음성 및 모션 합성 데이터
- 분야한국어
- 유형 오디오 , 비디오 , 텍스트
-
데이터 변경이력
데이터 변경이력 버전 일자 변경내용 비고 1.0 2022-07-12 데이터 최초 개방 데이터 히스토리
데이터 히스토리 일자 변경내용 비고 2022-10-13 신규 샘플데이터 개방 2022-07-12 콘텐츠 최초 등록 소개
한국어 발화 기반 동작 생성 기술을 위한 음성 모션이 동기화된 멀티모달 데이터셋 4,070시간 구축 및 공개
구축목적
음성, 행동, 감정을 통합적으로 합성하기 위해 필요한 멀티 모달 데이터셋(발화 음성, 모션 영상, 텍스트) 구축
-
메타데이터 구조표 데이터 영역 한국어 데이터 유형 오디오 , 비디오 , 텍스트 데이터 형식 mp4, wav, bvh, c3d 데이터 출처 자체 수집 라벨링 유형 json 라벨링 형식 텍스트, 모션캡쳐 데이터 활용 서비스 인공지능 아바타 서비스, 버츄얼 유튜버 등 데이터 구축년도/
데이터 구축량2021년/원천데이터(영상) 4,070시간, 원천데이터(음성) 1,017시간, 라벨링데이터(json) 8,524건 -
1. 데이터 구축 규모
1. 데이터 구축 규모 데이터 종류 데이터 형태 데이터 규모 원천데이터 – 영상 mp4 4,070 시간 원천데이터 - 음성 wav 1,017 시간 라벨링데이터 – 텍스트 json 8,524 건
2 데이터 분포
- 촬영 상황 및 발화 타입별 분포
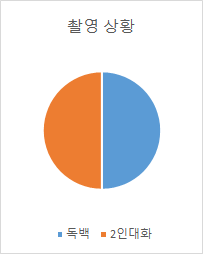
촬영 상황 및 발화 타입별 분포 촬영 상황 구축량
(시간/영상 기준)비율 독백 2,017 50% 2인대화 2,053 50% 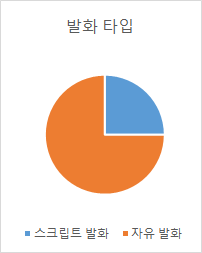
촬영 상황 및 발화 타입별 분포 발화 타입 구축량
(시간/영상 기준)비율 스크립트 발화 1,050 25% 자유 발화 3,020 75%
- 성별 분포
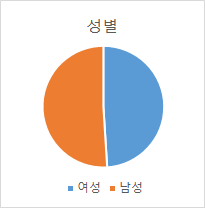
성별 분포 성별 인원 (명) 비율 여성 237 49% 남성 249 51%
- 발화자 특성별 분포
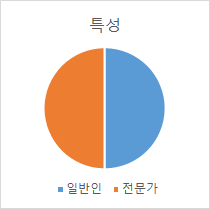
발화자 특성별 분포 특성 인원 (명) 비율 일반인 246 50% 전문가 240 50%
- 연령대별 분포
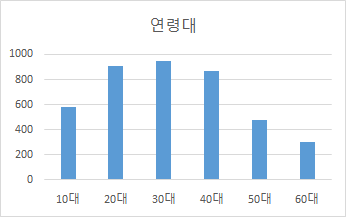
연령대별 분포 연령대 구축량 비율 (시간/영상 기준) 10대 579 14% 20대 904 22% 30대 944 23% 40대 867 21% 50대 475 12% 60대 301 7%
- 주제별 분포
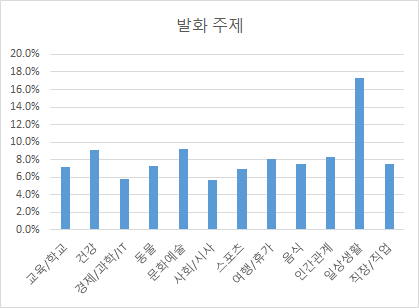
주제별 분포 발화 주제 구축량 (시간) 비율 교육/학교 294 7.2% 건강 370 9.1% 경제/과학/IT 237 5.8% 동물 297 7.3% 문화예술 374 9.2% 사회/시사 231 5.7% 스포츠 281 6.9% 여행/휴가 331 8.1% 음식 307 7.5% 인간관계 340 8.3% 일상생활 704 17.3% 직장/직업 305 7.5%
- 감정별 분포
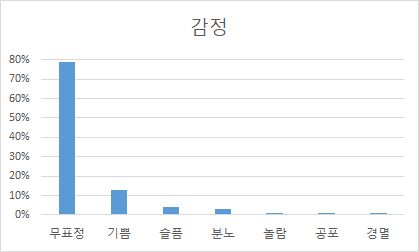
감정별 분포 감정 구축량 (시간) 비율 무표정 3,199 79% 기쁨 517 13% 슬픔 164 4% 분노 102 3% 놀람 42 1% 공포 23 1% 경멸 22 1%
- 카메라 각도별 분포
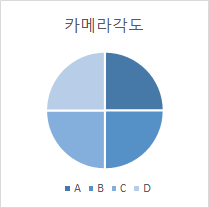
카메라 각도별 분포 카메라각도 구축량 (시간) 비율 A 1,018 25% B 1,018 25% C 1,018 25% D 1,018 25%
- 촬영 상황 및 발화 타입별 분포
-
-
AI 모델 상세 설명서 다운로드
AI 모델 상세 설명서 다운로드 AI 모델 다운로드1. 모델 학습
- 학습 모델 연구
- 음성 기반 행동 생성분야 알고리즘은 음성 데이터와 행동 데이터의 관계성을 표현하는 연구 분야
- 딥러닝 방식 전에는 규칙 기반으로 특정 음성에 사상되는 행동을 나열하는 방식으로 접근
- 2017년 Human Agent Interaction 학회에 딥러닝을 활용한 음성 기반 행동 생성 모델이 처음으로 발표
- 이후, 음성 데이터의 특성을 특정 공간에 표현하고(표현 학습, representation learning) 이것을 바탕으로 행동 데이터를 확률적으로 생성하는 생성 모델의 연구방식이 주류를 이룸
- 음성 데이터와 행동 데이터는 시퀀스 데이터로 각 데이터의 특성을 만들기 위해 RNN 계열 네트워크 혹은 1D convolution 계열의 네트워크가 주로 활용
- 모델 설계
- 해당 알고리즘은 2019년 Intelligent Virtual Agents 학회에서 발표된 Analyzing Input and output Representations for Speech-Driven Gesture Generation 논문에서 제시된 모델
- 제시하는 모델은 음성(Audio)에서 시작해 모션 데이터 표현 정보(Representation) 그리고 행동(Pose)의 과정을 거치기에 ARP라고 부름
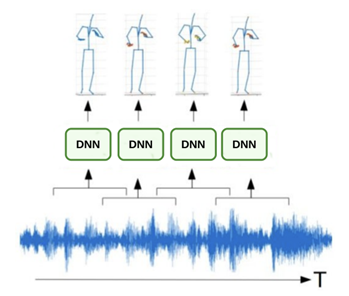
[음성 데이터를 네트워크의 입력으로 활용하고 출력으로 행동이 생성]- ARP는 입력으로 3초가량의 음성의 MFCC값을 활용하고 출력으로 행동 관절 키포인트의 x, y, z 3축 좌표를 생성
- ARP는 음성을 표현 벡터(representation vector)로 변경하는 SpeechE 모듈과 표현 벡터를 다시 행동으로 변경하는 MotionD 모듈로 구성
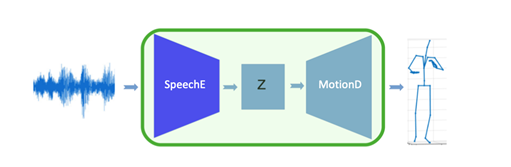
[SpeechE와 MotionD 네트워크를 통합해 전체 네트워크 생성]
- 모델 개발
- ARP 알고리즘은 SpeechE와 MotionD를 각각 학습
- 단층 Denoising AutoEncoder를 활용하여 행동이 들어가서 다시 행동이 생성되는 행동 재건 네트워크를 학습하고 행동 생성 모듈인 MotionD를 전체 네트워크에 사용
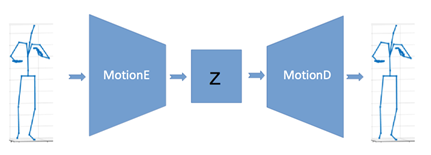
[행동 재건 학습 네트워크의 구조 학습된 MotionD 모듈은 전체 네트워크에 사용]- 입력으로 사용하는 음성을 모션 재건 네트워크 중간의 행동 표현 벡터(representation vector)로 사상시키는 네트워크 SpeechE를 학습시키고 이것을 전체 네트워크에 사용
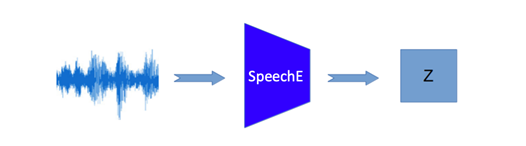
[음성을 행동 표현 벡터로 학습하는 네트워크 구조 학습된 SpeechE 모듈은 전체 네트워크에 사용]
2. 서비스 활용 시나리오
- 스피치 기반 캐릭터 애니메이션을 이용한 서비스 (인공지능 아나운서, 인공지능 강사)
- 사람의 스피치 스타일과 모션 정보 간 관계를 분석하고 인공지능 생성 모델을 구축, 이를 캐릭터 모션에 적용 가능
- 인공지능 아나운서, 인공지능 강사, 인공지능 안내자와 같이 사람과 상호작용하며 정보를 전달하는 서비스의 경우 필요한 대사 및 음성 정보로 캐릭터가 음성 스타일에 적합한 애니메이션을 자동으로 생성할 수 있음
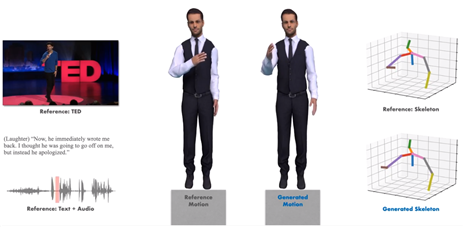
- 학습 모델 연구
-
데이터 성능 점수
측정값 (%)기준값 (%)데이터 성능 지표
데이터 성능 지표 번호 측정항목 AI TASK 학습모델 지표명 기준값 점수 측정값 점수 1 모션 생성 평가(GENEA 데이터와 비교) Image Generation Audio-Representation-Pose (ARP) Likert scale 3.95 점 3.97 점
※ 데이터 성능 지표가 여러 개일 경우 각 항목을 클릭하면 해당 지표의 값이 그래프에 표기됩니다.
※ AI모델 평가 지표에 따라 측정값의 범위, 판단 기준이 달라질 수 있습니다. (ex. 오류율의 경우, 낮을수록 좋은 성능을 내는 것으로 평가됩니다)
-
설명서 및 활용가이드 다운로드
데이터 설명서 다운로드 구축활용가이드 다운로드1. 데이터셋 구성

2. 라벨링데이터 구성
1. 데이터셋 구성 번호 항목 타입 필수여부 영문명 한글명 1 info 메타정보 object Y 1-1 Audio_info 오디오 정보 object Y 1-1-1 audio_duration 오디오 길이 number Y 1-1-2 audio_format 오디오 포맷 string Y 1-1-3 audio_name 오디오 파일명 array of string Y 1-1-4 channel 오디오 채널 수 number Y 1-1-5 sampling_rate 오디오 샘플링레이트 string Y 1-2 Dataset 데이터셋 object Y 1-2-1 URL 데이터셋 url string Y 1-2-2 description 데이터 정보 string Y 1-2-3 version 데이터 버전 number Y 1-3 Video_info 비디오 정보 object Y 1-3-1 FPS 프레임 number Y 1-3-2 extrinsic 외부카메라 계수 object Y 1-3-2-1 A 1번카메라 계수 array(2d) Y 1-3-2-2 B 2번카메라 계수 array(2d) Y 1-3-2-3 C 3번카메라 계수 array(2d) Y 1-3-2-4 D 4번카메라 계수 array(2d) Y 1-3-3 intrinsic 내부카메라 계수 object Y 1-3-3-1 A 1번카메라 계수 array(2d) Y 1-3-3-2 B 2번카메라 계수 array(2d) Y 1-3-3-3 C 3번카메라 계수 array(2d) Y 1-3-3-4 D 4번카메라 계수 array(2d) Y 1-3-4 resolution 해상도 array of number Y 1-3-5 video_duration 영상 길이 number Y 1-3-6 video_format 영상 포맷 string Y 1-3-7 video_name 영상 파일명 object Y 1-3-7-1 A 1번영상파일명 string Y 1-3-7-2 B 2번영상파일명 string Y 1-3-7-3 C 3번영상파일명 string Y 1-3-7-4 D 4번영상파일명 string Y 2 motion 모션정보 object Y 2-1 keypoints 키포인트 object Y 2-1-1 keypoints_2d 2D 키포인트 object Y 2-1-1-1 A 1번 카메라 array Y 2-1-1-1-1 body 2D 바디 조인트 좌표 array Y 2-1-1-1-2 face 2D 얼굴 마커 좌표 array Y 2-1-1-1-3 speaker_ID 발화자일련번호 string Y 2-1-1-2 B 2번 카메라 array Y 2-1-1-2-1 body 2D 바디 조인트 좌표 array Y 2-1-1-2-2 face 2D 얼굴 마커 좌표 array Y 2-1-1-2-3 speaker_ID 발화자일련번호 string Y 2-1-1-3 C 3번 카메라 array Y 2-1-1-3-1 body 2D 바디 조인트 좌표 array Y 2-1-1-3-2 face 2D 얼굴 마커 좌표 array Y 2-1-1-3-3 speaker_ID 발화자일련번호 string Y 2-1-1-4 D 4번 카메라 array Y 2-1-1-4-1 body 2D 바디 조인트 좌표 array Y 2-1-1-4-2 face 2D 얼굴 마커 좌표 array Y 2-1-1-4-3 speaker_ID 발화자일련번호 string Y 2-1-2 keypoints_3d 3차원 키포인트 array Y 2-1-2-1 body 3D 바디 조인트 좌표 array of number Y 2-1-2-2 face 3D 얼굴 마커 좌표 array of number Y 2-1-2-3 speaker_ID 발화자일련번호 string Y 2-2 keypoints_info 키포인트 정보 object Y 2-2-1 body 바디조인트이름 array of string Y 2-2-2 face 얼굴조인트이름 array of string Y 3 Transcript 전사정보 object Y 3-1 Sentences 발화 문장 정보 array Y 3-1-1 emotion 감정 정보 string Y 3-1-2 end_time 발화 종료 시간 number Y 3-1-3 sentence_text 발화 문장 string Y 3-1-4 speaker_ID 발화자일련번호 string Y 3-1-5 start_time 발화 시작 시간 number Y 3-2 Speaker_info 발화자 정보 array Y 3-2-1 Accent 표준어 여부 string Y 3-2-2 Age 연령대 string Y 3-2-3 Gender 성별 string Y 3-2-4 Specificity 전문성 여부 string Y 3-2-5 speaker_ID 발화자일련번호 string Y 3-3 Transcript_info 전사 문장 정보 object Y 3-3-1 sentence_count 총 문장 수 number Y 3-3-2 subject 발화 주제 string Y 3-3-3 type 발화 타입 string Y 3. 라벨링데이터 실제예시
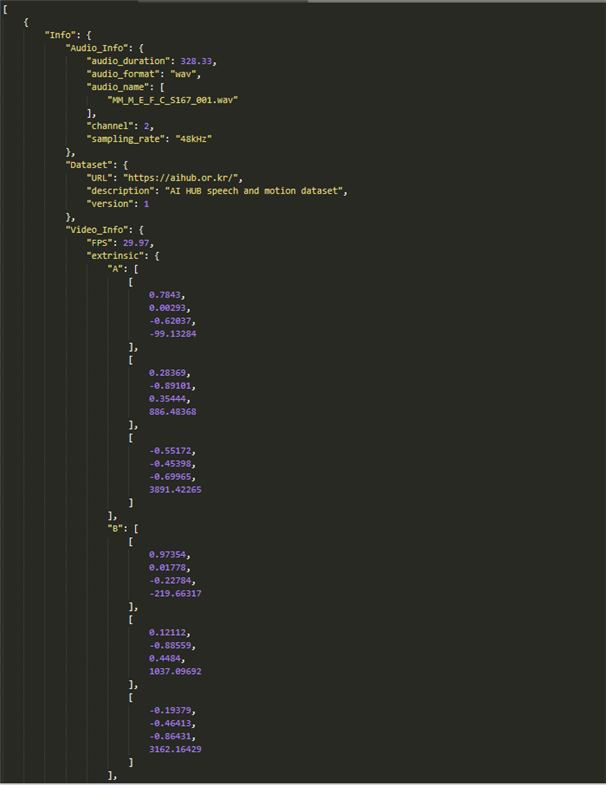
-
데이터셋 구축 담당자
수행기관(주관) : ㈜마인즈랩
수행기관(주관) 책임자명 전화번호 대표이메일 담당업무 송혜원 031-625-4349 pworks@mindslab.ai · 데이터 품질 관리 수행기관(참여)
수행기관(참여) 기관명 담당업무 ㈜인공지능연구원 · 데이터 수집, 정제, 가공 및 학습 모델 개발 ㈜이엠피이모션캡쳐 · 데이터 수집, 정제 ㈜크라우드웍스 · 데이터 가공 데이터 관련 문의처
데이터 관련 문의처 담당자명 전화번호 이메일 송혜원 031-625-4349 pworks@mindslab.ai
-
인터넷과 물리적으로 분리된 온라인·오프라인 공간으로 의료 데이터를 포함하여 보안 조치가 요구되는 데이터를 다운로드 없이 접근하고 분석 가능
* 온라인 안심존 : 보안이 보장된 온라인 네트워크를 통해 집, 연구실, 사무실 등 어디서나 접속하여 데이터에 접근하고 분석
* 오프라인 안심존 : 추가적인 보안이 필요한 데이터를 대상으로 지정된 물리적 공간에서만 접속하여 데이터에 접근하고 분석 -
- AI 허브 접속
신청자 - 안심존
사용신청신청자신청서류 제출* - 심사구축기관
- 승인구축기관
- 데이터 분석 활용신청자
- 분석모델반출신청자
- AI 허브 접속
-
1. 기관생명윤리위원회(IRB) 심의 결과 통지서 [IRB 알아보기] [공용IRB 심의신청 가이드라인]
2. 기관생명윤리위원회(IRB) 승인된 연구계획서
3. 신청자 소속 증빙 서류 (재직증명서, 재학증명서, 근로계약서 등 택1)
4. 안심존 이용 신청서 [다운로드]
5. 보안서약서 [다운로드]
※ 상기 신청서 및 첨부 서류를 완비한 후 신청을 진행하셔야 정상적으로 절차가 이루어집니다. -
신청 및 이용관련 문의는 safezone1@aihub.kr 또는 02-525-7708, 7709로 문의
데이터셋 다운로드 승인이 완료 된 후 API 다운로드 서비스를 이용하실 수 있습니다.
API 다운로드 파일은 분할 압축되어 다운로드 됩니다. 분할 압축 해제를 위해서는 분할 압축 파일들의 병합이 필요하며 리눅스 명령어 사용이 필요합니다.
리눅스 OS 계열에서 다운로드 받으시길 권장하며 윈도우에서 파일 다운로드 시 wsl(리눅스용 윈도우 하위 시스템) 설치가 필요합니다.
※ 파일 병합 리눅스 명령어
find "폴더경로" -name "파일명.zip.part*" -print0 | sort -zt'.' -k2V | xargs -0 cat > "파일명.zip"
- 해당 명령어 실행 시, 실행 경로 위치에 병합 압축 파일이 생성됩니다.
- 병합된 파일 용량이 0일 경우, 제대로 병합이 되지 않은 상태이니 "폴더경로"가 제대로 입력되었는지 확인 부탁드립니다.
※ 데이터셋 소개 페이지에서 다운로드 버튼 클릭하여 승인이 필요합니다.