AI 교관 데이터의 공개용 데이터(해군_음성데이터)는 준비중이며, 추후 공개될 예정입니다.
-
소개
군사 교범/교수안/CBT를 기반으로 구축한 교육자료 데이터 50,000건 이상 및 질의응답 데이터 12,000건 이상의 텍스트데이터와 해군의 문어/답어로 구축한 100시간 이상(100,000건 이상)의 음성데이터로 구성
구축목적
ㅇ맞춤형/효율적 교육 실현 및 교육의 질적 향상과 예산절감, 확장성 높은 군 지식데이터 확보 ㅇAI 교육/훈련 지원체계 개발에 활용
-
메타데이터 구조표 데이터 영역 영상이미지 데이터 유형 오디오 , 텍스트 데이터 형식 csv, wav 데이터 출처 ● 군 교육자료(교범, 교수안, CBT(동영상)) ● 해군 문/답어(문어/답어) 라벨링 유형 태깅(텍스트), 태깅(질의응답), 전사(음성) 라벨링 형식 json 데이터 활용 서비스 챗봇 서비스 데이터 구축년도/
데이터 구축량2024년/1. 교육자료 데이터 53,780건 2. 질의응답 데이터 12,420건 3. 음성데이터 100,535건 -
1. 데이터 구축 규모
데이터 구축 규모 데이터 종류 데이터 형태 원문 규모 어노테이션
규모(건)결과물 구분 교육자료
데이터질의응답
데이터음성
라벨링 데이터교범 텍스트 66권 53,261 43,369 9,892 해당없음 CBT 동영상 174차시 9,688 7,800 1,888 해당없음 교수안 텍스트 39권 3,251 2,611 640 해당없음 해군 음성 음성 100,535건 118시간 해당없음 해당없음 118시간
(100,535건)합계 53,780 12,420 100,535 2. 데이터 분포
2-1) 교육자료 데이터 및 질의응답 데이터 출처 분포데이터 분포-교육자료 데이터 및 질의응답 데이터 출처 분포 구분 교육자료 데이터 질의응답 데이터 수량 비율 수량 비율 교범 43,369 80.60% 9,892 79.60% CBT 7,800 14.50% 1,888 15.20% 교수안 2,611 4.90% 640 5.20% 합계 53,780 100% 12,420 100% 2-2) 교육자료 데이터 및 질의응답 데이터 주제 분포
데이터 분포-교육자료 데이터 및 질의응답 데이터 주제 분포 구분 교육자료 데이터 질의응답 데이터 수량 비율 수량 비율 부대운영 13,402 24.90% 3,105 25% 작전 14,032 26.10% 3,105 25% 작전지속지원 13,268 24.70% 3,105 25% 정보화력 13,078 24.30% 3,105 25% 합계 53,780 100% 12,420 100% -
-
※ AI 교관 데이터의 AI모델은 별도의 사전 신청을 통해 이용하실 수 있습니다. (구축업체 정보 참조)
<질의응답 모델>
AI 모델 선정: Llama 3.1 70B Instruct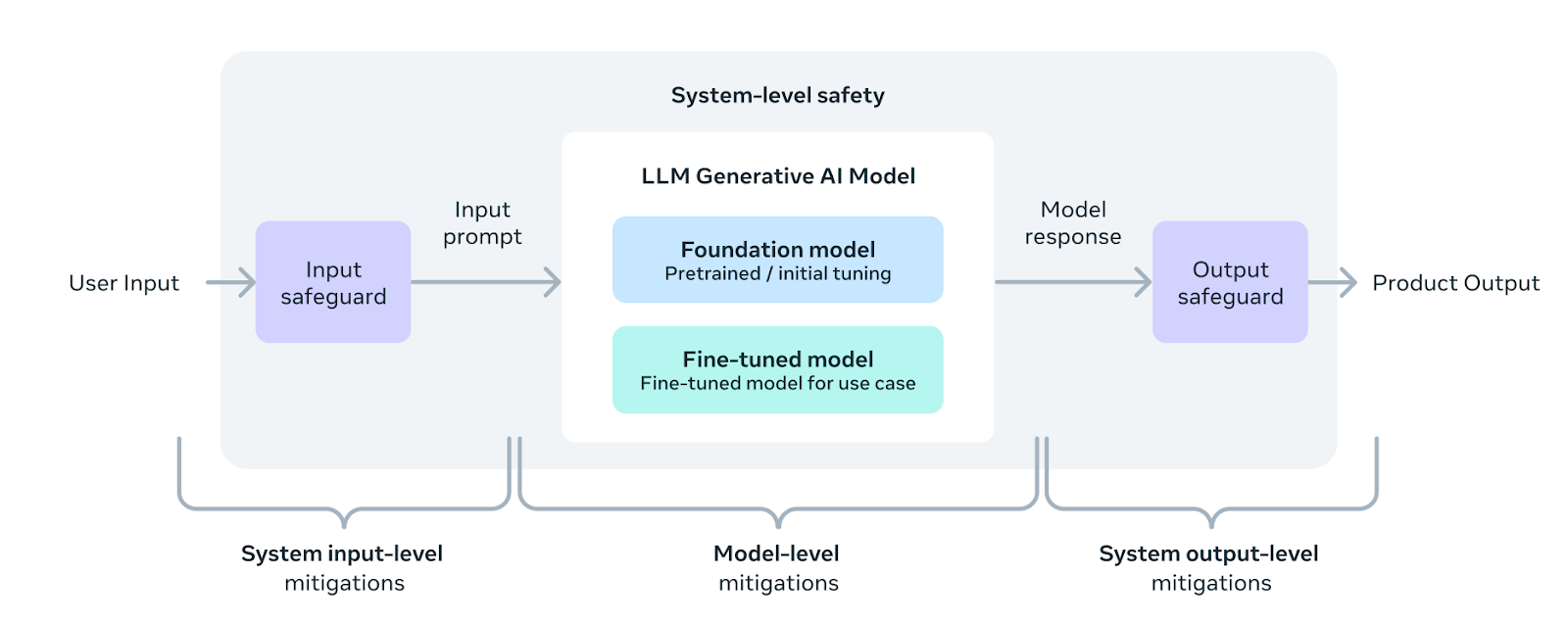
임베딩 모델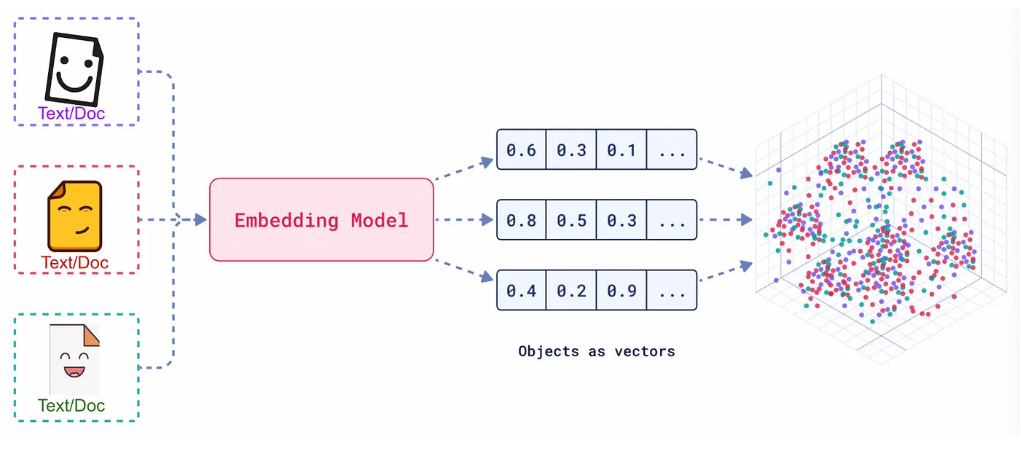
- EEVE-Korean-Instruct-10.8B-v1.0 모델을 open-korean-instructions라는 질의응답형 오픈 데이터셋을 일부 활용하여 학습시킨 후 국문과 영문에 대한 질의를 각각 수행. 별도의 영어 데이터셋 학습 없이도 영어에 대한 질답을 잘 수행함. 영어와 한국어 각각 높은 성능을 보여줌.
- 2024년 4월 Meta 사에서 초거대 언어 모델 Llama 3를 발표함. 오픈 소스 모델 중에 가장 높은 성능을 보이는 모델이기에 후보 모델군과의 비교를 통해 보다 우수한 모델 사용 고려.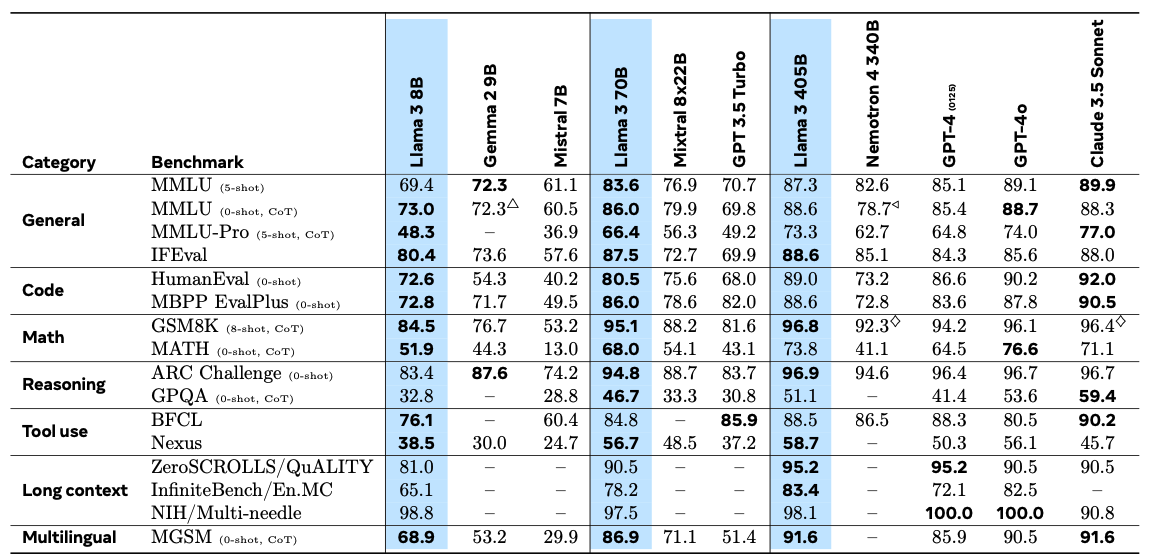
Llama 3 모델 성능 비교 표(출처: he Llama 3 Herd of Models:arXiv:2407.21783)- Llama 3는 LLM 중에 성능 면에서 Mistral, 구글의 Gemma 등과 같은 다른 오픈 소스 모델들을 제치고 뛰어난 성과를 기록함(참조:The Llama 3 Herd of Models:arXiv:2407.21783). Llama 3는 표준 디코더-온리 트랜스포머 아키텍처를 기반으로 하며, 성능을 높이기 위해 그룹 쿼리 어텐션(GQA)과 같은 최적화가 이루어짐. 학습량은 Llama 2에 비해여 월등히 많아 영어, 한국어 모두 뛰어난 성능을 보임.
- 현장에서 실제 데이터로 테스트 결과 EEVE 10.8B 모델보다 Llama 3.1 70B Instruct가 질의 대한 오답률이 30%가량 더 개선된 것을 확인함. 실제로 두 모델 간의 모델의 성능을 좌우하는 파라미터 개수는 7배 차이가 나기 때문에 당연한 결과임. EEVE 모델의 경우 한글을 이해하지 못하여 영문으로 답변하는 경우도 존재했으나 Llama 3의 경우 그런 오류가 전무했음. 이에 Llama 3.1 70B Instruct 모델을 채택하여 사용.
<음성인식 모델>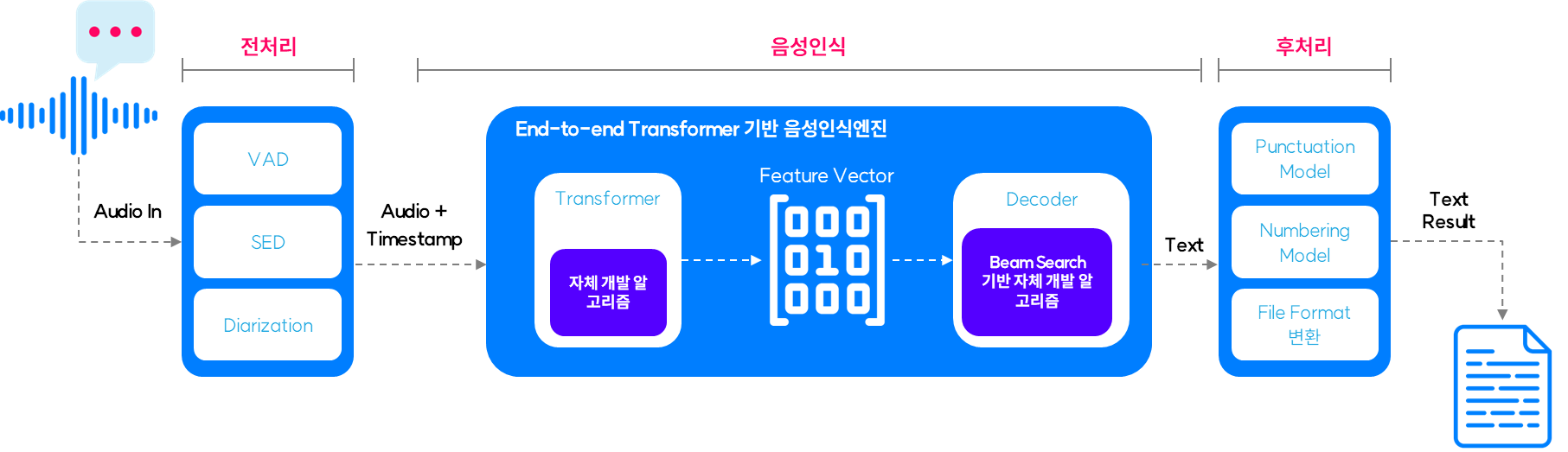
- 본 과제는 한국어 음성인식을 하며, 일상에서 쓰이지 않는 전문 용어 및 고유명사의 비중이 매우 큼. 추가적으로 폐쇄적인 환경에서 100시간 가량의 학습 데이터만을 활용하여 높은 음성인식 정확도를 달성해야 하는 등 특수성이 존재함
- 음성인식 모델의 “일반적“ 성능 측정을 위한 10가지 데이터셋에 대한 Multi-domain Benchmark로 제안된 ESB (S.Ghandi et al, 2022) 및 ESC(Anonymous, 2023)에서는 현재 음성인식 영역에서 최신 Framework인 E2E(End-to-end) 기반의 높은 성능을 자랑하는 대표적인 baseline 모델 5가지를 선정하였으며 이는 모두 wav2vec 2.0(3 Variations), Whisper 및 Conformer 기반임
- 다섯가지 모델 중 Whisper, Conformer, Wav2vec 2.0 AED 순으로 높은 성능을 보였으며, 이에 따라 본 과제의 주요 학습 모델군으로서 Whisper, Wav2vec 2.0 그리고 Conformer를 선정
- Whispher 모델은 8,000시간 이상의 한국어 음성 데이터를 사전 학습하였음. 이는 위에 언급된 논문에서 나오는 인도어(약1,000시간) 보다 많은 양임. 사전학습 모델을 활용함으로써 한국어에 대한 음성 인식 성능을 어느 정도 확보하며 데이터 부족을 극복할 수 있음.
- 논문 Comparison of Multilingual Self-Supervised and Weakly-Supervised Speech Pre-Training for Adaptation to Unseen Languages에 의하면, Whisper는 Wav2vec 2.0 (XLS-R) 모델에 비해서 더 많은 한국어 데이터셋을 사전학습하였기 때문에 Fluers 벤치마크의 한국어 부분에 대해서 월등히 높은 성능을 보였음
- Fleurs는 음성인식 모델의 Few-shot learning을 평가하는 벤치마크인 만큼, 적은 양의 학습데이터에 대한 음성인식 모델의 적응 능력을 평가할 수 있기 때문에 본 과제의 제한적인 양의 데이터셋에 대해서도 비슷한 효과를 기대할 수 있음
- Conformer 기반의 모델은 다국어 데이터셋에 대해서 학습된 오픈소스 모델이 존재하지 않아 위 논문에서는 실험 대상에 포함시키지 않았음
- 상기 이유로 Whisper가 본 과제 수행에 가장 적합한 모델로 예상됨. -
설명서 및 활용가이드 다운로드
데이터 설명서 다운로드 구축활용가이드 다운로드1. 데이터 구성
1-1) 교육자료 데이터데이터 구성-교육자료 데이터 구분 속성명 타입 필수여부 설명 1 content_key number 필수 데이터 생성번호 2 content_id string 필수 콘텐츠 고유 식별자
(문서구분_문서유형_문서제목_작업자ID_데이터생성번호)3 content_category string 필수 콘텐츠 유형 4 content_title string 필수 콘텐츠 제목 5 content_content string 필수 콘텐츠 본문 6 content_hascomment boolean 필수 주석 존재 여부(true/false) 7 content_hasimage boolean 필수 이미지 존재 여부(true/false) 8 content_hastable boolean 필수 표 존재 여부(true/false) 9 document_id number 필수 문서 고유 식별자 10 document_category string 필수 문서 유형 11 document_title string 필수 문서 제목 12 document_filesize string 필수 문서 크기 13 document_filetype string 필수 문서 형식 14 document_pbis string 필수 군 분류 15 document_writtenat string 필수 최종 개정일 16 document_startpage string 필수 콘텐츠 시작 페이지(문서)또는 시작시간/시점(CBT동영상) 17 document_endpage string 필수 콘텐츠 종료 페이지(문서)또는 종료시간/시점(CBT동영상) 18 document_chapter number 선택 장 19 document_section number 선택 절 20 document_clause number 선택 항 21 document_item number 선택 목 22 document_line number 선택 행 23 document_dicindex string 선택 사전 인덱스 24 comment_id number 선택 주석 고유 식별자(comment_생성번호) 25 comment_comment string 선택 주석 내용 26 image_id number 선택 이미지 고유 식별자(image_content id_생성번호) 27 image_title string 선택 이미지 제목 28 image_content string 선택 이미지 설명 29 image_keyword array 선택 이미지 관련 키워드 30 image_path string 선택 이미지 저장 경로 31 table_id number 선택 표 고유 식별자(table_content id_생성번호) 32 table_title string 선택 표 제목 33 table_content string 선택 표 설명 34 table_keyword array 선택 표 관련 키워드 35 table_path string 선택 표 저장 경로 1-2) 질의응답 데이터
데이터 구성-질의응답 데이터 구분 속성명 타입 필수여부 설명 1 content_key number 필수 데이터 생성번호 2 content_question string 필수 질의 3 content_answer string 필수 응답 4 content_id string 필수 콘텐츠 고유 식별자
(문서구분_문서유형_문서제목_작업자ID_데이터생성번호)5 content_category string 필수 콘텐츠 유형 6 content_title string 필수 콘텐츠 제목 7 content_content string 필수 콘텐츠 본문 8 content_hascomment boolean 필수 주석 존재 여부(true/false) 9 content_hasimage boolean 필수 이미지 존재 여부(true/false) 10 content_hastable boolean 필수 표 존재 여부(true/false) 11 document_id number 필수 문서 고유 식별자 12 document_category string 필수 문서 유형 13 document_title string 필수 문서 제목 14 document_filesize string 필수 문서 크기 15 document_filetype string 필수 문서 형식 16 document_pbis string 필수 군 분류 17 document_writtenat string 필수 최종 개정일 18 document_startpage string 필수 콘텐츠 시작 페이지(문서)또는 시작시간/시점(CBT동영상) 19 document_endpage string 필수 콘텐츠 종료 페이지(문서)또는 종료시간/시점(CBT동영상) 20 document_chapter number 선택 장 21 document_section number 선택 절 22 document_clause number 선택 항 23 document_item number 선택 목 24 document_line number 선택 행 25 document_dicindex string 선택 사전 인덱스 26 comment_id number 선택 주석 고유 식별자(comment_생성번호) 27 comment_comment string 선택 주석 내용 28 image_id number 선택 이미지 고유 식별자(image_content id_생성번호) 29 image_title string 선택 이미지 제목 30 image_content string 선택 이미지 설명 31 image_keyword array 선택 이미지 관련 키워드 32 image_path string 선택 이미지 저장 경로 33 table_id number 선택 표 고유 식별자(table_content id_생성번호) 34 table_title string 선택 표 제목 35 table_content string 선택 표 설명 36 table_keyword array 선택 표 관련 키워드 37 table_path string 선택 표 저장 경로 1-3) 음성 데이터
데이터구성-음성 데이터 구분 속성명 타입 필수여부 설명 1 sound_Id string 필수 음성 데이터 파일명(확장자 제외) 2 pbis string 필수 군 분류 3 sampling_rate string 필수 sampling rate (16Khz등) 4 bit_depth string 필수 bit rate 5 channels string 필수 채널 수 구분 6 encoding string 필수 인코딩 7 file_size string 필수 음성 파일의 용량을mb단위로 기재 8 speaker string 필수 화자 구분값 9 gender string 필수 화자 성별 10 age number 필수 화자 나이 11 recording_device string 선택 녹음s/w 12 recording_environment string 선택 녹음 장소 13 recording_date string 필수 녹음 일시 14 script_title string 필수 스크립트 제목 15 script_number number 필수 스크립트 번호 16 sound_category string 필수 대본 유형 (질문인지 답변인지) 17 content string 필수 대본 실제 내용(텍스트) 2. 어노테이션 포맷
2-1) 교육자료 데이터어노테이션 포맷-교육자료 데이터 항목 설정 1 2 3 타입 필수여부 유효값 최소값 최대값 설명 content_key number Y 컨텐츠 가공 고유 번호 content object Y 콘텐츠 정보 content_id string Y 1 콘텐츠 고유 식별자 content_category string Y " 콘텐츠 유형 content_title string Y 1 콘텐츠 제목 content_content string Y 1 콘텐츠 본문 content_hascomment boolean Y 주석 존재 여부(true/false) content_hasimage boolean Y 이미지 존재 여부(true/false) content_hastable boolean Y 표 존재 여부(true/false) document object Y 문서 정보 document_id number Y 문서 고유 식별자 document_category string Y " 문서 유형 document_title string Y 1 문서 제목 document_filesize string Y 문서 크기 document_filetype string Y "HWP", "PDF", "DOCX","MP4" 문서 형식 document_pbis string Y " 군 분류 document_writtenat string Y 최종 개정일, YYYY-MM-DD document_startpage string Y 콘텐츠 시작 페이지 혹은 구간 시작.
(숫자 또는HH:mm:ss형식)document_endpage string Y 콘텐츠 시작 페이지 혹은 구간 시작,
(숫자 또는HH:mm:ss형식)document_chapter number N 장 document_section number N 절 document_clause number N 항 document_item number N 목 document_line number N 행 document_dicindex string N 사전 인덱스 comments array 주석 commnet_id number N 주석 고유 식별자 comment_comment string N 1 주석 내용 images array 이미지 image_id number N 이미지 고유 식별자 image_path string N 1 이미지 파일 경로 image_title string N 1 이미지 제목 image_content string N 1 이미지 설명 image_keyword array 2 이미지 관련 키워드 $value$ string N 1 tables array 표 table_id number N 표 고유 식별자 table_path string N 1 표 파일 경로 table_title string N 1 표 제목 table_content string N 1 표 설명 table_keyword array 2 표 관련 키워드 $value$ string N 1 2-2) 질의응답 데이터
어노테이션 포맷-질의응답 데이터 항목 설정 1 2 3 타입 필수여부 유효값 최소값 최대값 설명 content_key number Y 컨텐츠 가공 고유 번호 content_question string Y 1 컨텐츠를 답변으로 하는 질문 content_answer string Y 1 컨텐츠를 기반으로 생성된 답변 content object Y 콘텐츠 정보 content_id string Y 1 콘텐츠 고유 식별자 content_category string Y " 콘텐츠 유형 content_title string Y 1 콘텐츠 제목 content_content string Y 1 콘텐츠 본문 content_hascomment boolean Y 주석 존재 여부(true/false) content_hasimage boolean Y 이미지 존재 여부(true/false) content_hastable boolean Y 표 존재 여부(true/false) document object Y 문서 정보 document_id number Y 문서 고유 식별자 document_category string Y " 문서 유형 document_title string Y 1 문서 제목 document_filesize string Y 문서 크기 document_filetype string Y "HWP", "PDF", "DOCX","MP4" 문서 형식 document_pbis string Y " 군 분류 document_writtenat string Y 최종 개정일, YYYY-MM-DD document_startpage string Y 콘텐츠 시작 페이지 혹은 구간 시작.
(숫자 또는HH:mm:ss형식)document_endpage string Y 콘텐츠 시작 페이지 혹은 구간 시작,
(숫자 또는HH:mm:ss형식)document_chapter number N 장 document_section number N 절 document_clause number N 항 document_item number N 목 document_line number N 행 document_dicindex string N 사전 인덱스 comments array 주석 commnet_id number N 주석 고유 식별자 comment_comment string N 1 주석 내용 images array 이미지 image_id number N 이미지 고유 식별자 image_path string N 1 이미지 파일 경로 image_title string N 1 이미지 제목 image_content string N 1 이미지 설명 image_keyword array 2 이미지 관련 키워드 $value$ string N 1 tables array 표 table_id number N 표 고유 식별자 table_path string N 1 표 파일 경로 table_title string N 1 표 제목 table_content string N 1 표 설명 table_keyword array 2 표 관련 키워드 $value$ string N 1 2-3) 음성 데이터
어노테이션 포맷-음성데이터 항목 설정 1 타입 필수여부 유효값 최소값 최대값 설명 sound_Id string Y 1 음성 데이터 파일명 pbis string Y " 군 분류 sampling_rate string Y sampling rate bit_depth string Y 해당 음성의bit를 기재 channels string Y 채널 수 구분(stereo/mono) encoding string Y 인코딩 file_size string Y 음성 파일의 용량을mb단위로 기재 speaker string Y 화자 구분값(H01~H20) gender string Y "M","F" 화자 성별(남자: M /여자: A) age number Y 20 39 화자 나이(만나이 정수2자리) recording_device string N 1 녹음s/w recording_environment string N 1 녹음 장소 recording_date string Y 녹음 일시(YYYYMMDD) script_title string Y 1 스크립트 제목 script_number number Y 스크립트 번호 sound_category string Y "Q","A" 대본 유형(문어: Q /답어: A) content string Y 1 대본 실제 내용(텍스트) 3. 데이터 포맷
3-1) 교육자료 데이터콘텐츠 유형 교범 문서 유형 작전 문서 제목 작전 교범 원문 이 콘텐츠는 작전을 효과적으로 수행하기 위한 절차를 상세히 설명합니다. 라벨링 후 "content_content": "이 콘텐츠는 작전을 효과적으로 수행하기 위한 절차를 상세히 설명합니다." 3-2) 질의응답 데이터
콘텐츠 유형 교범 문서 유형 작전 문서 제목 작전 교범 질의응답 구축 방식 생성 및 수동 원문 이 콘텐츠는 작전을 효과적으로 수행하기 위한 절차를 상세히 설명합니다. 라벨링 후 질문:이 콘텐츠의 주요 내용은 무엇인가요?
답변:이 콘텐츠는 작전 수행 절차에 대한 정보를 제공합니다.3-3) 음성 데이터
스크립트 제목 샘플신호서 스크립트 번호 1 질의응답(Q/A)구분 A 인코딩 wav 원문 음성 : I like the military 라벨링 후 텍스트 : I like the military 4. 실제 예시
※ 군 보안으로 인해, 샘플로 대체.4-1) 교육자료 데이터 json (샘플)
{
"content_key": 1,
"content": {
"content_id": "교범_작전_작전교범_1",
"content_category": "교범",
"content_title": "작전 수행 절차",
"content_content": "이 콘텐츠는 작전을 효과적으로 수행하기 위한 절차를 상세히 설명합니다.",
"content_hascomment": true,
"content_hasimage": true,
"content_hastable": false
},
"document": {
"document_id": 12,
"document_category": "작전",
"document_title": "작전 교범",
"document_filesize": "12 MB",
"document_filetype": "PDF",
"document_pbis": "육군",
"document_writtenat": "2024-11-29",
"document_startpage": "1",
"document_endpage": "30",
"document_chapter": 1,
"document_section": 2,
"document_clause": 3,
"document_item": 4,
"document_line": 5,
"document_dicindex": "ㅅ"
},
"comments": [
{
"comment_id": 101,
"comment_comment": "작전 수행 절차에서 유의해야 할 사항이 추가로 필요합니다."
}
],
"images": [
{
"image_id": 111,
"image_path": "./education/image_table/1111222233334444.png",
"image_title": "작전 수행 절차 이미지",
"image_content": "작전 수행 절차를 시각적으로 나타낸 이미지",
"image_keyword": ["작전", "절차", "이미지"]
}
],
"tables":[
{
"table_id": 112,
"table_path": "./education/image_table/5555666677778888.png",
"table_title": "작전 수행 절차",
"table_content": "작전 수행 절차를 정리한 표",
"table_keyword": ["작전", "절차"]
}
]
}4-2) 질의응답 데이터 json (샘플)
{
"content_key": 1,
"content_question": "이 콘텐츠의 주요 내용은 무엇인가요?",
"content_answer": "이 콘텐츠는 작전 수행 절차에 대한 정보를 제공합니다.",
"content": {
"content_id": "교범_작전_작전교범_1",
"content_category": "교범",
"content_title": "작전 수행 절차",
"content_content": "이 콘텐츠는 작전을 효과적으로 수행하기 위한 절차를 상세히 설명합니다.",
"content_hascomment": true,
"content_hasimage": true,
"content_hastable": false
},
"document": {
"document_id": 12,
"document_category": "작전",
"document_title": "작전 교범",
"document_filesize": "12 MB",
"document_filetype": "PDF",
"document_pbis": "육군",
"document_writtenat": "2024-11-29",
"document_startpage": "1",
"document_endpage": "30",
"document_chapter": 1,
"document_section": 2,
"document_clause": 3,
"document_item": 4,
"document_line": 5,
"document_dicindex": "ㅅ"
},
"comments": [
{
"comment_id": 101,
"comment_comment": "작전 수행 절차에서 유의해야 할 사항이 추가로 필요합니다."
}
],
"images": [
{
"image_id": 111,
"image_path": "./education/image_table/1111222233334444.png",
"image_title": "작전 수행 절차 이미지",
"image_content": "작전 수행 절차를 시각적으로 나타낸 이미지",
"image_keyword": ["작전", "절차", "이미지"]
}
],
"tables":[
{
"table_id": 112,
"table_path": "./education/image_table/5555666677778888.png",
"table_title": "작전 수행 절차",
"table_content": "작전 수행 절차를 정리한 표",
"table_keyword": ["작전", "절차"]
}
]
}4-3) 음성 데이터 json (샘플)
{
"sound_Id": "해군_샘플신호서_1문자 신호_1_A_H01_M_29_audacity_16kHz_16bit_mono_녹음실_20240920",
"pbis": "해군",
"sampling_rate": "16khz",
"bit_depth": "16bit",
"channels": "mono",
"encoding": "wav",
"file_size": "0.1740mb",
"speaker": "H01",
"gender": "M",
"age": 29,
"recording_device": "audacity",
"recording_environment": "녹음실",
"recording_date": "20240920",
"script_title": "샘플신호서",
"script_number": 1,
"sound_category": "A",
"content": "I like the military"
} -
데이터셋 구축 담당자
수행기관(주관) : 주식회사 테스트웍스
수행기관(주관) 책임자명 전화번호 대표이메일 담당업무 김여준 02-422-5178 aiworks_data@testworks.co.kr 사업 총괄 관리, 데이터 설계/수집/가공/라벨링, 데이터 저작도구 개발, 데이터 품질 관리 수행기관(참여)
수행기관(참여) 기관명 담당업무 트위그팜 AI 모델 개발 및 유효성 검증 데이터 관련 문의처
데이터 관련 문의처 담당자명 전화번호 이메일 기타 데이터 관련 문의 (데이터) 김여준 02-422-5178 aiworks_data@testworks.co.kr 기타 데이터 관련 문의 (데이터) 박기용 02-422-5178 aiworks_data@testworks.co.kr AI모델 관련 문의처
AI모델 관련 문의처 담당자명 전화번호 이메일 백선호 02-1833-5926 hello@twigfarm.net 최규동 02-1833-5926 hello@twigfarm.net 저작도구 관련 문의처
저작도구 관련 문의처 담당자명 전화번호 이메일 김여준 02-422-5178 aiworks_data@testworks.co.kr
-
인터넷과 물리적으로 분리된 온라인·오프라인 공간으로 의료 데이터를 포함하여 보안 조치가 요구되는 데이터를 다운로드 없이 접근하고 분석 가능
* 온라인 안심존 : 보안이 보장된 온라인 네트워크를 통해 집, 연구실, 사무실 등 어디서나 접속하여 데이터에 접근하고 분석
* 오프라인 안심존 : 추가적인 보안이 필요한 데이터를 대상으로 지정된 물리적 공간에서만 접속하여 데이터에 접근하고 분석 -
- AI 허브 접속
신청자 - 안심존
사용신청신청자신청서류 제출* - 심사구축기관
- 승인구축기관
- 데이터 분석 활용신청자
- 분석모델반출신청자
- AI 허브 접속
-
1. 기관생명윤리위원회(IRB) 심의 결과 통지서 [IRB 알아보기] [공용IRB 심의신청 가이드라인]
2. 기관생명윤리위원회(IRB) 승인된 연구계획서
3. 신청자 소속 증빙 서류 (재직증명서, 재학증명서, 근로계약서 등 택1)
4. 안심존 이용 신청서 [다운로드]
5. 보안서약서 [다운로드]
※ 상기 신청서 및 첨부 서류를 완비한 후 신청을 진행하셔야 정상적으로 절차가 이루어집니다. -
신청 및 이용관련 문의는 safezone1@aihub.kr 또는 02-525-7708, 7709로 문의
데이터셋 다운로드 승인이 완료 된 후 API 다운로드 서비스를 이용하실 수 있습니다.
API 다운로드 파일은 분할 압축되어 다운로드 됩니다. 분할 압축 해제를 위해서는 분할 압축 파일들의 병합이 필요하며 리눅스 명령어 사용이 필요합니다.
리눅스 OS 계열에서 다운로드 받으시길 권장하며 윈도우에서 파일 다운로드 시 wsl(리눅스용 윈도우 하위 시스템) 설치가 필요합니다.
※ 파일 병합 리눅스 명령어
find "폴더경로" -name "파일명.zip.part*" -print0 | sort -zt'.' -k2V | xargs -0 cat > "파일명.zip"
- 해당 명령어 실행 시, 실행 경로 위치에 병합 압축 파일이 생성됩니다.
- 병합된 파일 용량이 0일 경우, 제대로 병합이 되지 않은 상태이니 "폴더경로"가 제대로 입력되었는지 확인 부탁드립니다.
※ 데이터셋 소개 페이지에서 다운로드 버튼 클릭하여 승인이 필요합니다.
오프라인 데이터 이용 안내
본 데이터는 K-ICT 빅데이터센터에서도 이용하실 수 있습니다.
다양한 데이터(미개방 데이터 포함)를 분석할 수 있는 오프라인 분석공간을 제공하고 있습니다.
데이터 안심구역 이용절차 및 신청은 K-ICT빅데이터센터 홈페이지를 참고하시기 바랍니다.

국방데이터 개방 안내
본 데이터는 군사 보안이 적용된 국방 데이터로, 국제신호서 85,179세트만 개방되어 있습니다. 전체 데이터 이용을 원하실 경우, 군 담당자를 통해 별도 사용 신청이 필요합니다.
· 데이터 이용 신청 문의
[음성 데이터] 해군교육사령부 작전학부
| 소속 | 직책 | 연락처 |
|---|---|---|
| 해군교육사령부 작전학부 | 데이터 관리/활용 담당 | 055-907-3229 |
[텍스트 데이터] 해병대사령부 지능정보화발전과
| 소속 | 직책 | 연락처 |
|---|---|---|
| 해병대사령부 지능정보화발전과 | 데이터 관리/활용 담당 | 031-8012-3825 |