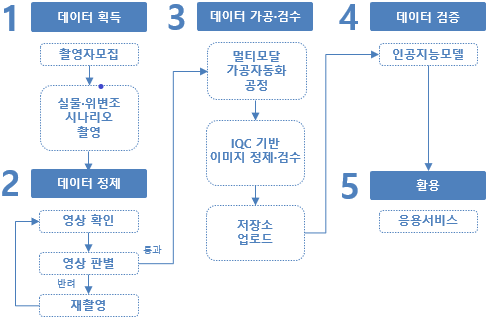
Liveness Detection을 위한 영상
- 분야재난안전환경
- 유형 이미지
-
데이터 변경이력
데이터 변경이력 버전 일자 변경내용 비고 1.0 2021-06-25 데이터 최초 개방 데이터 히스토리
데이터 히스토리 일자 변경내용 비고 2022-10-12 신규 샘플데이터 개방 소개
실제 얼굴이 아닌 안면 사진, 동영상을 이용하거나 얼굴을 본뜬 위조 마스크를 이용한 위변조 공격/탐지 학습용 영상데이터
- 데이터 영역 : 재난안전환경
- 데이터 유형 : 이미지
- 구축년도 : 2020년
- 구축량 : 5.6만
구축목적
얼굴 인식 분야의 위변조 방지를 위한 인공지능 모델 학습
-
구축 내용 및 제공 데이터량
- 1. 데이터 구축 규모
- 카메라별 구축 규모
카메라별 구축 규모 카메라 모달리티유형 대상인원 영상수 스푸핑 공격 종류
(Spoof attacks)Intel RealSense SR305 RGB-Depth-IR 2,007 14,049 Print Intel RealSense D435 RGB-Depth 1,000 21,150 Print, Replay, 3D Mask MS Kinect RGB-IR 1,000 21,150 - 위변조 학습 데이터셋 규모
위변조 학습 데이터셋 규모 목표치 데이터 형식 인원(명) 영상(개) 이미지(개) 3,007명 56,349 4,436,910 - 동영상: bag/mkv
- 이미지: jpg[RGB+Depth+IR]
- 전체 동영상 개수전체 동영상 개수 조명(A) 카메라(B) 공격 유형(C) 1명당 동영상 수량(D)
[D = A x B x C]촬영인원(E) 전체 동영상 개수(F)
{F = D x E)1 1 7(Live 1, Print 6) 7 2,007 14,049 - 전체 이미지 추출 수량
전체 이미지 추출 수량 전체 동영상 개수(F) 동영상당 추출 이미지 개수 (G) 전체 이미지 개수 (H)
(H = F x G x 3(modality))14,049 30 X 3(modality) 1,264,410 - 전체 Masking 이미지 수량
Face segmentation GT는 가공 과정에서 도구를 사용하여 추출된 모든 얼굴 이미지에 대해 Masking 이미지를 생성하는 방식으로 제공된다.전체 Masking 이미지 수량 전체 이미지 개수(H) 이미지당 Masking 이미지 개수(I) 전체 Masking 이미지 개수(J)
(J = H x I)1,260,000 1 1,260,000 [RGB+Depth]
전체 동영상 수량전체 동영상 수량 조명(A) 카메라(B) 공격 유형(C) 1명당 동영상 개수 (D)[D = A x B x C] 촬영 인원(E) 전체 동영상 개수(F) [F = D x E] 3 2 7 (Live 1, Print 4, Replay 2) 21 1,000 21,000
전체 3D MASK 촬영 동영상 수량전체 3D MASK 촬영 동영상 수량 조명(A’) 카메라(B’) 공격 유형(C’) 1명당 동영상 개수 [D’=A’xB’xC’] 촬영 인원(E) 전체 동영상 수량(F’) [F’=D’x ’] 3 1 1(3D Mask) 3 50 150 전체 추출 이미지 수량
전체 추출 이미지 수량 전체 동영상 수량(F) [F“ = F + F’] 동영상당 추출 이미지 수량 (G) 전체 이미지 개수 (H) [H= F x G x 2(modality) 21,150 30 x 2(modality) 1,269,000 전체 Masking 이미지 수량
전체 Masking 이미지 수량 전체 이미지 개수(H) 이미지당 Masking 이미지 개수(I) 전체 Masking 이미지 개수 (J = H x I) 1,269,000 1 1,269,000 [RGB+IR]
전체 동영상 수량전체 동영상 수량 조명(A) 카메라(B) 공격 유형(C) 1명당 동영상 개수 (D)[D = A x B x C] 촬영 인원(E) 전체 동영상 개수(F) [F = D x E] 3 1 7 (Live 1, Print 4, Replay 2) 21 1,000 21,000 전체 3D MASK 촬영 동영상 수량
전체 3D MASK 촬영 동영상 수량 조명(A’) 카메라(B’) 공격 유형(C’) 1명당 동영상 개수 [D’=A’xB’xC’] 촬영 인원(E) 전체 동영상 수량(F’) [F’=D’x ’] 3 1 1(3D Mask) 3 50 150 전체 추출 이미지 수량
전체 추출 이미지 수량 전체 동영상 수량(F) [F“ = F + F’] 동영상당 추출 이미지 수량 (G) 전체 이미지 개수 (H) [H= F x G x 2(modality) 21,150 30 x 3(modality) 1,903,500 전체 Masking 이미지 수량
전체 Masking 이미지 수량 전체 이미지 개수(H) 이미지당 Masking 이미지 개수(I) 전체 Masking 이미지 개수 (J = H x I) 1,903,500 1 1,903,500 데이터셋 용도별 수량 정보
본 데이터셋은 용도(train, validation, testing)에 아래의 비율과 수량으로 할당된다.데이터셋 용도별 수량 정보 Training Validation Testing Total RGB+Depth+IR 할당 비율 80% 10% 10% 100% 구분 촬영대상자 1,605 201 201 2,000 동영상 11,235 1,407 1,407 14,049 정제이미지 1,011,150 126,630 126,630 1,264,410 RGB+Depth 할당 비율 80% 10% 10% 100% 구분 촬영대상자 800 100 100 1,000 동영상 16,920 2,115 2,115 21,150 정제이미지 1,015,200 126,900 126,900 1,269,000 RGB+IR 할당 비율 80% 10% 10% 100% 구분 촬영대상자 800 100 100 1,000 동영상 16,920 2,115 2,115 21,150 정제이미지 1,522,800 190,350 190,350 1,903,500 - 1. 데이터 구축 규모
-
저작도구 설명서 및 저작도구 다운로드
저작도구 다운로드 -
데이터 성능 점수
측정값 (%)기준값 (%)데이터 성능 지표
데이터 성능 지표 번호 측정항목 AI TASK 학습모델 지표명 기준값 점수 측정값 점수 1 멀티모달 기반 안티 스푸핑(Anti-Spoofing) Image Classification CNN TPR@FPR 0.01 92 % 99.86 % 2 멀티모달 기반 안티 스푸핑(Anti-Spoofing) Image Classification CNN TPR@FPR 0.01 92 % 99.7 % 3 멀티모달 기반 안티 스푸핑(Anti-Spoofing) Image Classification CNN TPR@FPR 0.01 92 % 10 %
※ 데이터 성능 지표가 여러 개일 경우 각 항목을 클릭하면 해당 지표의 값이 그래프에 표기됩니다.
※ AI모델 평가 지표에 따라 측정값의 범위, 판단 기준이 달라질 수 있습니다. (ex. 오류율의 경우, 낮을수록 좋은 성능을 내는 것으로 평가됩니다)
-
설명서 및 활용가이드 다운로드
데이터 설명서 다운로드 구축활용가이드 다운로드데이터 변경이력
데이터 변경이력 버전 일자 변경내용 비고 1.0 2021.06.25 데이터 최초 개방 구축 목적
- 얼굴 인식 분야의 위변조 방지를 위한 인공지능 모델 학습
활용 분야
- 프린트, 영상 리플레이, 3D 마스크를 사용한 얼굴 위변조 공격 데이터를 일반 멀티 모달 (RGB, IR, Depth) 카메라를 통해 확보함으로써 face anti-spoofing을 위한 인공지능 모델 학습을 위한 데이터셋을 제공
소개
- 안면 위변조 감지 (Face Recognition Detection) 알고리즘 학습을 위한 멀티모달 데이터셋 구축
‒ 다양한 종류의 안면 위변조 시도 (Face Spoofing) 영상을 생성, 분류하여 데이터셋을 구축함으로써 안면 위변조 감지 (Face Liveness Detection) 알고리즘 학습에 기여
‒ 2.000명 이상의 대상자별로 3가지의 모달리티(RGB, IR, Depth)로 각각 10개 이상의 안면 위변조 시도 영상을 촬영함으로써 총 4만 개 이상의 안면 위변조 감지 알고리즘 학습용 데이터셋 구축
‒ 이를 통해서 글로벌 시장에서 인정받는 안면 위변조 감지 알고리즘 개발을 위한 교두보를 확보함으로써 국내 안면 인식 솔루션들의 국제 경쟁력 강화, 안전하고 편리한 안면 인식 솔루션의 보급확산에 기여함으로써 산업 전반의 경쟁력 강화 도모
구축 내용 및 제공 데이터량
- 1. 데이터 구축 규모
- 카메라별 구축 규모
카메라별 구축 규모 카메라 모달리티유형 대상인원 영상수 스푸핑 공격 종류
(Spoof attacks)Intel RealSense SR305 RGB-Depth-IR 2,007 14,049 Print Intel RealSense D435 RGB-Depth 1,000 21,150 Print, Replay, 3D Mask MS Kinect RGB-IR 1,000 21,150 - 위변조 학습 데이터셋 규모
위변조 학습 데이터셋 규모 목표치 데이터 형식 인원(명) 영상(개) 이미지(개) 3,007명 56,349 4,436,910 - 동영상: bag/mkv
- 이미지: jpg[RGB+Depth+IR]
- 전체 동영상 개수전체 동영상 개수 조명(A) 카메라(B) 공격 유형(C) 1명당 동영상 수량(D)
[D = A x B x C]촬영인원(E) 전체 동영상 개수(F)
{F = D x E)1 1 7(Live 1, Print 6) 7 2,007 14,049 - 전체 이미지 추출 수량
전체 이미지 추출 수량 전체 동영상 개수(F) 동영상당 추출 이미지 개수 (G) 전체 이미지 개수 (H)
(H = F x G x 3(modality))14,049 30 X 3(modality) 1,264,410 - 전체 Masking 이미지 수량
Face segmentation GT는 가공 과정에서 도구를 사용하여 추출된 모든 얼굴 이미지에 대해 Masking 이미지를 생성하는 방식으로 제공된다.전체 Masking 이미지 수량 전체 이미지 개수(H) 이미지당 Masking 이미지 개수(I) 전체 Masking 이미지 개수(J)
(J = H x I)1,260,000 1 1,260,000 [RGB+Depth]
전체 동영상 수량전체 동영상 수량 조명(A) 카메라(B) 공격 유형(C) 1명당 동영상 개수 (D)[D = A x B x C] 촬영 인원(E) 전체 동영상 개수(F) [F = D x E] 3 2 7 (Live 1, Print 4, Replay 2) 21 1,000 21,000
전체 3D MASK 촬영 동영상 수량전체 3D MASK 촬영 동영상 수량 조명(A’) 카메라(B’) 공격 유형(C’) 1명당 동영상 개수 [D’=A’xB’xC’] 촬영 인원(E) 전체 동영상 수량(F’) [F’=D’x ’] 3 1 1(3D Mask) 3 50 150 전체 추출 이미지 수량
전체 추출 이미지 수량 전체 동영상 수량(F) [F“ = F + F’] 동영상당 추출 이미지 수량 (G) 전체 이미지 개수 (H) [H= F x G x 2(modality) 21,150 30 x 2(modality) 1,269,000 전체 Masking 이미지 수량
전체 Masking 이미지 수량 전체 이미지 개수(H) 이미지당 Masking 이미지 개수(I) 전체 Masking 이미지 개수 (J = H x I) 1,269,000 1 1,269,000 [RGB+IR]
전체 동영상 수량전체 동영상 수량 조명(A) 카메라(B) 공격 유형(C) 1명당 동영상 개수 (D)[D = A x B x C] 촬영 인원(E) 전체 동영상 개수(F) [F = D x E] 3 1 7 (Live 1, Print 4, Replay 2) 21 1,000 21,000 전체 3D MASK 촬영 동영상 수량
전체 3D MASK 촬영 동영상 수량 조명(A’) 카메라(B’) 공격 유형(C’) 1명당 동영상 개수 [D’=A’xB’xC’] 촬영 인원(E) 전체 동영상 수량(F’) [F’=D’x ’] 3 1 1(3D Mask) 3 50 150 전체 추출 이미지 수량
전체 추출 이미지 수량 전체 동영상 수량(F) [F“ = F + F’] 동영상당 추출 이미지 수량 (G) 전체 이미지 개수 (H) [H= F x G x 2(modality) 21,150 30 x 3(modality) 1,903,500 전체 Masking 이미지 수량
전체 Masking 이미지 수량 전체 이미지 개수(H) 이미지당 Masking 이미지 개수(I) 전체 Masking 이미지 개수 (J = H x I) 1,903,500 1 1,903,500 데이터셋 용도별 수량 정보
본 데이터셋은 용도(train, validation, testing)에 아래의 비율과 수량으로 할당된다.데이터셋 용도별 수량 정보 Training Validation Testing Total RGB+Depth+IR 할당 비율 80% 10% 10% 100% 구분 촬영대상자 1,605 201 201 2,000 동영상 11,235 1,407 1,407 14,049 정제이미지 1,011,150 126,630 126,630 1,264,410 RGB+Depth 할당 비율 80% 10% 10% 100% 구분 촬영대상자 800 100 100 1,000 동영상 16,920 2,115 2,115 21,150 정제이미지 1,015,200 126,900 126,900 1,269,000 RGB+IR 할당 비율 80% 10% 10% 100% 구분 촬영대상자 800 100 100 1,000 동영상 16,920 2,115 2,115 21,150 정제이미지 1,522,800 190,350 190,350 1,903,500 대표도면
- Live 원본 이미지 예시


- Live Masking 이미지 예시



- Print Attack 원본 이미지 예시



- Print Attack Masking 이미지 예시


















- Replay Attack 원본 이미지 예시


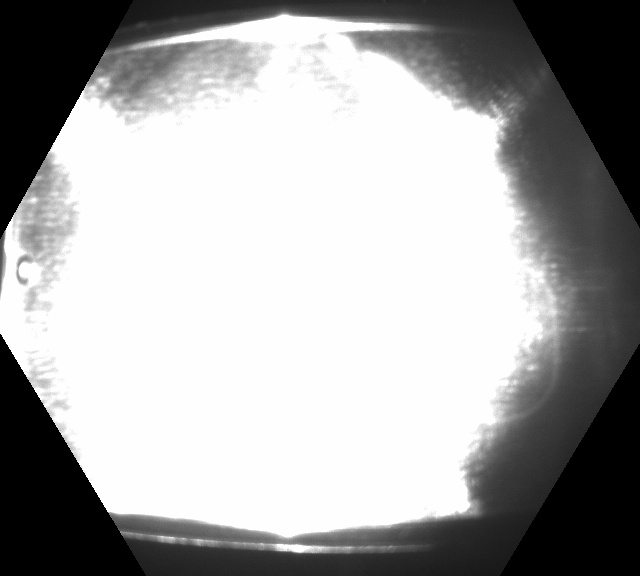
- Replay Attack Masking 이미지 예시



필요성
- 안면인식 시스템에 대한 공격 증가
‒ 안면인식 시스템의 증가에 따라서 정교한 얼굴 도용 및 위변조를 통해서 안면인식 시스템을 무력화하려는 시도도 증가
‒ 이러한 시도를 프레젠테이션 공격 또는 스푸핑(Spoofing)이라고 함
‒ 프레젠테이션 공격(스푸핑)의 종류
⊙ 사진 또는 비디오 공격: 인터넷 또는 개인의 소셜미디어 계정을 통해서 구한 인물 사진 또는 비디오를 이용
⊙ 합성 비디오(Synetic Video) 또는 딥 페이크(Deepfake): 촬영한 사진 또는 비디오를 애니매이션 소프트웨어로 편집함으로써 특정인이 대화하거나 얼굴을 움직이는 모습을 재현
⊙ 모델 및 3D 마스크: 정교하게 타인의 얼굴을 모방한 모델 또는 3D 입체마스크를 제작 착용 - 안면 위변조 감지 (Face Liveness Detection)
‒ 얼굴 인식은 해당 얼굴이 누구인지를 확인하는 과정임에 반해서 안면 위변조 감지는 탐지한 얼굴이 실제 얼굴(Live Face)인지를 확인
‒ 안면 위변조 감지(Face Liveness Detection)가 구현된 안면인식 시스템은 다음과 같은 측면에서 매우 중요하고 유용한 인증 수단임
< 방어적 측면 >
⊙ 얼굴 인증 솔루션 사용 증가에 따라서 정교한 얼굴 도용 및 위조를 통해 안면인식 시스템을 무력화하려는 시도도 증가하므로 이를 차단 또는 방어해야 함
⊙ 얼굴 인식 알고리즘은 얼굴 이미지의 일치 여부는 확인하지만, 라이브 상태의 얼굴 이미지와 그렇지 않은 이미지를 구별해내는 기능은 없음
⊙ 안면 위변조 감지 기능이 없는 얼굴 인증 솔루션을 공개된 장소에서 이용하는 경우 제삼자의 모니터링이 가능하므로 큰 문제가 없으나 스마트폰과 같이 원격에서 이용하는 경우 가짜 계정 생성 및 타인 계정 침해 등 심각한 위험을 초래할 수 있음
< 공세적 측면 >
⊙ 타인 얼굴 사진, 딥페이크 동영상, 가면 또는 분장 등을 통해서 온라인 계정을 생성하거나 액세스하는 것을 원천 봉쇄
⊙ 완벽한 안면 위변조 감지 기능 구현은 가짜 계정 생성, 타인 계정에 대한 불법 또는 대리 접속을 원천적으로 차단할 수 있는 유일한 수단
⊙ 즉, 안면 인증 솔루션과 안면 위변조 감지 기능의 결합하면 얼굴의 라이브니스 여부 확인이 완료된 안면 이미지 데이터는 일회용 키 역할을 하며 접속할 때마다 사용된 적이 없는 새로운 키를 사용하게 되므로 완벽한 계정 보안 달성 가능
‒ 안면 위변조 감지을 위한 데이터셋 부재
⊙ 국내에서 제작된 안면 위변조 감지(Face Liveness Detection) 연구용 공개 데이터셋이 없으며, 해외의 경우에도 19개에 불과
⊙ 대부분의 기존 안면위변조 감지 학습용 데이터셋은 대상자 및 영상의 수가 작은 편임. 즉, 제한된 규모의 연구 외에 실생활에서 적용하기 위한 안면 위변조 감지 알고리즘 연구를 위해서 미흡.
⊙ 한편, CASIA-SURF 데이터셋 2종만이 1,000명 이상의 대상자와 20,000개 이상의 비디오로 구성되어 가장 효과적인 데이터셋으로 인정 받고 있음
⊙ 학습 모델에 사용한 데이터 타입의 수에 따른 결과 수치를 비교해 보면, 단일 모달리티 보다는 CASIA-SURF와 같이 복수개의 모달리티를 활용한 데이터셋의 스푸핑 공격에 대한 검출 능력이 훨씬 뛰어난 것을 확인할 수 있음.필요성 표 Modality TPR(%) APCER(%) NPCER(%) ACER(%) @FPR=10-2 @FPR=10-3 @FPR=10-4 RGB 51.7 27.5 14.6 40.3 1.6 21.0 DEPTH 96.8 86.5 67.3 6.0 1.2 3.6 IR 62.5 29.4 15.9 38.6 0.4 19.4 RGB & DEPTH 97.1 97.5 71.1 5.8 0.8 3.3 RGB * IR 87.4 60.3 37.0 36.5 0.005 18.3 DEPTH & IR 99.4 95.2 81.2 2.0 0.3 1.1 RGB & IR & DEPTH 99.7 97.4 92.4 1.9 0.1 1.0
⊙ SWIR, BRSU, MLFP, WMCA 데이터 셋의 경우도 멀티 모달리티의 데이터셋을 활용하여 개발되었으나, 대상 데이터셋의 크기가 매우 작고 연구실 환경에서의 검증에 가까워 실제 학습 모델로의 적합성이 검증되기 어려움.
⊙ 이러한 이유들로 현재 안면 위변조 감지를 위해 가장 실제 환경에 유사하게 검증된 모델은 CASIA-SURF 가 유일한 모델임.- 안면 위변조 감지(Face Liveness Detection) 연구용 공개 데이터셋의 필요성
‒ 안면 위변조 감지는 안면인식 솔루션의 보안성 및 사용자 경험(User Experience)을 향상시키는 필수 생체 인식 기술
‒ 그러나 해외의 연구기관 및 관련 업체들에 비해서 상대적으로 국내 기술 개발 수준이 뒤처져 있음
‒ 하지만 얼굴 인식 기술에 대한 수요는 급격히 확대되고 있으며 해외 시장 규모도 급성장하고 있으므로 얼굴 인식 기술 상용화의 핵심 요소인 안면 위변조 감지 알고리즘 연구 및 솔루션 개발을 위한 유용한 데이터셋의 확보가 반드시 필요함
데이터 구조
- 1. 데이터 구성
데이터 구성 표 디렉토리 설명 예시 사람식별코드 4자리 고유 일련번호 0001, 0002, ... 카메라모델명 촬영 카메라 모델명 SR305, D435, Kinect 조명식별코드 고조도, 일반조도, 저조도 Light_01_High, Light_02_Mid,
Light_03_low공격식별코드 real/attack
식별코드SR305 real_01,
attack_01_print_eye_flat,
attack_02_print_eye_curved,
attack_03_print_eye_nose_flat
attack_04_print_eye_nose_curved
attack_05_print_eye_nose_mouth_flat
attack_06_print_eye_nose_mouth_curvedD435 real_01,
attack_01_print_none_flat,
attack_02_print_none_curved,
attack_03_print_eye_nose_mouth_flat
attack_04_print_eye_nose_mouth_curved
attack_05_replay_phone
attack_06_replay_tablet
attack_07_3d_maskKinect real_01,
attack_01_print_none_flat,
attack_02_print_none_curved,
attack_03_print_eye_nose_mouth_flat
attack_04_print_eye_nose_mouth_curved
attack_05_replay_phone
attack_06_replay_tablet
attack_07_3d_mask
- 2. 어노테이션 포맷
어노테이션 포맷 표 Tag Name 타입 설명 파일
포맷저장위치 face_box int 얼굴 영역 박스 좌표
(left, top, right, bottom)json 추출된 이미지 디렉토리
(이미지마다 생성됨)version string 메타 파일 버전 정보 json 촬영 대상자 디렉토리 id string 대상자 아이디 sex int 성별 age int 연령대 glasses int 안경(선글라스 포함)유무 mask int 마스크 착용 유무 hat int 모자 착용 유무 3d_mask int 3D 마스크 촬영 여부 Phone string 촬영 스마트폰 Tablet string 촬영 태블릿 Camera string 촬영 일반 카메라 M-Camera string 촬영 멀티모달 카메라
-
데이터셋 구축 담당자
수행기관(주관) : 씨유박스
수행기관(주관) 책임자명 전화번호 대표이메일 담당업무 박준석 02-6277-7835 jspark@cubox.aero - 데이터 구축 및 프로젝트 총괄 수행기관(참여)
수행기관(참여) 기관명 담당업무 (주)인피닉 · 데이터 수집 (주)이스트소프트 · AI 모델 및 응용서비스 개발 고려대학교 DSBA 연구실 · AI 요약모델 개발 한국과학기술연구원 · AI 요약모델 개발 데이터 관련 문의처
데이터 관련 문의처 담당자명 전화번호 이메일 신광철(씨유박스) 02-6277-7836 skc0833@cubox.aero
-
인터넷과 물리적으로 분리된 온라인·오프라인 공간으로 의료 데이터를 포함하여 보안 조치가 요구되는 데이터를 다운로드 없이 접근하고 분석 가능
* 온라인 안심존 : 보안이 보장된 온라인 네트워크를 통해 집, 연구실, 사무실 등 어디서나 접속하여 데이터에 접근하고 분석
* 오프라인 안심존 : 추가적인 보안이 필요한 데이터를 대상으로 지정된 물리적 공간에서만 접속하여 데이터에 접근하고 분석 -
- AI 허브 접속
신청자 - 안심존
사용신청신청자신청서류 제출* - 심사구축기관
- 승인구축기관
- 데이터 분석 활용신청자
- 분석모델반출신청자
- AI 허브 접속
-
1. 기관생명윤리위원회(IRB) 심의 결과 통지서 [IRB 알아보기] [공용IRB 심의신청 가이드라인]
2. 기관생명윤리위원회(IRB) 승인된 연구계획서
3. 신청자 소속 증빙 서류 (재직증명서, 재학증명서, 근로계약서 등 택1)
4. 안심존 이용 신청서 [다운로드]
5. 보안서약서 [다운로드]
※ 상기 신청서 및 첨부 서류를 완비한 후 신청을 진행하셔야 정상적으로 절차가 이루어집니다. -
신청 및 이용관련 문의는 safezone1@aihub.kr 또는 02-525-7708, 7709로 문의
데이터셋 다운로드 승인이 완료 된 후 API 다운로드 서비스를 이용하실 수 있습니다.
API 다운로드 파일은 분할 압축되어 다운로드 됩니다. 분할 압축 해제를 위해서는 분할 압축 파일들의 병합이 필요하며 리눅스 명령어 사용이 필요합니다.
리눅스 OS 계열에서 다운로드 받으시길 권장하며 윈도우에서 파일 다운로드 시 wsl(리눅스용 윈도우 하위 시스템) 설치가 필요합니다.
※ 파일 병합 리눅스 명령어
find "폴더경로" -name "파일명.zip.part*" -print0 | sort -zt'.' -k2V | xargs -0 cat > "파일명.zip"
- 해당 명령어 실행 시, 실행 경로 위치에 병합 압축 파일이 생성됩니다.
- 병합된 파일 용량이 0일 경우, 제대로 병합이 되지 않은 상태이니 "폴더경로"가 제대로 입력되었는지 확인 부탁드립니다.
※ 데이터셋 소개 페이지에서 다운로드 버튼 클릭하여 승인이 필요합니다.
오프라인 데이터 이용 안내
본 데이터는 K-ICT 빅데이터센터에서도 이용하실 수 있습니다.
다양한 데이터(미개방 데이터 포함)를 분석할 수 있는 오프라인 분석공간을 제공하고 있습니다.
데이터 안심구역 이용절차 및 신청은 K-ICT빅데이터센터 홈페이지를 참고하시기 바랍니다.

국방데이터 개방 안내
본 데이터는 국방데이터로 군사 보안에 따라 AI허브에서 데이터를 제공하지 않으며,
군 담당자를 통한 별도의 사용 신청이 필요합니다.