NEW 동남아시아 지식문화 데이터
- 분야문화관광
- 유형 텍스트
- 생성 방식LLM
-
데이터 변경이력
데이터 변경이력 버전 일자 변경내용 비고 1.1 2026-06-30 데이터 최종 개방 1.0 2026-06-26 데이터 개방 Beta Version 데이터 히스토리
데이터 히스토리 일자 변경내용 비고 2026-06-26 산출물 최종 공개 소개
태국과 캄보디아의 다양한 자료를 체계적으로 수집·정제한 동남아시아 지식·문화 데이터는 지역 고유의 언어와 문화적 맥락을 반영한 고품질 데이터셋입니다. 다국어 AI 모델 학습을 위한 원천데이터와 라벨링·QA 데이터로 활용되어, 다양한 분야에서 문화적 적합성을 강화하는 기반을 제공합니다.
구축목적
ㅇ 다국어 AI 학습용 데이터 구축 ㅇ 동남아시아 특화 AI 서비스 개발을 위한 핵심 인프라 구축
-
메타데이터 구조표 데이터 영역 문화관광 데이터 유형 텍스트 데이터 형식 텍스트 데이터 출처 자체수집 라벨링 유형 문장 라벨링, 삼중번역, QA셋 라벨링 형식 json 데이터 활용 서비스 ㅇ 연구 분야 - 고품질 데이터 공개 및 공유를 통한 AI 연구개발 활성화 - 희소성 높은 동남아시아 언어 및 문화 데이터를 제공하여 LLM 성능 향상 및 고도화 ㅇ 산업 분야 - 전통 문화 요소(의복, 의식 등)를 반영한 LLM 학습 데이터셋 및 평가용 벤치마크셋 병행 구축 - 다양한 산업 분야에서 AI 응용 서비스 개발을 촉진하여 새로운 경제적 가치 창출 및 AI 산업 생태계 확장 - 문화 영역 챗봇 및 국가 문화 소개형 AI 서비스 개발에 필요한 학습용/평가용 다목적 데이터셋으로 활용 가능 ㅇ 글로벌 분야 - 동남아시아 시장 진출을 위한 핵심 AI 기술 및 서비스 개발을 지원하여 국내 기업의 해외 경쟁력 제고 - 국내 기업의 글로벌 AI시장 진출을 위한 기술적 토대 마련 데이터 구축년도/
데이터 구축량2025년/ㅇ 원천데이터 4,870,205문장 26-32 동남아시아 지식·문화 데이터 4,870,205문장 (태국어 : 2,915,932문장, 캄보디아어 : 1,954,273문장) ㅇ 라벨링 데이터 4,870,205문장 26-32 동남아시아 지식·문화 데이터 4,870,205문장 (태국어 : 2,915,932문장, 캄보디아어 : 1,954,273문장) -
▶ 데이터 구축 규모
데이터 구축 규모표 RFP 제시량 원시데이터 수량 원천데이터 수량 라벨링 데이터 수량 비율 : 100% 비율 : 150% 비율 : 120% 비율 : 120% - 원문 텍스트
400만 문장 이상
- QA셋 2만 개 이상- 원문 텍스트
600만 문장 이상- 정제 텍스트
480만 문장 이상
(4,870,205문장)- 라벨링 문장
480만 문장 이상
(4,870,205문장)
- QA셋 2.4만 개
▶ 데이터 분포데이터 분포표 대분류 중분류 비율 언어 유형 태국어 60% 캄보디아어 40% 문화 분야 음악 4% 음식 6% 언어 9% 의복/패션 5% 의식/의례 16% 사회/문화 13% 경제/산업 14% 건강/생활 13% 여행 11% 기타 8% 문화 반영 언어 데이터 일반문장 85% 속담 10% 신조어 5% 지식·문화 문서 출처 백과/공공 지식문서 35% 종교/공익 콘텐츠 20% 강연/보도/공공 발표문 15% 뉴스/시민 저널리즘 10% 자막 기반 대화체 0% SNS/포럼/커뮤니티 10% 기타 전문자료 10%
• 문화 분야 분류데이터 분포-문화 분야 분류표 항목 세부 분류 비율(%) 음악 전통 악기 소개
지역 음악 유형
춤/의식 음악
축제 음악4% 음식 전통 음식
유행 음식
재래시장 등6% 언어 속담, 신조어 9% 의복/패션 전통 의상
혼례복
지역 의복(북부/이산/크메르 등)
일상 전통복5% 의식/의례 연중 행사(송끄란, 프쭘번)
종교 의례(불교, 힌두)
왕실 행사(대관식, 공덕의식)
출가식/장례식16% 사회/문화 정치
교육
엔터테인먼트 등13% 경제/산업 경제/투자 등
공장/회사/기술 등14% 건강/생활 건강
운동 등13% 여행 여행지
기념품 등11% 기타 8%
• 문화 반영 언어 데이터 분류데이터 분포-문화 반영 언어 데이터 분류표 항목 세부 분류 비율(%) 일반 문장 백과적 서술
설명문
정의문85% 속담 지역 전통 속담
교훈적 속담
의례/농경 관련 속담10% 신조어 인터넷 유행어
청년층 언어
외래어 차용
축약어5%
• 지식·문화 문서 출처데이터 분포-지식·문화 문서 출처 항목 세부 분류 비율(%) 백과/공공 지식문서 Wikipedia
Wikivoyage
Wikibooks35% 종교/공익 콘텐츠 JW300 (종교 문서)
AI4D 공공번역문
성경/경전 기반 데이터20% 강연/보도/공공 발표문 TED Talks
TICO-19 (보건 정보)
정부 보도자료15% 뉴스/시민 저널리즘 GlobalVoices
지역 뉴스 번역 기사10% 자막 기반 대화체 OpenSubtitles
영화/드라마 자막
SEACrowd 일부0% SNS/포럼/커뮤니티 SEACrowd (Thai Pythainlp Subset 등)
포럼 번역글
댓글형 크롤링10% 기타 전문자료 정부 연구 보고서
문화유산 설명서
관광 가이드 콘텐츠10% -
-
AI 모델 상세 설명서 다운로드
AI 모델 상세 설명서 다운로드 AI 모델 다운로드1. 지식·문화 질의응답
○ 임무 정의
- 지식·문화 질의응답
ㅇ 태국어/캄보디아어 지식·문화에 대한 맥락적 질의에 대한 답변 생성
○ 임무 선정 사유
- 평가용 테스트셋을 4지선다형(MCQA)으로 구성하고, 모델이 생성한 응답을 보기 4개와 비교해 가장 높은 유사도를 갖는 선택지를 최종 답으로 선택하여 최종 선택지의 정오 여부를 기반으로 F1-score를 산출
○ 학습 모델 개발 환경
- 학습 환경: Amazon Linux, Python, Pytorch, GPU
- 모델리소스 및 자원 활용: 고성능 GPU 서버를 사용하여 모델 학습을 진행
- 모델 개발: 1-Cycle 자가 점검 계획에 맞춰 모델 개발
- 성능 지표 결과를 통해 가장 성능이 우수한 모델로 최종 선정
○ 최종 선정 모델
- Qwen/Qwen3-8B
- Hugging Face 사이트로부터 다운로드 가능
[ Qwen/Qwen3-8B 모델 ]
○ 학습 데이터 생성
- 학습 데이터 분할(8:1:1 로 분할)
* train – 전처리 텍스트, 라벨링json
* valid – 전처리 텍스트, 라벨링json
* test - 전처리 텍스트, 라벨링.json
○ AI 모델 성능지식·문화 질의응답_AI모델 성능 AI Task 알고리즘 데이터 수량 성능지표 목표치 평가결과 총 구축량 학습(80%) 평가(10%) 지식·문화
질의응답-태국어Qwen3-8B 텍스트 14,400 건
캡션기준 14,400 건캡션기준
11,520 건캡션기준
1,440 건F1 Score 75% 이상 90.66% 지식·문화
질의응답-캄보디아어Qwen3-8B 텍스트 10,250 건
캡션기준 10,250 건캡션기준
8,200 건캡션기준
1,025 건F1 Score 60% 이상 86.54%
2. 지식·문화 삼중번역
○ 임무 정의
- 지식·문화 삼중번역
ㅇ 태국어/캄보디아어 지식·문화 삼중번역 (한국어, 현지어, 영어)
○ 임무 선정 사유
- 생성된 번역문과 정답 번역문을 문장 단위로 비교한 뒤, SacreBLEU의 sentence BLEU 지표를 적용하여 토큰 기반 유사도를 정량적으로 산출
- 생성된 번역문과 정답 번역문을 문장 단위로 비교한 뒤, SentencePiece 기반 서브워드 토크나이저를 적용하여 토큰화하고, spBLEU 지표를 사용해 토큰 기반 유사도를 정량적으로 산출.
○ 학습 모델 개발 환경
- 학습 환경: Amazon Linux, Python, Pytorch, GPU
- 모델리소스 및 자원 활용: 고성능 GPU 서버를 사용하여 모델 학습을 진행
- 모델 개발: 1-Cycle 자가 점검 계획에 맞춰 모델 개발
- 성능 지표 결과를 통해 가장 성능이 우수한 모델로 최종 선정
○ 최종 선정 모델
- Qwen/Qwen3-8B
- Hugging Face 사이트로부터 다운로드 가능
[ Qwen/Qwen3-8B 모델 ]○ 학습 데이터 생성
- 학습 데이터 분할(8:1:1 로 분할)
* train – 전처리 텍스트, 라벨링json
* valid – 전처리 텍스트, 라벨링json
* test - 전처리 텍스트, 라벨링.json
○ AI 모델 성능지식·문화 삼중번역_AI모델 성능 AI Task 알고리즘 데이터 수량 성능지표 목표치 평가결과 총 구축량 학습(80%) 평가(10%) 지식·문화 삼중번역
-태국어-영어Qwen3-8B 텍스트 13,755 건
캡션기준 13,755 건캡션기준
11,004 건캡션기준
1,376 건BLEU 45.3 이상 47.3 지식·문화 질의응답
-캄보디아어-영어Qwen3-8B 텍스트 8,634 건
캡션기준 8,634 건캡션기준
6,907 건캡션기준
864 건BLEU 42 이상 42.73 지식·문화 질의응답
-태국어-한국어Qwen3-8B 텍스트 13,755 건
캡션기준 13,755 건캡션기준
11,004 건캡션기준
1,376 건spBLEU 35 이상 37.24 지식·문화 질의응답
-캄보디아어-한국어Qwen3-8B 텍스트 8,634 건
캡션기준 8,634 건캡션기준
6,907 건캡션기준
864 건spBLEU 30 이상 37.25 -
설명서 및 활용가이드 다운로드
데이터 설명서 다운로드 구축활용가이드 다운로드▶ 데이터 구성
데이터구성표 구분 획득/수집 단계 정제 단계 가공 단계 데이터 구분 원시데이터 원천데이터 라벨링데이터 데이터 형태 텍스트 정제 텍스트 라벨링 문장, 삼중번역, QA셋
▶ 어노테이션 포맷
○ 일반 라벨링 데이터(QA 제외)어노테이션 포맷-일반 라벨링 데이터(QA 제외) 표 분류 속성명 타입 필수 여부 내용 범위 비고 1 meta_data object 메타데이터 1.1 basic_info object 1.1.1 language String Y 데이터셋 "TH", "KH" 1.1.2 version String N 데이터셋 버전 1.1.3 document_id String Y 고유식별자 1.1.4 created_date String N 텍스트 생성 일자 ^\d{8}$ YYYYMMDD 1.1.5 issue_date String N 발행 일자 ^\d{8}$ YYYYMMDD 1.2 copylight_info object 1.2.1 writer_ko String N 저작자(한국어) 1.2.2 writer_local String N 저작자(현지어) 1.2.3 writer_en String N 저작자(영어) 1.2.4 copyrighter_ko String N 저작권 소유자(한국어) 1.2.5 copyrighter_local String N 저작권 소유자(현지어) 1.2.6 copyrighter_en String N 저작권 소유자(영어) 1.3 data_info object 1.3.1 origin_extension String Y 원본 파일 형태 1.3.2 data_sources String Y 데이터 출처 1.3.3 data_type String Y 자료유형 백과/공공 지식문서, 종교/공익 콘텐츠, 강연/보도/공공 발표문, 뉴스/시민 저널리즘, 자막 기반 대화체, SNS/포럼/커뮤니티, 기타 전문자료 1.3.4 word_count Int Y 어절수 1.3.5 file_size String Y 파일 사이즈 1.3.6 encoding_type String Y 인코딩 타입 1.3.7 expression_type String Y 표현 유형 일반문장, 신조어, 속담 1.3.8 expression_temporal String N 신조어 표현 시기 3년 이내, 3년 이후 2 annotation_data object 어노테이션 2.1 data_local object 2.1.1 topic String Y 주제 분류(현지어) Korean Thai Khmer 음악 ดนตรี តន្ត្រី 음식 อาหาร អាហារ 언어 ภาษา ភាសា 의복/패션 เสื้อผ้า សម្លៀកបំពាក់ 의식/의례 พิธีกรรม ពិធីការ 사회/문화 สังคม/วัฒนธรรม សង្គម/វប្បធម៌ 경제/산업 เศรษฐกิจ សេដ្ឋកិច្ច /อุตสาหกรรม /ឧស្សាហកម្ម 건강/생활 สุขภาพ/วิถีชีวิต សុខភាព/ជីវិតប្រចាំថ្ងៃ 여행 การท่องเที่ยว ការធ្វើដំណើរ 기타 อื่น ๆ ផ្សេងៗ 2.1.2 keyword String Y 키워드(현지어) 2.1.3 title String Y 텍스트 제목(현지어) 2.1.4 text String Y 텍스트 내용(현지어) 2.2 data_ko object 2.2.1 topic String Y 주제 분류(한국어) "음악", "음식", "언어", "의복/패션", "의식/의례", "사회/문화", "경제/산업", "건강/생활", "여행", "기타" 2.2.2 keyword String Y 키워드(한국어) 2.2.3 title String Y 텍스트 제목(한국어) 2.2.4 text String Y 텍스트 내용(한국어) 2.3 data_en object 2.3.1 topic String Y 주제 분류(영어) “music", "food", "language", "clothing", "rituals", "society/culture", "economy/industry", "health/lifestyle", "travel", "others” 2.3.2 keyword String Y 키워드(영어) 2.3.3 title String Y 텍스트 제목(영어) 2.3.4 text String Y 텍스트 내용(영어)
○ QA 라벨링 데이터어노테이션 포맷-QA라벨링 데이터표 분류 속성명 타입 필수
여부내용 범위 비고 1 meta_data object 메타데이터 1.1 basic_info object 1.1.1 language String Y 데이터셋 "TH", "KH" 1.1.2 version String N 데이터셋 버전 1.1.3 document_id String Y 고유식별자 1.1.4 created_date String N 텍스트 생성 일자 ^\d{8}$ YYYYMMDD 1.1.5 issue_date String N 발행 일자 ^\d{8}$ YYYYMMDD 1.2 copylight_info object 1.2.1 writer_ko String N 저작자(한국어) 1.2.2 writer_local String N 저작자(현지어) 1.2.3 writer_en String N 저작자(영어) 1.2.4 copyrighter_ko String N 저작권 소유자(한국어) 1.2.5 copyrighter_local String N 저작권 소유자(현지어) 1.2.6 copyrighter_en String N 저작권 소유자(영어) 1.3 data_info object 1.3.1 origin_extension String Y 원본 파일 형태 1.3.2 data_sources String Y 데이터 출처 1.3.3 data_type String Y 자료유형 백과/공공 지식문서, 종교/공익 콘텐츠, 강연/보도/공공 발표문, 뉴스/시민 저널리즘, 자막 기반 대화체, SNS/포럼/커뮤니티, 기타 전문자료 1.3.4 word_count Int Y 어절수 1.3.5 file_size String Y 파일 사이즈 1.3.6 encoding_type String Y 인코딩 타입 1.3.7 expression_type String Y 표현 유형 일반문장, 신조어, 속담 1.3.8 expression_temporal String N 신조어 표현 시기 3년 이내, 3년 이후 2 annotation_data object 어노테이션 2.1 data_local object 2.1.1 topic String Y 주제 분류(현지어) Korean Thai Khmer 음악 ดนตรี តន្ត្រី 음식 อาหาร អាហារ 언어 ภาษา ភាសា 의복/패션 เสื้อผ้า សម្លៀកបំពាក់ 의식/의례 พิธีกรรม ពិធីការ 사회/문화 สังคม/วัฒนธรรม សង្គម/វប្បធម៌ 경제/산업 เศรษฐกิจ សេដ្ឋកិច្ច /อุตสาหกรรม /ឧស្សាហកម្ម 건강/생활 สุขภาพ/วิถีชีวิต សុខភាព/ជីវិតប្រចាំថ្ងៃ 여행 การท่องเที่ยว ការធ្វើដំណើរ 기타 อื่น ๆ ផ្សេងៗ 2.1.2 keyword String Y 키워드(현지어) 2.1.3 title String Y 텍스트 제목(현지어) 2.1.4 text String Y 텍스트 내용(현지어) 2.2 data_ko object 2.2.1 topic String Y 주제 분류(한국어) "음악", "음식", "언어", "의복/패션", "의식/의례", "사회/문화", "경제/산업", "건강/생활", "여행", "기타“ 2.2.2 keyword String Y 키워드(한국어) 2.2.3 title String Y 텍스트 제목(한국어) 2.2.4 text String Y 텍스트 내용(한국어) 2.3 data_en object 2.3.1 topic String Y 주제 분류(영어) “music", "food", "language", "clothing", "rituals", "society/culture", "economy/industry", "health/lifestyle", "travel", "others” 2.3.2 keyword String Y 키워드(영어) 2.3.3 title String Y 텍스트 제목(영어) 2.3.4 text String Y 텍스트 내용(영어) 3 qa_set object Y QA셋 정보 3.1 turn_type string Y 질의응답 유형 “none”, "multi-turn" 3.2 raw_data object Y 인풋 데이터 정보 3.2.1 story_local string Y 현지어 입력값 3.2.2 story_korean string Y 한국어 번역 3.2.3 story_english string Y 영어 번역 3.3 first_turn object Y 첫 번째 턴 정보 3.3.1 turn_id number Y 턴ID 3.3.2 questions object Y 질문 정보 3.3.2.1 input_text string Y 질문 (현지어) 3.3.2.2 input_text_korean string Y 질문 (한국어) 3.3.2.3 input_text_english string Y 질문 (영어) 3.3.3 answers object Y 대답 정보 3.3.3.1 span_start number Y 3.3.3.2 span_end number Y 3.3.3.3 span_text string Y 3.3.3.4 input_text array Y 대답 (현지어) 배열 3.3.3.5 input_text_korean array Y 대답 (한국어) 배열 3.3.3.6 input_text_english array Y 대답 (영어) 배열 3.4 second_turn object Y 두 번째 턴 정보 3.4.1 turn_id number Y 턴ID 3.4.2 questions object Y 질문 정보 3.4.2.1 input_text string Y 질문 (현지어) 3.4.2.2 input_text_korean string Y 질문 (한국어) 3.4.2.3 input_text_english string Y 질문 (영어) 3.4.3 answers object Y 대답 정보 3.4.3.1 span_start number Y 3.4.3.2 span_end number Y 3.4.3.3 span_text string Y 3.4.3.4 input_text array Y 대답 (현지어) 배열 3.4.3.5 input_text_korean array Y 대답 (현지어) 텍스트 3.3.3.6 input_text_english array Y 대답 (영어) 배열 3.5 cot_label object Y CoT 라벨 정보 3.5.1 chain_of_thought_local string Y CoT 라벨 (현지어) 텍스트 3.5.2 chain_of_thought_korean string Y CoT 라벨 (한국어) 텍스트 3.5.3 chain_of_thought_english string Y CoT 라벨 (영어) 텍스트
▶ 데이터 포맷데이터 포맷표 원시데이터 원천데이터 라벨링데이터 .csv, json .txt .json
▶ 실제 예시
○ 원시데이터 예시
<원시데이터 예시1_태국어>

<원시데이터 예시2_캄보디아어>○ 원천데이터 예시

<원천데이터 예시1_태국어>

<원천데이터 예시2_캄보디아어>○ 라벨링데이터 예시(.json)
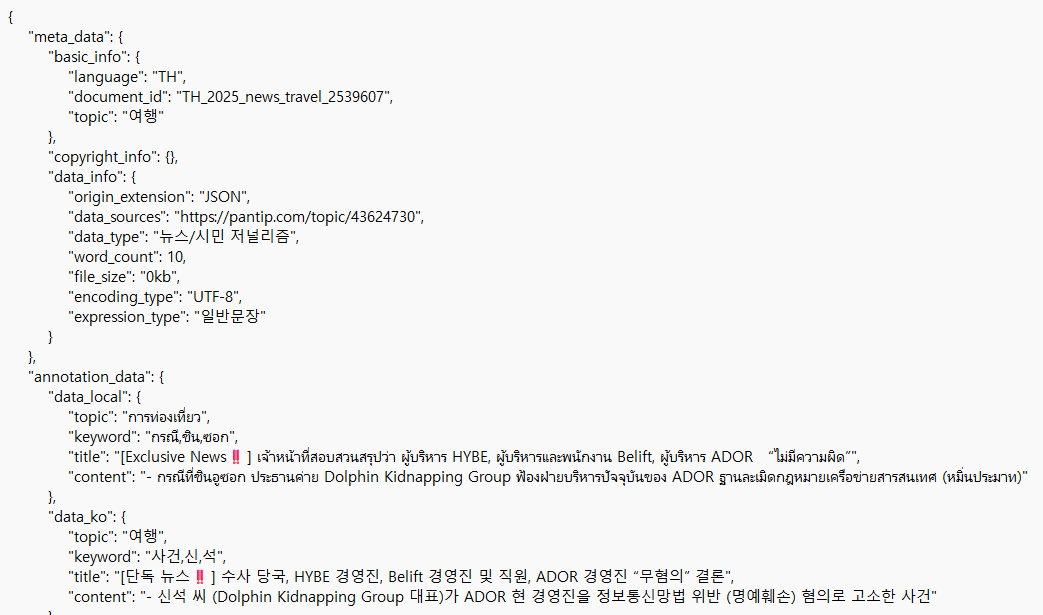
<라벨링데이터 예시1_태국어>
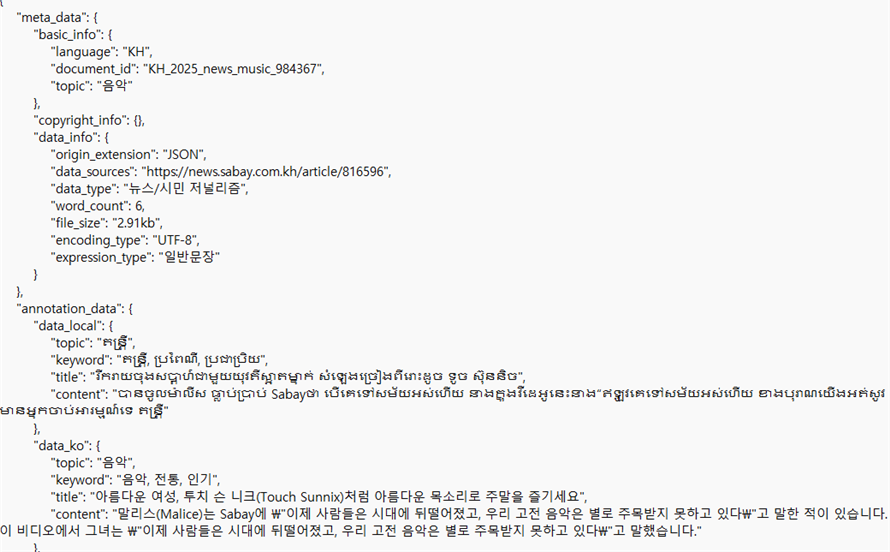
<라벨링데이터 예시2_캄보디아어> -
데이터셋 구축 담당자
수행기관(주관) : ㈜유핏
수행기관(주관) 책임자명 전화번호 대표이메일 담당업무 김희곤 1544-9730 koscokim@ufits.co.kr 사업총괄 관리, 데이터 수집, 가공, 검수, 저작도구 수행기관(참여)
수행기관(참여) 기관명 담당업무 ㈜피씨엔 데이터 정제 ㈜도스트11 AI학습모델 데이터 관련 문의처
데이터 관련 문의처 담당자명 전화번호 이메일 ㈜유핏 안동철 070-4012-1836 ceo@ufits.co.kr ㈜유핏 김희곤 070-4012-1836 koscokim@ufits.co.kr AI모델 관련 문의처
AI모델 관련 문의처 담당자명 전화번호 이메일 ㈜도스트11 양효걸 070-4012-1836 amadeus@mbc.co.kr 저작도구 관련 문의처
저작도구 관련 문의처 담당자명 전화번호 이메일 ㈜유핏 안동철 070-4012-1836 ceo@ufits.co.kr ㈜유핏 김희곤 070-4012-1836 koscokim@ufits.co.kr
-
인터넷과 물리적으로 분리된 온라인·오프라인 공간으로 의료 데이터를 포함하여 보안 조치가 요구되는 데이터를 다운로드 없이 접근하고 분석 가능
* 온라인 안심존 : 보안이 보장된 온라인 네트워크를 통해 집, 연구실, 사무실 등 어디서나 접속하여 데이터에 접근하고 분석
* 오프라인 안심존 : 추가적인 보안이 필요한 데이터를 대상으로 지정된 물리적 공간에서만 접속하여 데이터에 접근하고 분석 -
- AI 허브 접속
신청자 - 안심존
사용신청신청자신청서류 제출* - 심사구축기관
- 승인구축기관
- 데이터 분석 활용신청자
- 분석모델반출신청자
- AI 허브 접속
-
1. 기관생명윤리위원회(IRB) 심의 결과 통지서 [IRB 알아보기] [공용IRB 심의신청 가이드라인]
2. 기관생명윤리위원회(IRB) 승인된 연구계획서
3. 신청자 소속 증빙 서류 (재직증명서, 재학증명서, 근로계약서 등 택1)
4. 안심존 이용 신청서 [다운로드]
5. 보안서약서 [다운로드]
※ 상기 신청서 및 첨부 서류를 완비한 후 신청을 진행하셔야 정상적으로 절차가 이루어집니다. -
신청 및 이용관련 문의는 safezone1@aihub.kr 또는 02-525-7708, 7709로 문의
데이터셋 다운로드 승인이 완료 된 후 API 다운로드 서비스를 이용하실 수 있습니다.
API 다운로드 파일은 분할 압축되어 다운로드 됩니다. 분할 압축 해제를 위해서는 분할 압축 파일들의 병합이 필요하며 리눅스 명령어 사용이 필요합니다.
리눅스 OS 계열에서 다운로드 받으시길 권장하며 윈도우에서 파일 다운로드 시 wsl(리눅스용 윈도우 하위 시스템) 설치가 필요합니다.
※ 파일 병합 리눅스 명령어
find "폴더경로" -name "파일명.zip.part*" -print0 | sort -zt'.' -k2V | xargs -0 cat > "파일명.zip"
- 해당 명령어 실행 시, 실행 경로 위치에 병합 압축 파일이 생성됩니다.
- 병합된 파일 용량이 0일 경우, 제대로 병합이 되지 않은 상태이니 "폴더경로"가 제대로 입력되었는지 확인 부탁드립니다.
※ 데이터셋 소개 페이지에서 다운로드 버튼 클릭하여 승인이 필요합니다.
오프라인 데이터 이용 안내
본 데이터는 K-ICT 빅데이터센터에서도 이용하실 수 있습니다.
다양한 데이터(미개방 데이터 포함)를 분석할 수 있는 오프라인 분석공간을 제공하고 있습니다.
데이터 안심구역 이용절차 및 신청은 K-ICT빅데이터센터 홈페이지를 참고하시기 바랍니다.

국방데이터 개방 안내
본 데이터는 국방데이터로 군사 보안에 따라 AI허브에서 데이터를 제공하지 않으며,
군 담당자를 통한 별도의 사용 신청이 필요합니다.
-
인터넷과 물리적으로 분리된 온라인·오프라인 공간으로 의료 데이터를 포함하여 보안 조치가 요구되는 데이터를 다운로드 없이 접근하고 분석 가능
* 온라인 안심존 : 보안이 보장된 온라인 네트워크를 통해 집, 연구실, 사무실 등 어디서나 접속하여 데이터에 접근하고 분석
* 오프라인 안심존 : 추가적인 보안이 필요한 데이터를 대상으로 지정된 물리적 공간에서만 접속하여 데이터에 접근하고 분석 -
- AI 허브 접속
신청자 - 안심존
사용신청신청자신청서류 제출* - 심사구축기관
- 승인구축기관
- 데이터 분석 활용신청자
- 분석모델반출신청자
- AI 허브 접속
-
1. 기관생명윤리위원회(IRB) 심의 결과 통지서 [IRB 알아보기] [공용IRB 심의신청 가이드라인]
2. 기관생명윤리위원회(IRB) 승인된 연구계획서
3. 신청자 소속 증빙 서류 (재직증명서, 재학증명서, 근로계약서 등 택1)
4. 안심존 이용 신청서 [다운로드]
5. 보안서약서 [다운로드]
※ 상기 신청서 및 첨부 서류를 완비한 후 신청을 진행하셔야 정상적으로 절차가 이루어집니다. -
신청 및 이용관련 문의는 safezone1@aihub.kr 또는 02-525-7708, 7709로 문의