-
데이터 변경이력
데이터 변경이력 버전 일자 변경내용 비고 1.0 2021-06-18 데이터 최초 개방 데이터 히스토리
데이터 히스토리 일자 변경내용 비고 2022-10-12 신규 샘플데이터 개방 소개
고서 한자 이미지를 인식하기 위한 이미지 데이터
구축목적
한자로 기록된 국가기록유산(고서, 고문헌 등)의 활용성과 접근성 향상을 위해 고서 이미지 속 한자의 디지털 텍스트를 자동으로 확보하기 위한 인공지능 기반 OCR 기술 개발용 학습 데이터
-
메타데이터 구조표 데이터 영역 한국어 데이터 유형 텍스트 , 이미지 데이터 형식 데이터 출처 라벨링 유형 라벨링 형식 데이터 활용 서비스 데이터 구축년도/
데이터 구축량2020년/1000만 -
구축 내용 및 제공 데이터량
- 주데이터 : 고서 한자 인식(OCR) AI 학습데이터 10,142,816건(자)
제공 형태 : 고서 한자 원문이미지 파일 57,081개(JPEG), 고서 한자 라벨링 파일 57,081개(JSON)의 쌍
- 보조데이터① : 고서 한자 바운딩박스(세그먼테이션) 학습데이터 10,142,816건(자)
제공 형태 : 고서 한자 원문이미지 파일 57,081개(JPEG)과 고서 한자 바운딩박스 파일 57,081개(JSON)의 쌍 중간 산출물로서 고서 한자 이미지 상의 한자를 인지하여 바운딩박스까지 생성된 라벨링(입력) 전 파일
- 보조데이터② : 고서 한자 클러스터링 학습데이터 97건
제공 형태 : 고서 한자 클러스터링 파일 97개 (JSON) 중간 산출물로서 고서 한자 이미지 상의 한자를 인지하여 바운딩박스를 생성한 후 동일 한자 바운딩박스들을 클러스터링한 파일 한자 바운딩박스(세그먼트) 10,142,816개(자)에 대한 클러스터링 내역
- 주데이터 : 고서 한자 인식(OCR) AI 학습데이터 10,142,816건(자)
-
-
AI 모델 상세 설명서 다운로드
AI 모델 다운로드 -
데이터 성능 점수
측정값 (%)기준값 (%)데이터 성능 지표
데이터 성능 지표 번호 측정항목 AI TASK 학습모델 지표명 기준값 점수 측정값 점수 1 한자 객체 검출 정확도 Object Detection HRCenterNet F1-Score@IoU 0.8 0.8 점 0.89 점
※ 데이터 성능 지표가 여러 개일 경우 각 항목을 클릭하면 해당 지표의 값이 그래프에 표기됩니다.
※ AI모델 평가 지표에 따라 측정값의 범위, 판단 기준이 달라질 수 있습니다. (ex. 오류율의 경우, 낮을수록 좋은 성능을 내는 것으로 평가됩니다)
-
설명서 및 활용가이드 다운로드
데이터 설명서 다운로드 구축활용가이드 다운로드데이터 변경이력
데이터 변경이력 버전 일자 변경내용 비고 1.0 2021.06.18 데이터 최초 개방 구축 목적
- 한자로 기록된 국가기록유산(고서, 고문헌 등)의 활용성과 접근성 향상을 위해 고서 이미지 속 한자의 디지털 텍스트를 자동으로 확보하기 위한 인공지능 기반 OCR 기술 개발용 학습 데이터
활용 분야
- 인공지능 학습을 통해 고서 이미지 속 한자의 디지털 텍스트 자동으로 확보하는 기술 및 솔루션의 개발과 고서 이미지를 활용한 다양한 검색과 한문 자동번역 등의 2차 서비스 개발
소개
- 현존 고문헌의 대부분을 차지하고 있는 조선시대 고서의 원문 한자를 AI 기반의 OCR 기술을 통해 디지털 텍스트로 자동 확보하기 위하여, 고서 원문 내의 각 낱자 한자들에 대한 바운딩박스와 라벨링(유니코드 한자) 정보로 구성된 JSON 파일과 해당 고서 원문이미지 파일의 쌍으로 구성된 한자 글자수 기준 1천만 자 규모의 고서 한자 인식(OCR) AI 학습용 데이터셋
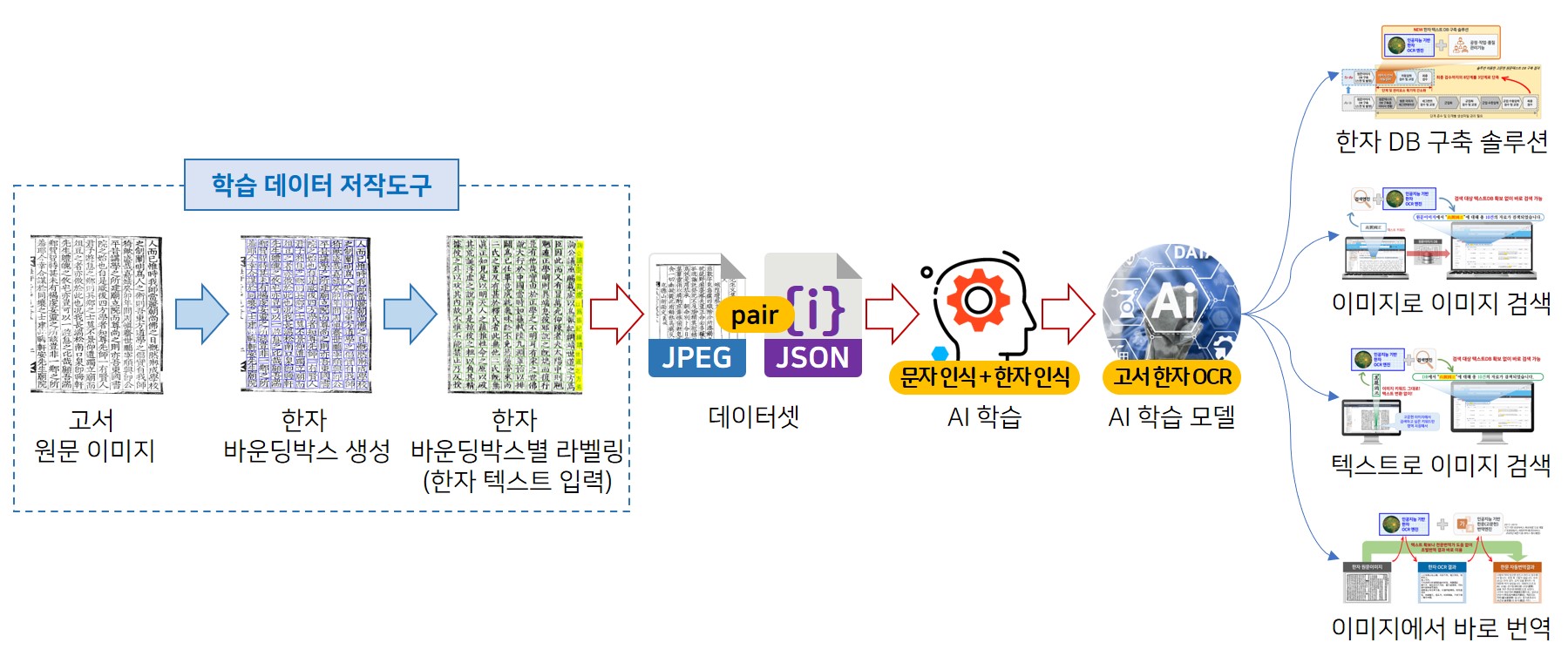
<데이터셋 구축・활용 개념도>
구축 내용 및 제공 데이터량
- 주데이터 : 고서 한자 인식(OCR) AI 학습데이터 10,142,816건(자)
제공 형태 : 고서 한자 원문이미지 파일 57,081개(JPEG), 고서 한자 라벨링 파일 57,081개(JSON)의 쌍
- 보조데이터① : 고서 한자 바운딩박스(세그먼테이션) 학습데이터 10,142,816건(자)
제공 형태 : 고서 한자 원문이미지 파일 57,081개(JPEG)과 고서 한자 바운딩박스 파일 57,081개(JSON)의 쌍 중간 산출물로서 고서 한자 이미지 상의 한자를 인지하여 바운딩박스까지 생성된 라벨링(입력) 전 파일
- 보조데이터② : 고서 한자 클러스터링 학습데이터 97건
제공 형태 : 고서 한자 클러스터링 파일 97개 (JSON) 중간 산출물로서 고서 한자 이미지 상의 한자를 인지하여 바운딩박스를 생성한 후 동일 한자 바운딩박스들을 클러스터링한 파일 한자 바운딩박스(세그먼트) 10,142,816개(자)에 대한 클러스터링 내역
대표도면
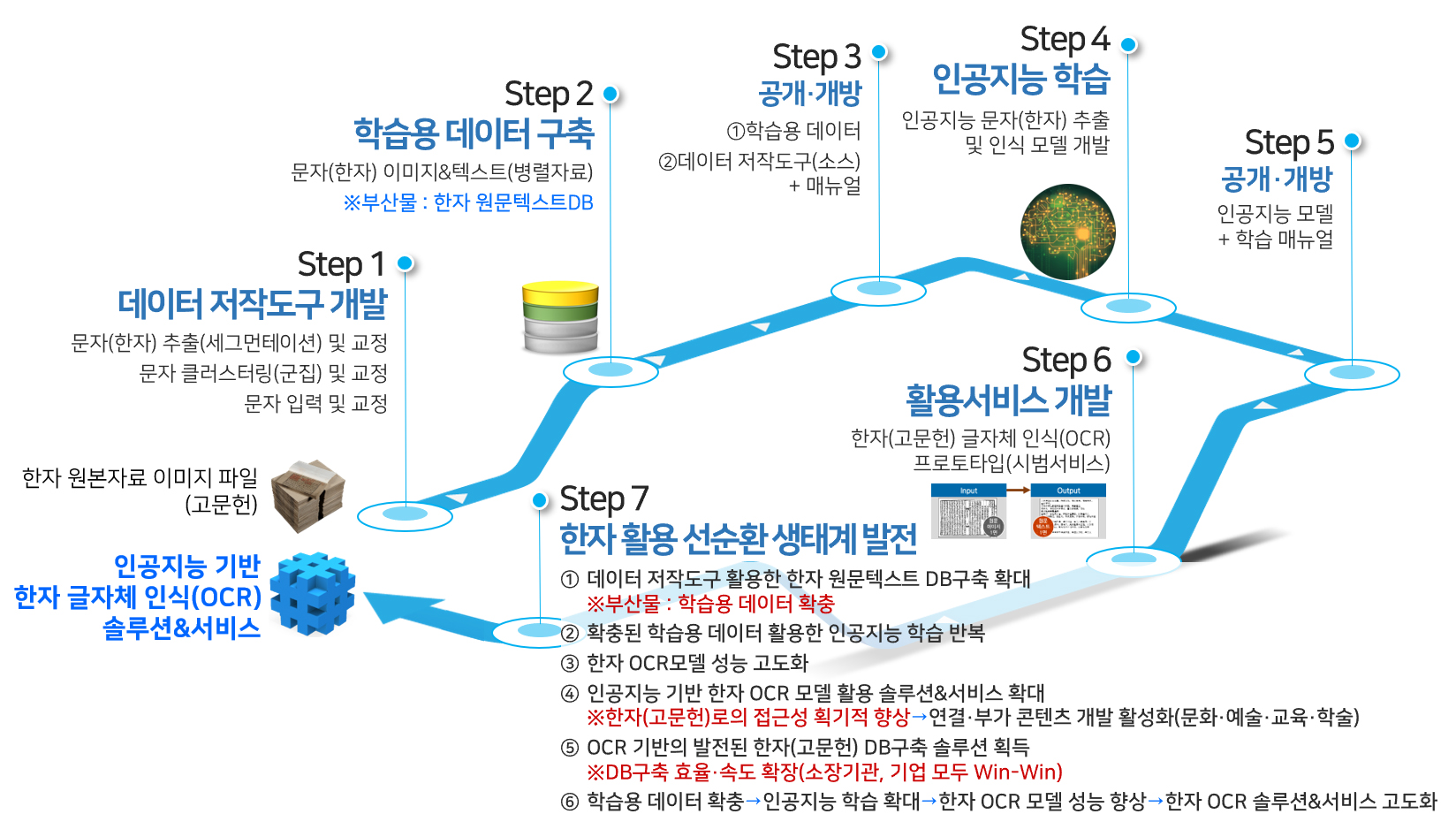
<고서 한자 활용 선순환 생태계>
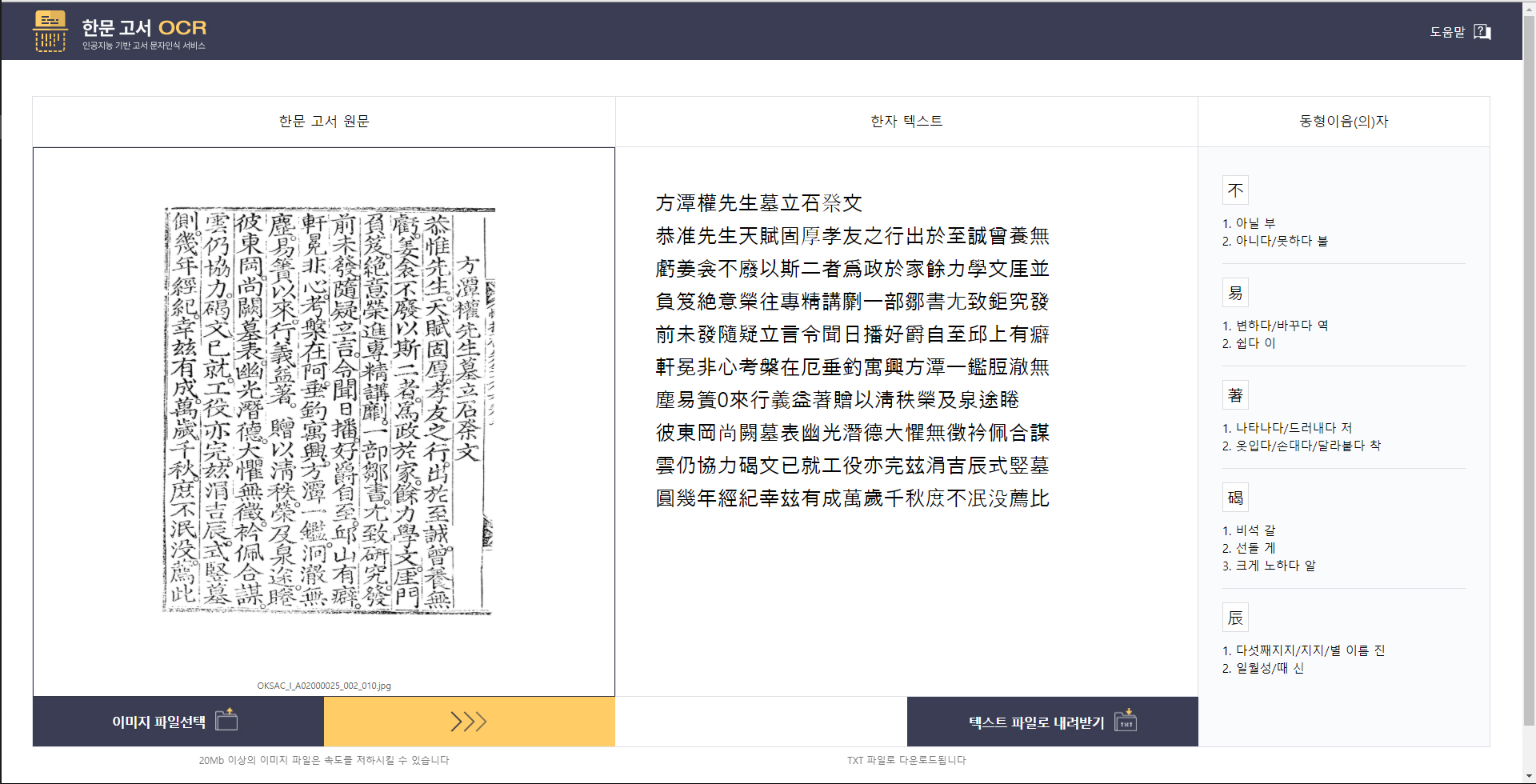
<고서 한자 인식(OCR) AI 모델 활용 시범 서비스>
필요성
- 한자(고문헌)는 정치・경제・사회・문화・예술・과학・의학・사상・종교 등 다방면에서 우리 민족의 과거와 지식을 담고 있는 매우 중요한 기록유산이지만 한자라는 거대한 장벽에 가로막혀 활용에 어려움을 겪는 대표적 문화자원이며 활용 가치가 매우 큰 콘텐츠의 보고로서, 여러 분야에서 현대적으로 재해석된 콘텐츠로 개발에 성공하여 사회적 관심과 수요가 급격히 증가하고 있음 우리나라는 민・관에서 매년 많은 양의 한자(고문헌) DB를 구축해오고 있으나 OCR을 활용한 한자 텍스트 추출・변환 기술이 미비(극소수 인력이 수작업을 통해 한자를 판독하여 구축)하여 대부분 원문이미지만을 제공하는 것에 그치고 있어, 한자-한글 자동번역, 한자 콘텐츠에 대한 검색 및 분석 등의 활용이 어려움
최근에는 국내 한자 사용 인구(중국, 일본 등의 국내 거주자, 관광객) 증가로 한자 간판 인식을 통한 위치 서비스, 한자 매뉴얼 사용 등의 생활 속 서비스에서 한자 콘텐츠 사용이 급격히 증가하고 있어 최신 인공지능 기술을 활용하여 한자 서비스를 개발하기 위한 인공지능 학습용 데이터 수요가 증가하고 있음 - 현재 한자(고문헌) 자료의 디지털 텍스트 구축에 사용되고 있는 솔루션은 20년 전 기술로 개발되어 여러 단계(8단계)의 필수과정을 거쳐야 하고 각 단계에는 한자 전문인력뿐만 아니라 숙련된 작업인력을 양성하여 투입해야 하는 등의 한계를 안고 있어 디지털 텍스트 확보에 소요되는 인력, 시간, 비용 절감에 대한 요구가 관련 분야에서 지속적으로 제기되어 왔으나, 기술적 미비로 해결이 지연되어 옴. 최근 비약적인 성능 향상을 보이고 있는 인공지능을 활용하여 한자 텍스트 인식(OCR) 기술을 개발하기 위한 인공지능 학습용 한자 데이터 구축이 절실하게 필요함
- 불가능의 영역으로 인식되던 인공지능 고문헌 자동번역의 현실화가 눈앞에 있는 상황에서 여러 제약조건으로 대부분 단순 원본 스캐닝을 통한 보전 단계에 머무르고 있는 한자(고문헌)의 실효적인 이용 활성화와 현대에서 요구되는 한자 서비스를 위해서, 비약적으로 발전하고 있는 인공지능과 최신 ICT 기반의 ‘한자 글자체 인식(OCR) 기술’ 확보와 이를 위한 ‘인공지능 학습용 데이터 구축’이 필수 당면과제로 대두됨
- 또한 현재 사용되고 있는 대부분의 한자 인식(OCR) 소프트웨어가 외산 제품으로서 관련 국내 산업의 활성화와 콘텐츠 보호 등을 위해 국산 SW와 파생 기술 및 서비스 개발을 위한 인공지능 학습용 데이터 구축이 절실하게 요구됨
데이터 구조
- 주데이터 : 고서 한자 인식(OCR) AI 학습데이터
- 가. 데이터 구성
- 나. 어노테이션 포맷
※ 1~18번은 동일 레벨 데이터. 18번 하위로만 계층을 갖는 데이터어노테이션 포맷 표1 No. 항목 길이 타입 필수
여부한글명 영문명 1 데이터셋정보 Info 1 데이터셋명 Info_Name 128 String O 2 데이터셋설명 Info_Description 1024 String 3 데이터셋생성일자 Info_Data_created 16 String O 4 판본 정보 Info_Block 128 String 5 글자체 정보 Info_Style 128 String 6 이미지라이선스 Info_Image_License 128 String O 7 라이선스소유기관 Info_Licenced_Institution 128 String O 8 라이선스소유기관URL Info_Institution_URL 128 String 2 이미지정보 Image 9 이미지식별자 Image_ID 128 String O 10 이미지파일명 Image_File_name 128 String O 11 이미지생성일자 Image_Data_captured 16 String O 12 이미지너비 Image_Width 4 Number O 13 이미지높이 Image_Height 4 Number O 14 해상도 Image_dpi 4 Number 15 컬러이미지 Image_color 1 String 16 문자 열 최고 갯수 Image_Char_col_no 4 Number 17 문자 행 최고 갯수 Image_Char_row_no 4 Number 18 문자위치BOX리스트 Image_Text_coord List O 18-1-1 BOX좌상단 X좌표 X 4 Number O 18-1-2 BOX좌상단 Y좌표 Y 4 Number O 18-1-3 BOX 너비 Width 4 Number O 18-1-4 BOX 높이 Height 4 Number O 18-1-5 문자 열 정보 col_no 4 Number 18-1-6 문자 행 정보 row_no 4 Number 18-2 인식문자 Unicode 1 String O
- 보조데이터① : 고서 한자 바운딩박스(세그먼테이션) 학습데이터
- 가. 데이터 구성
- 나. 어노테이션 포맷
※ 1~16번은 동일 레벨 데이터. 16번 하위로만 계층을 갖는 데이터어노테이션 포맷 표2 No. 항목 길이 타입 필수
여부한글명 영문명 1 데이터셋정보 Info 1 데이터셋명 Info_Name 128 String O 2 데이터셋설명 Info_Description 1024 String 3 데이터셋생성일자 Info_Data_created 16 String O 4 판본 정보 Info_Block 128 String 5 글자체 정보 Info_Style 128 String 6 이미지라이선스 Info_Image_License 128 String O 7 라이선스소유기관 Info_Licenced_Institution 128 String O 8 라이선스소유기관URL Info_Institution_URL 128 String 2 이미지정보 Image 9 이미지식별자 Image_ID 128 String O 10 이미지파일명 Image_File_name 128 String O 11 이미지생성일자 Image_Data_captured 16 String O 12 이미지너비 Image_Width 4 Number O 13 이미지높이 Image_Height 4 Number O 14 해상도 Image_dpi 4 Number 15 컬러이미지 Image_color 1 String 16 문자위치BOX리스트 Image_bboxes List O 16-1 BOX좌상단 X좌표 X 4 Number O 16-2 BOX좌상단 Y좌표 Y 4 Number O 16-3 BOX 너비 Width 4 Number O 16-4 BOX 높이 Height 4 Number O
- 보조데이터② : 고서 한자 클러스터링 학습데이터
- 가. 데이터 구성
- 나. 어노테이션 포맷
※ 1~10번은 동일 레벨 데이터
※ 9번, 10번 하위로만 계층을 갖는 데이터어노테이션 포맷 표3 No. 항목 길이 타입 필수
여부한글명 영문명 1 데이터셋정보 Info 1 데이터셋명 Info_Name 128 String O 2 데이터셋설명 Info_Description 1024 String 3 데이터셋생성일자 Info_Data_created 16 String O 4 판본 정보 Info_Block 128 String 5 글자체 정보 Info_Style 128 String 6 이미지라이선스 Info_Image_License 128 String O 7 라이선스소유기관 Info_Licenced_Institution 128 String O 8 라이선스소유기관URL Info_Institution_URL 128 String 2 세그먼트 이미지 정보 ID Segment Lists 9 ID 세그먼트 리스트 ID_Segment_Lists Lists O 9-1 세그먼트 ID Segment ID 4 Number O 9-2 이미지파일명 File Name 128 String O 9-3 BOX좌상단 X좌표 X 4 Number O 9-4 BOX좌상단 Y좌표 Y 4 Number O 9-5 BOX 너비 Width 4 Number O 9-6 BOX 높이 Height 4 Number O 3 클러스터 정보 Cluster 10 클러스터 리스트 Cluster_Lists Lists 10-1 대표 ID Representitive_ID 4 Number O 10-2 클러스터 ID 리스트 bbox_ids ID List O 10-3 클러스터문자 text 1 String
-
데이터셋 구축 담당자
수행기관(주관) : 누리IDT
수행기관(주관) 책임자명 전화번호 대표이메일 담당업무 김현진 02-2631-5331 kim9395@nuriidt.co.kr · 데이터구축 총괄 · AI 모델활용 시범서비스 개발 수행기관(참여)
수행기관(참여) 기관명 담당업무 (주)NHN다이퀘스트 · 저작도구 개발
· 한자이미지 처리기술 개발한국국학진흥원 · 대상자료 수집/제공/분석/확정
· 품질검수(주)에프아이솔루션 · 학습데이터 구축 데이터 관련 문의처
데이터 관련 문의처 담당자명 전화번호 이메일 김현진(누리IDT) 02-2631-5331 kim9395@nuriidt.co.kr
-
인터넷과 물리적으로 분리된 온라인·오프라인 공간으로 의료 데이터를 포함하여 보안 조치가 요구되는 데이터를 다운로드 없이 접근하고 분석 가능
* 온라인 안심존 : 보안이 보장된 온라인 네트워크를 통해 집, 연구실, 사무실 등 어디서나 접속하여 데이터에 접근하고 분석
* 오프라인 안심존 : 추가적인 보안이 필요한 데이터를 대상으로 지정된 물리적 공간에서만 접속하여 데이터에 접근하고 분석 -
- AI 허브 접속
신청자 - 안심존
사용신청신청자신청서류 제출* - 심사구축기관
- 승인구축기관
- 데이터 분석 활용신청자
- 분석모델반출신청자
- AI 허브 접속
-
1. 기관생명윤리위원회(IRB) 심의 결과 통지서 [IRB 알아보기] [공용IRB 심의신청 가이드라인]
2. 기관생명윤리위원회(IRB) 승인된 연구계획서
3. 신청자 소속 증빙 서류 (재직증명서, 재학증명서, 근로계약서 등 택1)
4. 안심존 이용 신청서 [다운로드]
5. 보안서약서 [다운로드]
※ 상기 신청서 및 첨부 서류를 완비한 후 신청을 진행하셔야 정상적으로 절차가 이루어집니다. -
신청 및 이용관련 문의는 safezone1@aihub.kr 또는 02-525-7708, 7709로 문의
데이터셋 다운로드 승인이 완료 된 후 API 다운로드 서비스를 이용하실 수 있습니다.
API 다운로드 파일은 분할 압축되어 다운로드 됩니다. 분할 압축 해제를 위해서는 분할 압축 파일들의 병합이 필요하며 리눅스 명령어 사용이 필요합니다.
리눅스 OS 계열에서 다운로드 받으시길 권장하며 윈도우에서 파일 다운로드 시 wsl(리눅스용 윈도우 하위 시스템) 설치가 필요합니다.
※ 파일 병합 리눅스 명령어
find "폴더경로" -name "파일명.zip.part*" -print0 | sort -zt'.' -k2V | xargs -0 cat > "파일명.zip"
- 해당 명령어 실행 시, 실행 경로 위치에 병합 압축 파일이 생성됩니다.
- 병합된 파일 용량이 0일 경우, 제대로 병합이 되지 않은 상태이니 "폴더경로"가 제대로 입력되었는지 확인 부탁드립니다.
※ 데이터셋 소개 페이지에서 다운로드 버튼 클릭하여 승인이 필요합니다.