 설치가 필요합니다.
※ 파일 병합 리눅스 명령어
find "폴더경로" -name "파일명.zip.part*" -print0 | sort -zt'.' -k2V | xargs -0 cat > "파일명.zip"
- 해당 명령어 실행 시, 실행 경로 위치에 병합 압축 파일이 생성됩니다.
- 병합된 파일 용량이 0일 경우, 제대로 병합이 되지 않은 상태이니 "폴더경로"가 제대로 입력되었는지 확인 부탁드립니다.
※ 데이터셋 소개 페이지에서 다운로드 버튼 클릭하여 승인이 필요합니다.