-
데이터 변경이력
데이터 변경이력 버전 일자 변경내용 비고 1.1 2023-12-15 데이터 최종 개방 1.0 2023-07-31 데이터 개방(Beta Version) 데이터 히스토리
데이터 히스토리 일자 변경내용 비고 2024-03-20 저작도구 설명서 추가 저작도구 서버구축가이드 추가 2024-02-29 산출물 전체 공개 소개
상품 리뷰데이터에 포함된 사용자 감정을 태깅한 데이터로 총 25만건 가량의 데이터셋을 구축
구축목적
상품에 대한 사용자의 선호도 및 감정 속성을 제공하여 보다 심층적인 비즈니스 인사이트를 제공하고자 함
-
메타데이터 구조표 데이터 영역 한국어 데이터 유형 텍스트 데이터 형식 txt 데이터 출처 쇼핑몰, SNS 라벨링 유형 속성추출(텍스트) 라벨링 형식 JSON 데이터 활용 서비스 커머스분야 (상품 추천 서비스) 데이터 구축년도/
데이터 구축량2022년/250,312건 -
데이터 통계
1. 데이터 구축 규모
1-1. 쇼핑몰 리뷰 데이터
데이터 소스 도메인 카테고리 데이터 형태 결과물 규모 쇼핑몰 리뷰 데이터 패션 여성의류 JSON, 텍스트 19,477 남성의류 10,001 패션슈즈 11,589 잡화 3,929 화장품 스킨케어 15,001 헤어/바디케어 14,000 메이크업/뷰티소품 12,196 남성화장품 3,799 가전 영상/음향가전 7,499 생활/미용/욕실가전 12,654 주방가전 12,600 계절가전 12,502 IT기기 컴퓨터/주변기기 15,007 휴대폰/주변기기 12,518 카메라/게임기/태블릿 7,529 자동차기기 10,003 생활 세제/세정/탈취제 16,279 주방용품 8,139 위생용품 15,079 청소/세탁용품 5,499 총 수량 225,300 1-2. SNS 리뷰 데이터
데이터 소스 도메인 데이터 형태 결과물 규모 SNS 리뷰 데이터 패션 JSON, 텍스트 5,000 화장품 5,000 가전 5,008 IT기기 5,004 생활 5,000 총 수량 25,012 2. 데이터 분포
2.1 데이터 소스별 분포
데이터 소스 데이터 건수 비율 쇼핑몰 리뷰 데이터 225,300 90% SNS 리뷰 데이터 25,012 10% 합계 250,312 100% 2.2 카테고리별 분포
도메인 카테고리 데이터 수량 비율 패션 여성의류 20,985 8% 남성의류 10,991 4% 패션슈즈 12,981 5% 잡화 5,039 2% 화장품 스킨케어 16,341 7% 헤어/바디케어 15,420 6% 메이크업/뷰티소품 13,485 5% 남성화장품 4,750 2% 가전 영상/음향가전 8,749 3% 생활/미용/욕실가전 13,912 6% 주방가전 13,850 6% 계절가전 13,752 5% IT기기 컴퓨터/주변기기 16,507 7% 휴대폰/주변기기 14,018 6% 카메라/게임기/태블릿 8,782 4% 자동차기기 10,754 4% 생활 세제/세정/탈취제 17,225 7% 주방용품 9,293 4% 위생용품 16,846 7% 청소/세탁용품 6,632 3% 합계 250,312 100% -
-
AI 모델 상세 설명서 다운로드
AI 모델 상세 설명서 다운로드 AI 모델 다운로드1. Model Description
• Token마다 label을 태깅하는 Token classification 모델이다.
• Sentiment와 Aspect category 속성을 span 단위로 태깅한 데이터를 사용하여 학습하였다.
• 문장의 embedding 결과와 (Token embeddings, Segment Embeddings, Position Embeddings) Label Encoder를 통해 인코딩된 Target Sentiment 및 Target Aspect를 입력으로 받고, 예측된 Sentiment와 Aspect 속성을 반환한다.
• 과적합을 방지하기 위하여, Adamw optimizer와 Earlystopping이 적용되었다.(자세한 설명은 5.Training 요소 참조)
• 속성 카테고리를 대분류 속성으로 변환하여, 대분류 속성 기준으로 성능을 측정한다.
2. Model Architecture
• Sentiment와 Aspect Category 학습/예측에 동일한 BERT (klue-bert)가 사용된다.
• Sentiment와 Aspect Category가 각각 별개의 Dropout Layer와 Linear Layer, CRF Layer를 갖는다.
• 각 속성의 loss는 NLL(Negative Log Likelihood) Loss로 계산하며,
• 최종 loss는 두 속성 loss의 평균을 계산하여 얻는 joint training 방식의 모델 구조이다.3. DATA
3-1. 원본 데이터 (json)
일반적인 속성 기반 감성 분석의 벤치마크 데이터셋은 Aspect가 단어 형태이지만, 현 과제의 특성상 속성 단어가 없는 경우(암시적 속성)가 많아 Sentiment와 Aspect가 span 단위로 태깅되어 있다.3-2. Input
3-2-1. 학습 데이터 (csv)
label이 태깅된 span을 예측하기 위하여, 개체명 인식 등의 Token classification task에서 주로 사용되는 BIO tag를 활용해 원본 데이터를 파싱하였다.
B는 Begin의 약자로 span이 시작되는 부분, I는 Inside의 약자로 span의 내부 부분을 의미하며, O는 Outside의 약자로 span이 아닌 부분을 의미한다.3-2-2. 모델 Input
input 요소 설명 차원 ids token들의 id 리스트 (tensor) (batch_size, max_length) (sequence of token id) mask attention 연산이 수행되어야 할 token과 무시해야 할 token을 구별하는 정보가 담긴 리스트 (tensor) (batch_size, max_length) 일반적인 token에는 1을 부여하고, padding과 같이 attention 연산이 수행될 필요가 없는 token들에는 0을 부여 token_type_ids 각 token이 어떤 문장에 속하는지를 나타내는 리스트. (tensor) (batch_size, max_length) BERT는 한 번에 두 문장(sentence A, sentence B)을 입력으로 받을 수 있는데, sentence A에 속하는 token에는 0을, sentence B에 속하는 token에는 1을 부여 target_aspect 타겟이 되는 속성별 감성 (tensor) (batch_size, max_length) target_sentiment 타겟이 되는 속성 카테고리 (tensor) (batch_size, max_length) 3-3. Output
모델의 1) loss 값과 2) 속성별 감성 분석 결과 및 3) 속성 카테고리 예측 결과를 반환한다.output 요소 설명 차원 loss 모델의 loss value (tensor) 1차원의 tensor predicted_sentiment 모델의 속성별 감성 분석 결과 (tensor) (batch_size, max_length) predicted_aspect 모델의 속성 카테고리 예측 결과 (tensor) (batch_size, max_length) 4. Task
토큰 분류(Token classification)
• 각 토큰이 문장 내에서 어떠한 역할을 지니고 있는지 예측하는 task이다.
• 본 과제에서의 ‘역할’은 Sentiment와 Aspect Category 속성을 의미한다.
5. Training 요소
5-1. 모델 구성 요소
5-1-1. Optimizer (Adamw)
Adam 최적화 기법은 일차 및 이차 모수의 동적 측정에 기반하여 이루어진다. 계산이 효율적이며, 메모리 사용량이 적고 gradient의 대각 스케일링에 영향을 받지 않는다. 따라서 데이터나 파라미터가 많은 큰 스케일의 문제에 효과적이다.
현 모델에서 사용한 Adamw optimizer는 이러한 Adam 알고리즘 최적화를 수행하면서 변수를 업데이트할 때, 가중치의 증가를 제한하는 기법이다. 큰 gradient를 가진 변수들을 표준화하기 때문에, 훈련 비용과 일반화 에러를 더 작게 줄일 수 있다.
5-1-2. Loss Function (Negative Log-Likelihood Loss)
공유된 모델에선 손실 함수로 Negative Log-Likelihood (NLL; 음의 로그우도) Loss를 사용하였다.
NLL Loss는 input data를 두 개 이상의 클래스 중 하나로 매핑하는 분류 문제에서 유용한 손실 함수로 수식은 아래와 같다.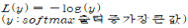
정답 클래스의 softmax의 출력이 높은 값을 가진다면 출력이 정확함을 뜻하므로, 결과가 매우 작아지며 softmax의 출력이 낮다면 결과는 큰 값을 갖게 된다.
즉, 출력이 정확하지 않은 부분에 대해서는 높은 Loss를 가지는 것처럼 나타낼 수 있다.최종 Loss는 softmax를 취하고 나온 모든 logit에 대해 loss를 구하여, 평균을 내는 방법으로 계산된다. 이때 정답에 해당하는 클래스의 loss를 계산할 때는 를 취하고, 정답이 아닌 클래스일 때는를 취하여 계산한다. (a: 기준이 되는 logit)
정답이 아닌 클래스의 경우, a의 값이 0에 가까워 높은 loss를 갖는다.5-1-3. EarlyStopping
과적합이 되는 모델의 경우, epoch이 커질수록 Loss가 감소하다가 다시 증가하는 양상을 보인다. EarlyStopping은 이를 방지하기 위하여 모델이 더 이상 개선의 여지가 없을 때, 학습을 강제 종료시키는 방법이다.
학습 조기 종료를 위해 관찰할 항목(monitor)과 개선이 없을 때 몇 번째 epoch(patience)까지 기다릴지를 설정할 수 있다. 공유된 최종 모델에선 monitor를 val_loss(검증셋의 loss)로, patience를 3으로 설정하였다.
5-2. 하이퍼파라미터Parameter명 설정값 설명 epochs 5 데이터셋을 학습할 횟수 batch_size 8 한 batch에 속할 데이터 샘플의 size sentiment_drop_ratio 0.3 Sentiment 속성의 과적합 방지를 위해 dropout을 수행할 비율 aspect_drop_ratio 0.3 Aspect 속성의 과적합 방지를 위해 dropout을 수행할 비율 sentiment_in_feature 768 각 Sentiment input sample의 size aspect_in_feature 768 각 Asepct input sample의 size stop_patience 3 validation loss를 기준으로 성능이 증가하지 않는 epoch을 몇 번이나 허용할 것인지 설정 (Earlystopping 목적) learning_rate 1e-3 한 번 학습할 때의 학습량 -
데이터 성능 점수
측정값 (%)기준값 (%)데이터 성능 지표
데이터 성능 지표 번호 측정항목 AI TASK 학습모델 지표명 기준값 점수 측정값 점수 1 속성 분류 모델 성능 Text Classification BERT F1-Score 0.8 점 0.8018 점 2 감정 분석 모델 성능 Text Classification BERT F1-Score 0.8 점 0.8414 점
※ 데이터 성능 지표가 여러 개일 경우 각 항목을 클릭하면 해당 지표의 값이 그래프에 표기됩니다.
※ AI모델 평가 지표에 따라 측정값의 범위, 판단 기준이 달라질 수 있습니다. (ex. 오류율의 경우, 낮을수록 좋은 성능을 내는 것으로 평가됩니다)
-
설명서 및 활용가이드 다운로드
데이터 설명서 다운로드 구축활용가이드 다운로드데이터 포맷
데이터 포맷 예시
유형 쇼핑몰 리뷰데이터 도메인 패션 카테고리 여성의류 원문 상품평 편하고 디자인이 예쁘네요. 가격도 좋고 시원해요. 빨리 마르고 이것만 입게 돼요 데이터 전처리 후 속성 속성 문장 극성(상품에 대한 감정) 착용감 편하고 1 (긍정) 디자인 디자인이 예쁘네요. 1 (긍정) 가격 가격도 좋고 1 (긍정) 기능 시원해요 1 (긍정) 소재 빨리 마르고 1 (긍정) 활용성 이것만 입게돼요 1 (긍정) 데이터 구성
KEY Description Type Index 구분ID String RawText 리뷰데이터 소스 정보 String Sourse 수정 상품평 String Domain 상품에 대한 도메인 String MainCategory 해당상품이 속해있는 카테고리 String ProductName 리뷰 대상의 일반적인 상품명 String ReviewScore 상품평 스코어 String Syllable 상품평 음절수 String Word 상품평 어절수 String RDate 데이터 생성일자 String GeneralPolarity 상품평 전체 감정 극성 String Aspect 속성어 String SentimentText 속성어에 대한 감정표현 String SentimentWord 속성어 어절수 String SentimentPolarity 속성어 감정표현부의 감정극성 String 어노테이션 포맷
No 항목 타입 필수여부 한글명 영문명 1 아이디 Index String Y 2 상품평 RawText String Y 3 데이터 소스 Source String Y 4 도메인 Domain String Y 5 상품 카테고리 MainCategory String Y 6 상품명 ProductName String Y 7 점수 ReviewScore String N 8 음절 Syllable String Y 9 어절 Word String Y 10 일자 RDate String Y 11 극성 GeneralPolarity String Y 12 속성어 Aspect String Y 13 감정표현 SentimentText String Y 14 어절 SentimentWord String Y 15 극성 SentimentPolarity String Y 실제 예시
[
{ "Index": "15",
"RawText": "편하고 디자인이 예뻐요 가격도 좋아요 시원해요 빨리 마르고 이것만 입게되요",
"Source": "쇼핑몰",
"Domain": "패션",
"MainCategory": "여성의류",
"ProductName": "OO 플** 베스트 풀코디 3종",
"ReviewScore": "100",
"Syllable": "49",
"Word": "10",
"RDate": "20210804",
"GeneralPolarity": "1",
"Aspects": [
{
"Aspect": "착용감",
"SentimentText": "편하고",
"SentimentWord": "1",
"SentimentPolarity": "1"
},
{
"Aspect": "디자인",
"SentimentText": "디자인이 예뻐요",
"SentimentWord": "2",
"SentimentPolarity": "1"
},
{
"Aspect": "가격",
"SentimentText": "가격도 좋아요",
"SentimentWord": "2",
"SentimentPolarity": "1"
},
{
"Aspect": "기능",
"SentimentText": "시원해요",
"SentimentWord": "1",
"SentimentPolarity": "1"
},
{
"Aspect": "소재",
"SentimentText": "빨리 마르고",
"SentimentWord": "2",
"SentimentPolarity": "1"
},
{
"Aspect": "활용성",
"SentimentText": "이것만 입게되요",
"SentimentWord": "2",
"SentimentPolarity": "1"
}
]
}
] -
데이터셋 구축 담당자
수행기관(주관) : 케이티디에스 (구 알파디엑스솔루션)
수행기관(주관) 책임자명 전화번호 대표이메일 담당업무 지민호 02-523-7029 mino.ji@kt.com 데이터 구축 총괄 수행기관(참여)
수행기관(참여) 기관명 담당업무 피플앤드테크놀러지 데이터 구축 나라지식정보 데이터 구축 와이즈넛 AI모델링 한국외국어대학교 연구산학협력단 데이터 검수 데이터 관련 문의처
데이터 관련 문의처 담당자명 전화번호 이메일 지민호 02-523-7029 mino.ji@kt.com
-
인터넷과 물리적으로 분리된 온라인·오프라인 공간으로 의료 데이터를 포함하여 보안 조치가 요구되는 데이터를 다운로드 없이 접근하고 분석 가능
* 온라인 안심존 : 보안이 보장된 온라인 네트워크를 통해 집, 연구실, 사무실 등 어디서나 접속하여 데이터에 접근하고 분석
* 오프라인 안심존 : 추가적인 보안이 필요한 데이터를 대상으로 지정된 물리적 공간에서만 접속하여 데이터에 접근하고 분석 -
- AI 허브 접속
신청자 - 안심존
사용신청신청자신청서류 제출* - 심사구축기관
- 승인구축기관
- 데이터 분석 활용신청자
- 분석모델반출신청자
- AI 허브 접속
-
1. 기관생명윤리위원회(IRB) 심의 결과 통지서 [IRB 알아보기]
2. 기관생명윤리위원회(IRB) 승인된 연구계획서
3. 신청자 소속 증빙 서류 (재직증명서, 재학증명서, 근로계약서 등 택1)
4. 안심존 이용 신청서 [다운로드]
5. 보안서약서 [다운로드]
※ 상기 신청서 및 첨부 서류를 완비한 후 신청을 진행하셔야 정상적으로 절차가 이루어집니다. -
신청 및 이용관련 문의는 safezone1@aihub.kr 또는 02-525-7708, 7709로 문의
데이터셋 다운로드 승인이 완료 된 후 API 다운로드 서비스를 이용하실 수 있습니다.
API 다운로드 파일은 분할 압축되어 다운로드 됩니다. 분할 압축 해제를 위해서는 분할 압축 파일들의 병합이 필요하며 리눅스 명령어 사용이 필요합니다.
리눅스 OS 계열에서 다운로드 받으시길 권장하며 윈도우에서 파일 다운로드 시 wsl(리눅스용 윈도우 하위 시스템) 설치가 필요합니다.
※ 파일 병합 리눅스 명령어
find "폴더경로" -name "파일명.zip.part*" -print0 | sort -zt'.' -k2V | xargs -0 cat > "파일명.zip"
- 해당 명령어 실행 시, 실행 경로 위치에 병합 압축 파일이 생성됩니다.
- 병합된 파일 용량이 0일 경우, 제대로 병합이 되지 않은 상태이니 "폴더경로"가 제대로 입력되었는지 확인 부탁드립니다.
※ 데이터셋 소개 페이지에서 다운로드 버튼 클릭하여 승인이 필요합니다.