-
데이터 변경이력
데이터 변경이력 버전 일자 변경내용 비고 1.0 2022-07-12 데이터 최초 개방 데이터 히스토리
데이터 히스토리 일자 변경내용 비고 2025-05-08 구축업체정보 수정 2023-09-20 저작도구 수정 2022-10-04 AI 모델 업데이트 2022-07-12 콘텐츠 최초 등록 소개
다양한 한국어 원문 데이터로부터 정제된 추출 및 생성 요약문을 도출하고 검증한 한국어 문서요약 AI 데이터셋으로, 추출요약을 포함하여 본문에서 중요한 문장을 하나의 새로운 요약문으로 창조하는 생성요약(Abstractive Summarization)을 위한 데이터 세트를 구축하고 이를 실제 모델에 학습
구축목적
다양한 문서유형의 한국어 원문으로부터 추출요약문과 생성요약문을 도출해낼 수 있도록 인공지능을 훈련하기 위한 데이터셋
-
메타데이터 구조표 데이터 영역 한국어 데이터 유형 텍스트 데이터 형식 txt 데이터 출처 신문, 보도자료, 간행물, 문학, 연설문 등 라벨링 유형 내용요약(자연어) 라벨링 형식 JSON 데이터 활용 서비스 문서요약서비스, 주요문장추출서비스 등 데이터 구축년도/
데이터 구축량2021년/201,671 -
1. 데이터 구축 규모
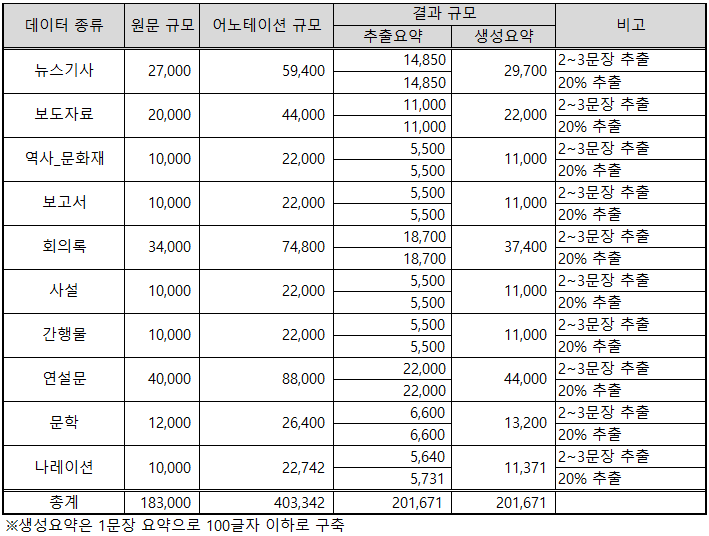
2. 데이터 분포
2.1 문서 유형 및 문서 종류별 분포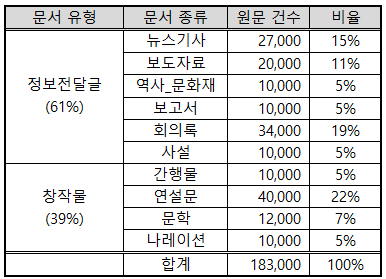
2.2 추출요약 길이별 분포
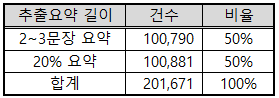
-
-
AI 모델 상세 설명서 다운로드
AI 모델 상세 설명서 다운로드 AI 모델 다운로드학습모델 설계 / 개발
1) 사전학습 언어모델(Pretrained Language Model) 기반의 요약 모델
- 자연어 처리 태스크의 거의 모든 분야에서 SOTA 성능을 발휘하고 있는 사전학습 언어모델을 활용하여 요약 태스크에 최적화된 인공지능 모델을 개발
- 오토 인코딩 학습의 한계를 극복하면서, 단일 방향 정보만 이용하여 학습이 이루어지는 오토 리그레시브(Auto Regressive, AR) 모델의 문제점을 보완하는 Transformer 구조의 모델에 대한 추가 연구를 통해 요약 태스크에 최고의 성능을 발휘하는 모델 개발
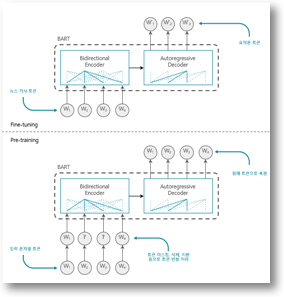
<전이학습 기반의 요약 모델>
2) 생성요약 모델 구현 및 성능 평가
- 모델 성능 평가에는 기계번역, 요약 등의 태스크에서 주로 사용되는 ROUGE(Recall-Oriented Understudy for Gisting Evaluation) 메트릭을 활용하여 수행
- ROUGE의 알고리즘은 시스템이 만들어낸 요약과 정답 요약, 그리고 recall 값에 대한 n-gram의 개수를 계산하는 방식임. 하단의 수식은 ROUGE 메트릭을 계산하는 수식임
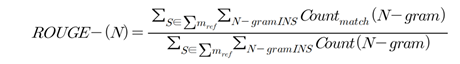
3) 생성요약 모델 구축 결과
- 학습데이터 정보
데이터 종류 데이터 종류 학습용(Training) 검증용(Validation) 테스트용(Test) 합계 뉴스 21,600 2,700 2,700 27,000 보도자료 16,000 2,000 2,002 20,002 역사기록물 8,000 1,000 1,002 10,002 & 문화재 보고서 8,000 1,000 1,000 10,000 회의록 27,200 3,400 3,400 34,000 사설 8,000 1,000 1,000 10,000 간행물 8,000 1,000 1,000 10,000 연설물 32,000 4,000 4,000 40,000 문학 9,600 1,200 1,200 12,000 나래이션 8,371 1,000 1,000 10,371 합계 146,771 18,300 18,304 183,375 모델링 정보
- train steps : 20,000
- batch size : 16
- accumulation count : 10
- 모델 평가 결과
모델 구축 후 위 학습데이터 중 학습에 사용되지 않은 테스트용 데이터로 모델 평가 진행
최종 ROUGE-L 스코어 : ROUGE-F(1/2/3/l): 44.66/26.48/36.89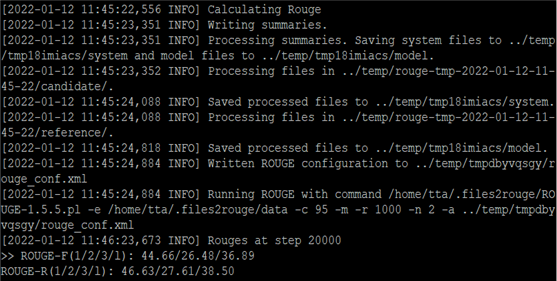
-
데이터 성능 점수
측정값 (%)기준값 (%)데이터 성능 지표
데이터 성능 지표 번호 측정항목 AI TASK 학습모델 지표명 기준값 점수 측정값 점수 1 생성요약 모델 성능평가 Text Summary Transformer ROUGE-L 35 % 36.89 %
※ 데이터 성능 지표가 여러 개일 경우 각 항목을 클릭하면 해당 지표의 값이 그래프에 표기됩니다.
※ AI모델 평가 지표에 따라 측정값의 범위, 판단 기준이 달라질 수 있습니다. (ex. 오류율의 경우, 낮을수록 좋은 성능을 내는 것으로 평가됩니다)
-
설명서 및 활용가이드 다운로드
데이터 설명서 다운로드 구축활용가이드 다운로드대표도면
No 문서 번호 REPORT-narration-00001 문서 유형 나레이션 발행자 KBS 발행처 KBS 발행연도 2020 출처 KBS 원문 길이 514 원문 및 추출요약 잠시 마음을 놓는 순간 거세지는 게 이곳의 바람. 마을을 떠나는 길에는 구름까지 잔뜩 몰려오더니 결국 비바람이 몰아치기 시작했다. 하필 오늘은 펭귄 서식지에 오기로 한 날. 풀들이 다 휘어버릴 만큼 거센 바람을 보니 여기 사는 펭귄들이 걱정됐다. 여기에서 돌아갈 수도 없다. 이런 날씨에 펭귄이 있을까 걱정했는데 입구부터 귀여운 울음소리가 들닌다. 손님을 처음으로 반겨준 이 녀석. 장난감 나팔 같은 목소리가 독특하다. 얼음이 아닌 따뜻한 땅을 좋아하는 마젤란 펭귄은 이곳에 집을 짓고 매년 봄, 여름을 보낸다. 신기하게도 같은 집에서 같은 암수가 매년 만나 이렇게 예쁜 새끼를 낳고 여름 내내 수영을 가르쳐서 가을이 되면 더 따뜻한 브라질로 떠난다고 한다. 바람부는 허허벌판에서 5kg의 몸으로 버티는 펭귄들이 기특해 보였다. 한 녀석은 길목에서 손님을 기다리고 있는 것 같더니 따라나서자 이렇게 줄행랑을 친다. 따라 잡을 수 없을 만큼 빨랐다. 다가서자 신기한 듯 이리저리 고개를 돌리며 구경이다. 생성요약 마젤란 펭귄은 매년 같은 집에서 같은 암수가 만나 새끼를 낳고 여름 내내 수영을 가르쳐서 가을에 더 따듯한 브라질로 떠난다고 한다. 데이터 포맷 및 어노테이션 포맷
데이터 포맷 및 어노테이션 포맷 No 항목 타입 필수여부 비고 한글명 영문명 1 메타 정보(수집 단계) JsonObject Y 1–1 문서 번호 doc_id String Y 1–2 문서 범주 doc_category String Y 1–3 문서 유형 doc_type String Y 1–4 문서명 doc_name String Y 1–5 발행자 author String option 1–6 발행처 publisher String option 1–7 발행연도 published_year String option 1–8 출처 doc_origin String Y 2 메타 정보(정제 단계) String Y 2–1 원문 번호 passage_id String Y 2–2 원문 passage String Y 2–3 원믄 글자수 passage_Cnt Number Y 3 요약문 string Y 3–1 1문장 요약(생성요약) Summary1 string Y 3–2 2~3문장 요약(추출요약) Summary2 string option 3–3 20%요약(추출요약) Summary3 stringr option 3–4 20%요약 글자수 Summary_Cnt Number Y 실제 예시

-
데이터셋 구축 담당자
수행기관(주관) : ㈜와이즈넛
수행기관(주관) 책임자명 전화번호 대표이메일 담당업무 박희승 02-3404-7212 hspark@wisenut.co.kr 총괄 책임자 수행기관(참여)
수행기관(참여) 기관명 담당업무 유클리드소프트 가공 책임자 포티투마루 모델 개발 책임자 데이터 관련 문의처
데이터 관련 문의처 담당자명 전화번호 이메일 박희승 02-3404-7212 hspark@wisenut.co.kr
-
인터넷과 물리적으로 분리된 온라인·오프라인 공간으로 의료 데이터를 포함하여 보안 조치가 요구되는 데이터를 다운로드 없이 접근하고 분석 가능
* 온라인 안심존 : 보안이 보장된 온라인 네트워크를 통해 집, 연구실, 사무실 등 어디서나 접속하여 데이터에 접근하고 분석
* 오프라인 안심존 : 추가적인 보안이 필요한 데이터를 대상으로 지정된 물리적 공간에서만 접속하여 데이터에 접근하고 분석 -
- AI 허브 접속
신청자 - 안심존
사용신청신청자신청서류 제출* - 심사구축기관
- 승인구축기관
- 데이터 분석 활용신청자
- 분석모델반출신청자
- AI 허브 접속
-
1. 기관생명윤리위원회(IRB) 심의 결과 통지서 [IRB 알아보기] [공용IRB 심의신청 가이드라인]
2. 기관생명윤리위원회(IRB) 승인된 연구계획서
3. 신청자 소속 증빙 서류 (재직증명서, 재학증명서, 근로계약서 등 택1)
4. 안심존 이용 신청서 [다운로드]
5. 보안서약서 [다운로드]
※ 상기 신청서 및 첨부 서류를 완비한 후 신청을 진행하셔야 정상적으로 절차가 이루어집니다. -
신청 및 이용관련 문의는 safezone1@aihub.kr 또는 02-525-7708, 7709로 문의
데이터셋 다운로드 승인이 완료 된 후 API 다운로드 서비스를 이용하실 수 있습니다.
API 다운로드 파일은 분할 압축되어 다운로드 됩니다. 분할 압축 해제를 위해서는 분할 압축 파일들의 병합이 필요하며 리눅스 명령어 사용이 필요합니다.
리눅스 OS 계열에서 다운로드 받으시길 권장하며 윈도우에서 파일 다운로드 시 wsl(리눅스용 윈도우 하위 시스템) 설치가 필요합니다.
※ 파일 병합 리눅스 명령어
find "폴더경로" -name "파일명.zip.part*" -print0 | sort -zt'.' -k2V | xargs -0 cat > "파일명.zip"
- 해당 명령어 실행 시, 실행 경로 위치에 병합 압축 파일이 생성됩니다.
- 병합된 파일 용량이 0일 경우, 제대로 병합이 되지 않은 상태이니 "폴더경로"가 제대로 입력되었는지 확인 부탁드립니다.
※ 데이터셋 소개 페이지에서 다운로드 버튼 클릭하여 승인이 필요합니다.
오프라인 데이터 이용 안내
본 데이터는 K-ICT 빅데이터센터에서도 이용하실 수 있습니다.
다양한 데이터(미개방 데이터 포함)를 분석할 수 있는 오프라인 분석공간을 제공하고 있습니다.
데이터 안심구역 이용절차 및 신청은 K-ICT빅데이터센터 홈페이지를 참고하시기 바랍니다.

국방데이터 개방 안내
본 데이터는 국방데이터로 군사 보안에 따라 AI허브에서 데이터를 제공하지 않으며,
군 담당자를 통한 별도의 사용 신청이 필요합니다.