-
데이터 변경이력
데이터 변경이력 버전 일자 변경내용 비고 1.2 2022-12-01 라벨링데이터 수정 1.1 2022-09-01 데이터 품질 보완 1.0 2022-07-12 데이터 최초 개방 데이터 히스토리
데이터 히스토리 일자 변경내용 비고 2025-05-08 구축업체정보 수정 2022-07-12 콘텐츠 최초 등록 소개
해외 주요국 영문 특허명세서를 전문가(변리사)가 관여한 한국어 번역, KSIC(표준산업분류) 라벨링 및 기술용어를 태깅한 데이터셋으로, 기술적 관점의 국제특허분류(IPC, International Patent Classification)가 아닌 통계청에 고시하고 있는 표준산업분류를 연계한 데이터를 통해 기술, 경제, 산업 간 유기적 구성 및 상관성 비교 · 분석이 가능한 산업정보 연계 주요국 특허의 인공지능 학습용 DB를 구축함.
구축목적
해외 주요국 (미국, 유럽, 일본, 중국) 특허명세서의 주요 내용을 번역하여, 해당되는 산업분야, 관련 기술용어 등으로 구성된 총 200만 문장 이상, 특허 40만 건의 데이터 셋 (특허 자동 산업분류 인공지능기술 개발을 위한 학습용 데이터) 구축
-
메타데이터 구조표 데이터 영역 한국어 데이터 유형 텍스트 데이터 형식 JSON 데이터 출처 특허청(키프리스플러스 API) 라벨링 유형 한국표준산업분류 라벨링 형식 JSON 데이터 활용 서비스 특허 명세서 산업분류 & 기술용어 추출 서비스 데이터 구축년도/
데이터 구축량2021년/40만건 -
1. 데이터 구축 규모
1. 데이터 구축 규모 데이터 종류 데이터 형태 원천 데이터 규모 라벨링 데이터 규모 비고 KSIC 기술용어 태깅 라벨링 특허 명세서 텍스트 미국 : 100,000 100,000 100,000 KSIC 라벨링 (JSON) 일본 : 100,000 100,000 100,000 - 국가별 10%의 특허에 대해 최소 3개의 KSIC를 라벨링함 유럽 : 100,000 100,000 100,000 기술용어 태깅 중국 : 100,000 100,000 100,000 - 국가별 10%의 특허에 대해 7개 이상의 기술 용어 생성 총계 400,000 2. 데이터 분포
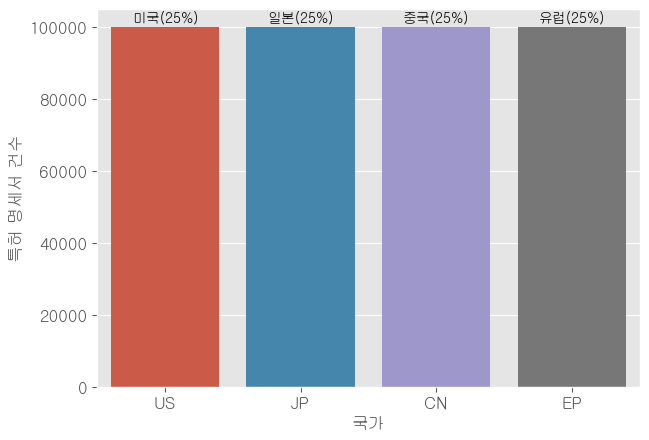
- 국가별 분포
국가별 분포 구분 특허 명세서 건수 비율 미국 100,000 25% 일본 100,000 25% 유럽 100,000 25% 중국 100,000 25% 합계 400,000 100%
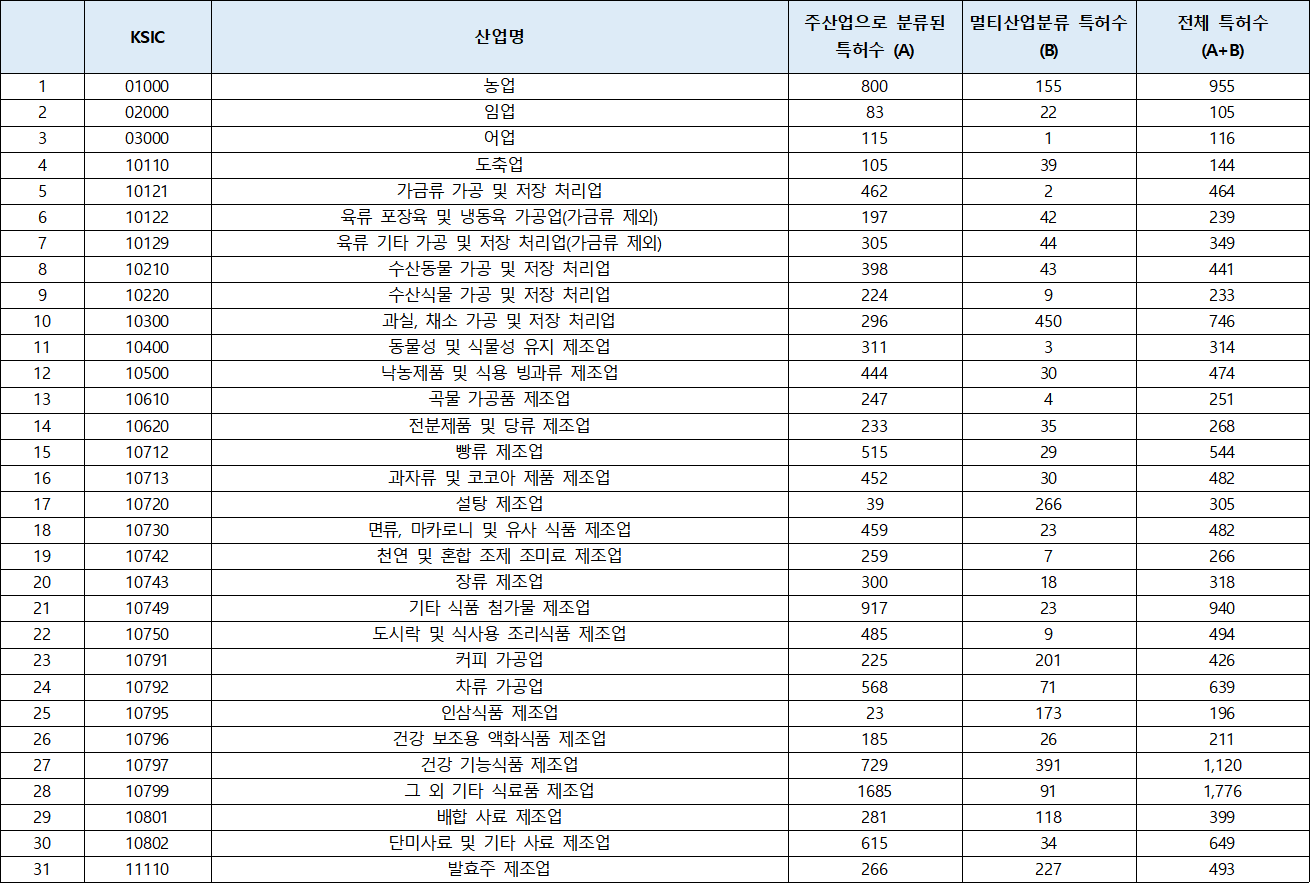
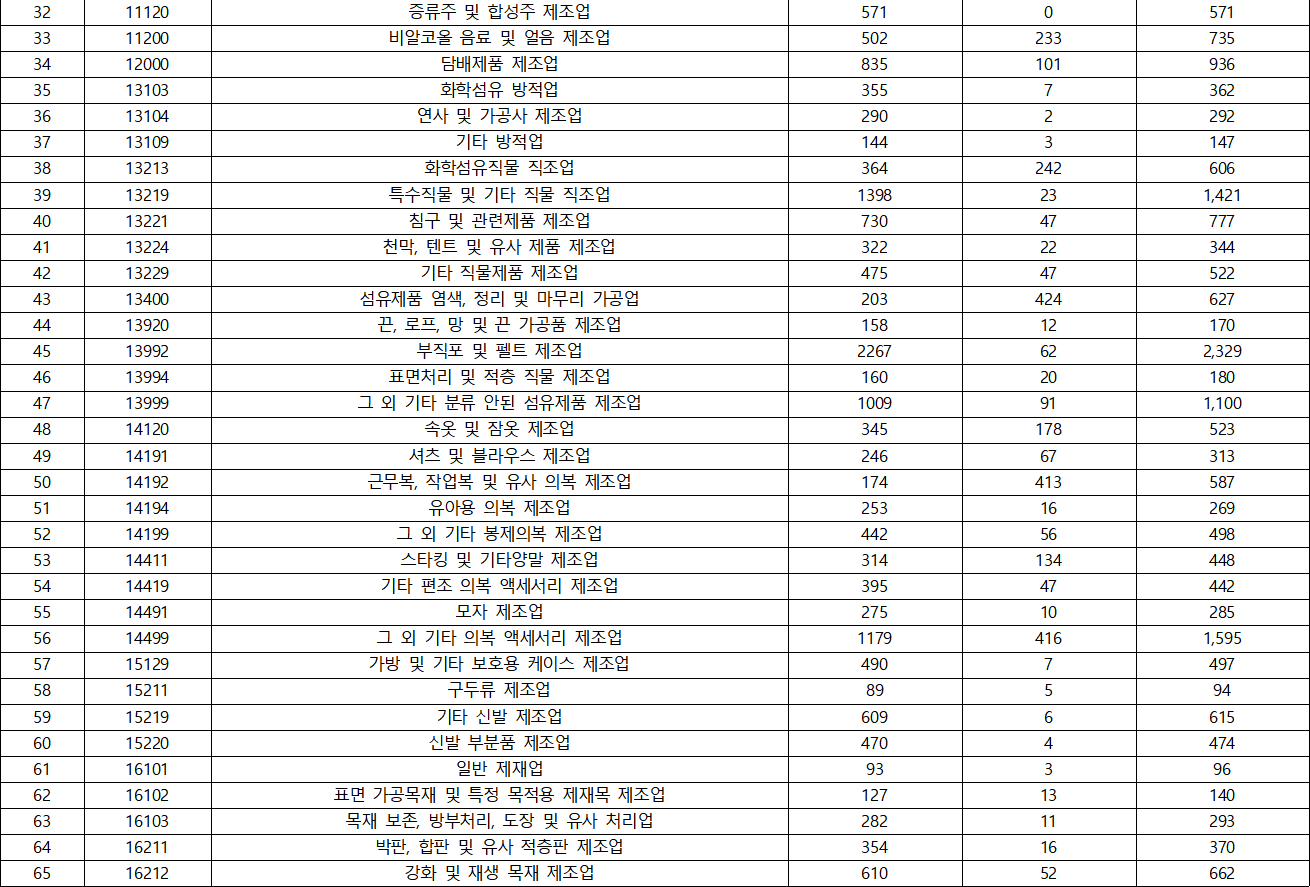
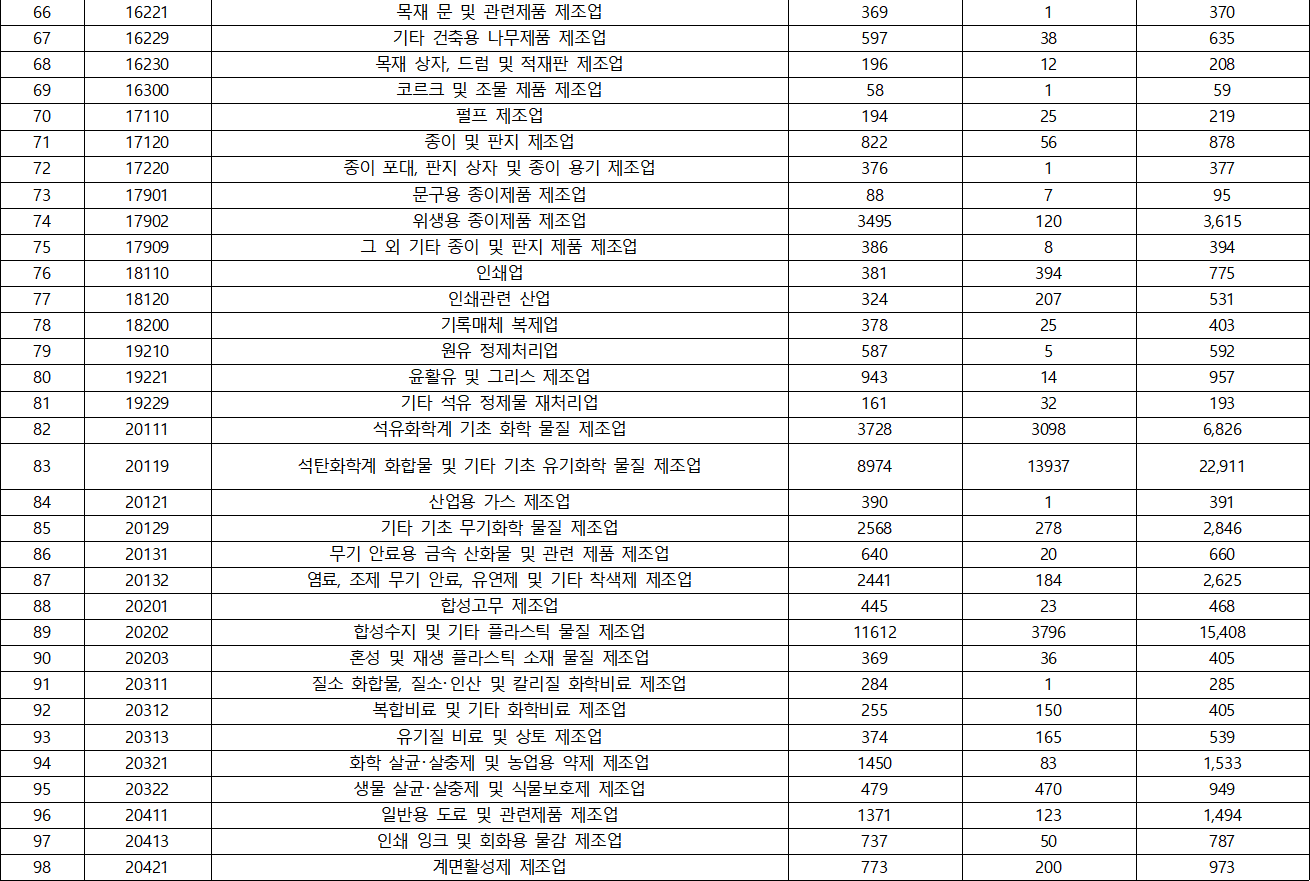
- KSIC(표준산업분류) 분포
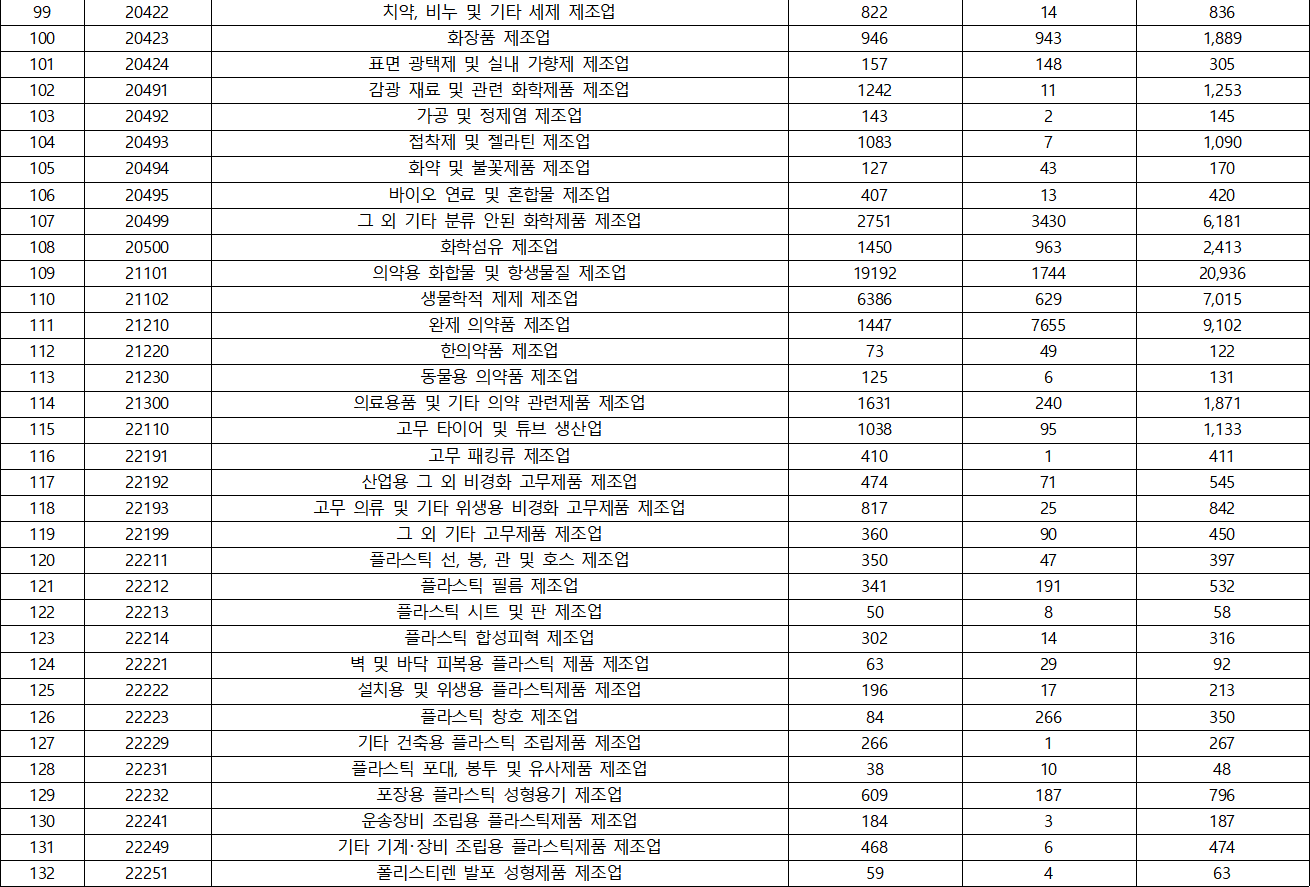
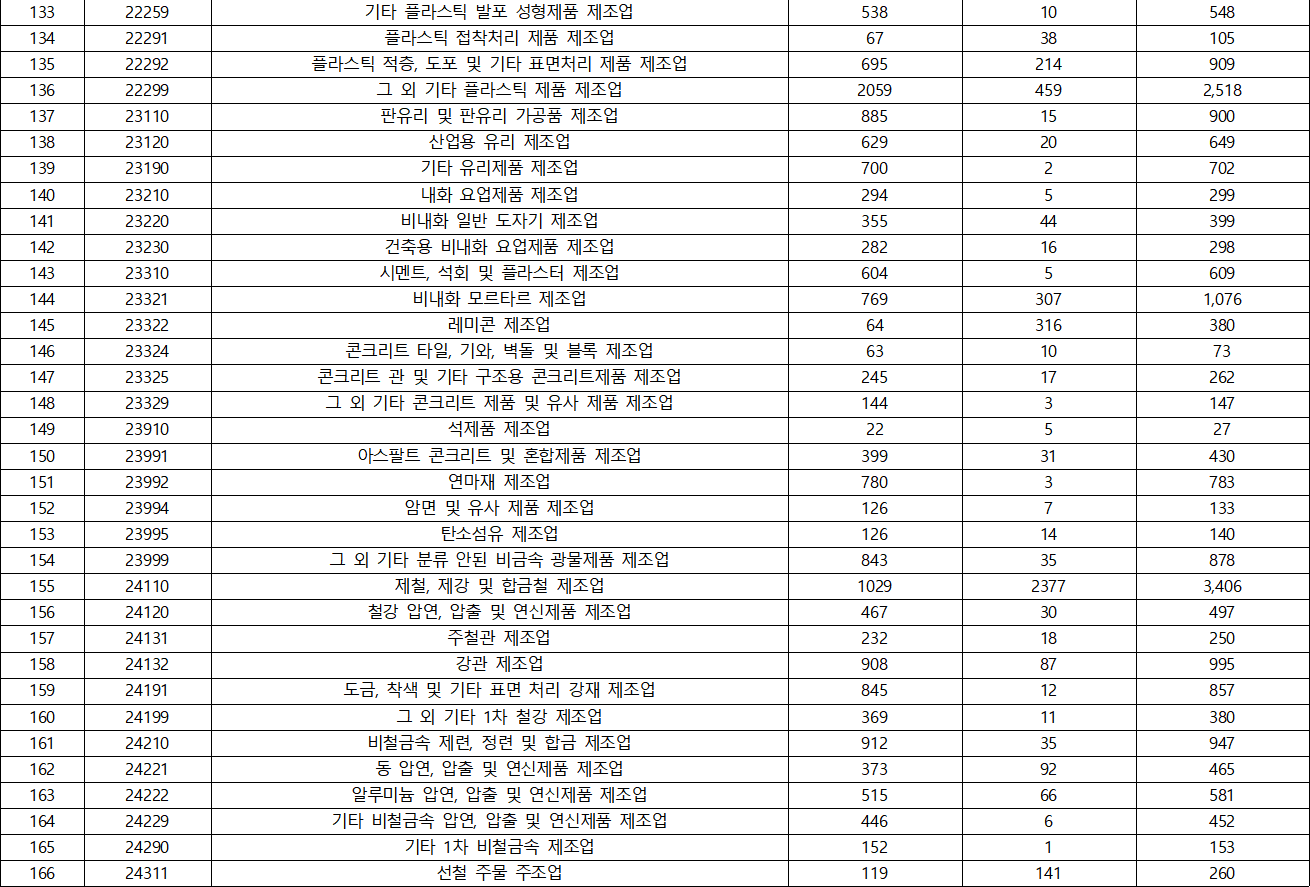
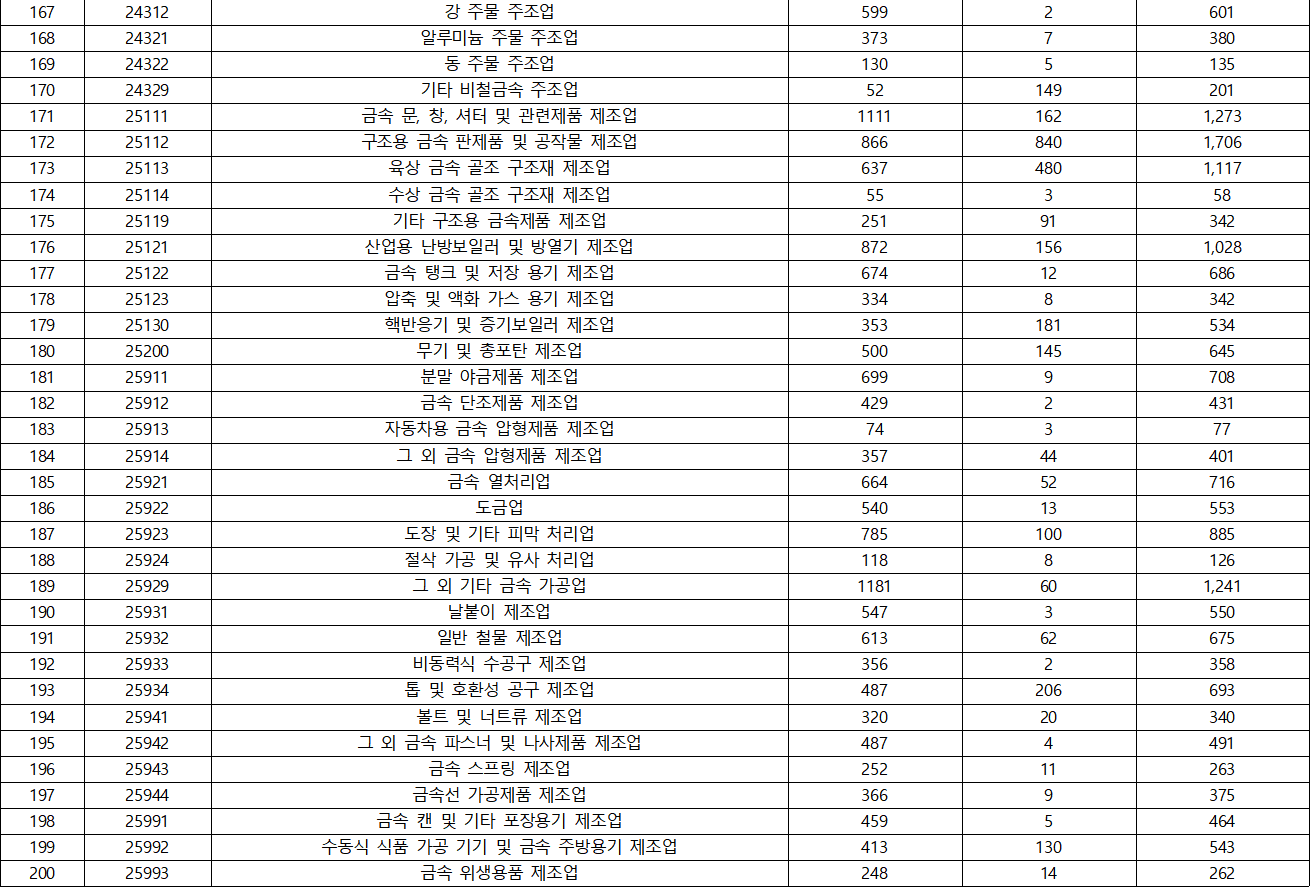
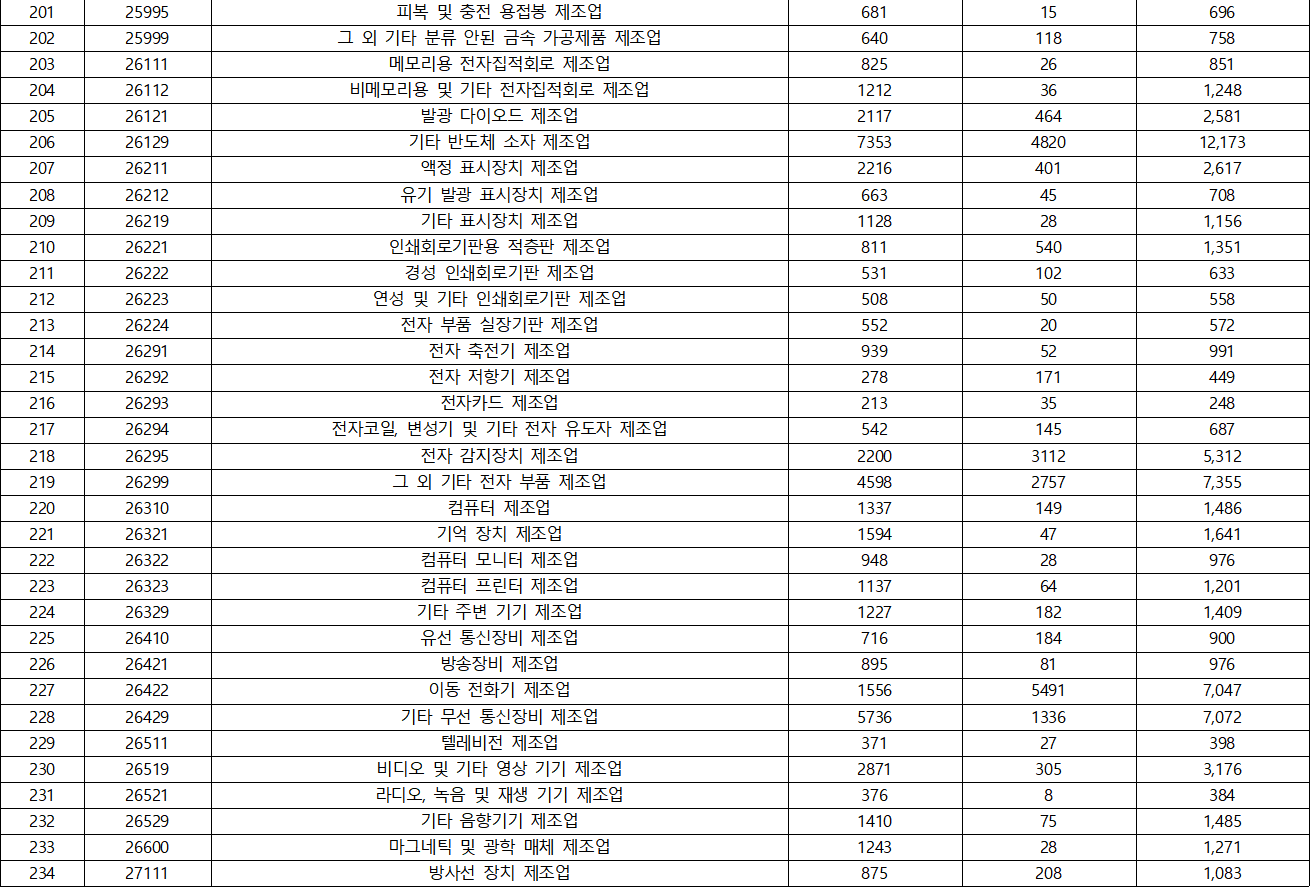
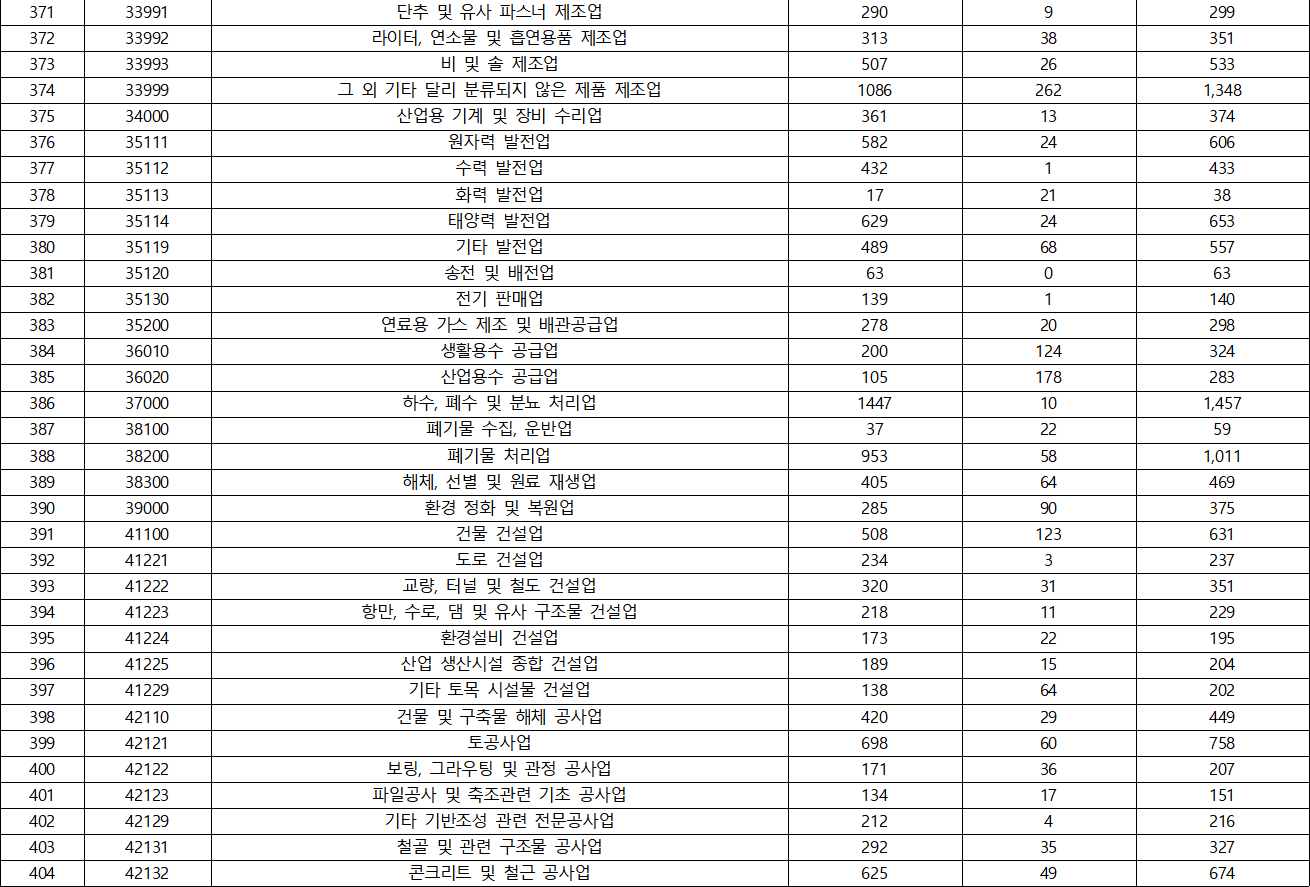
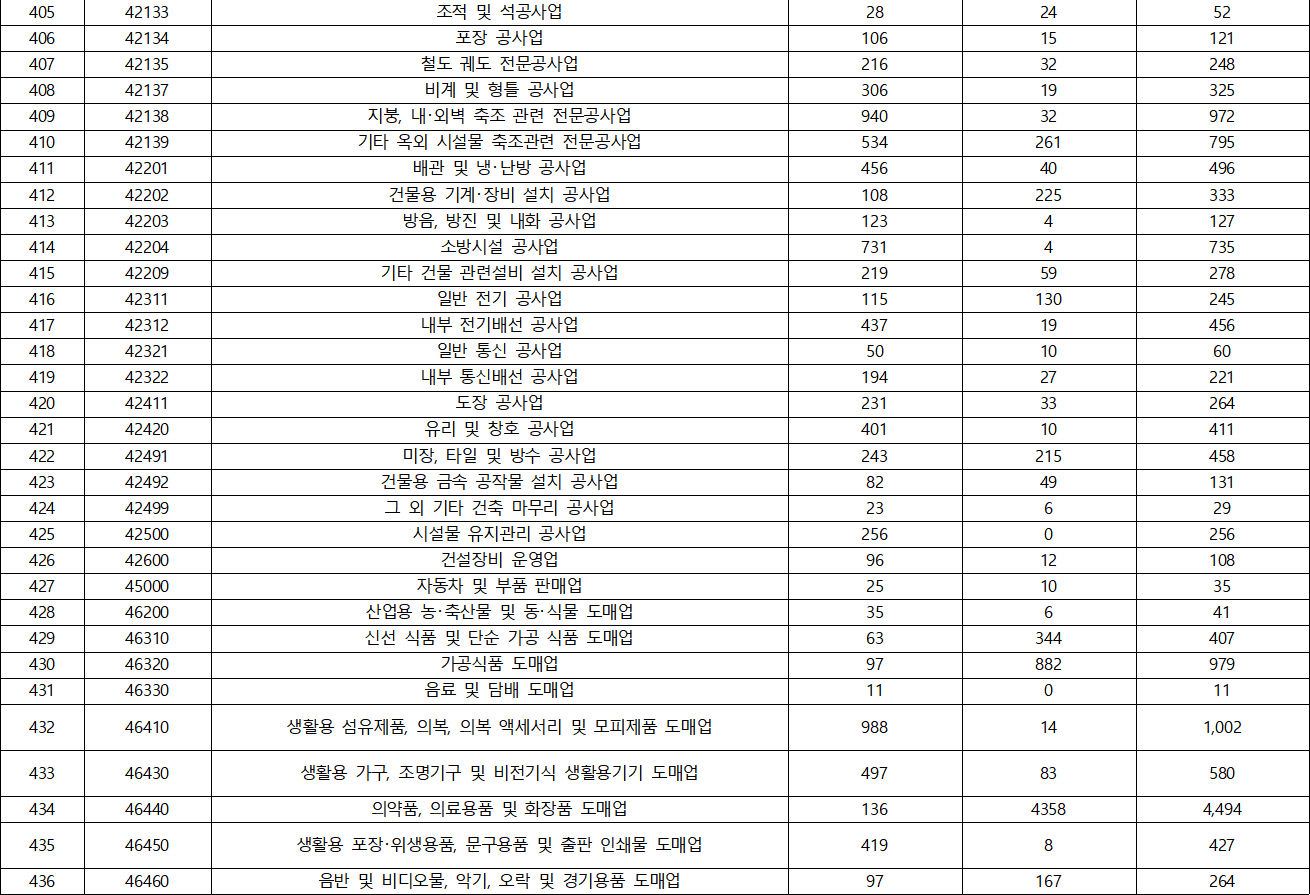
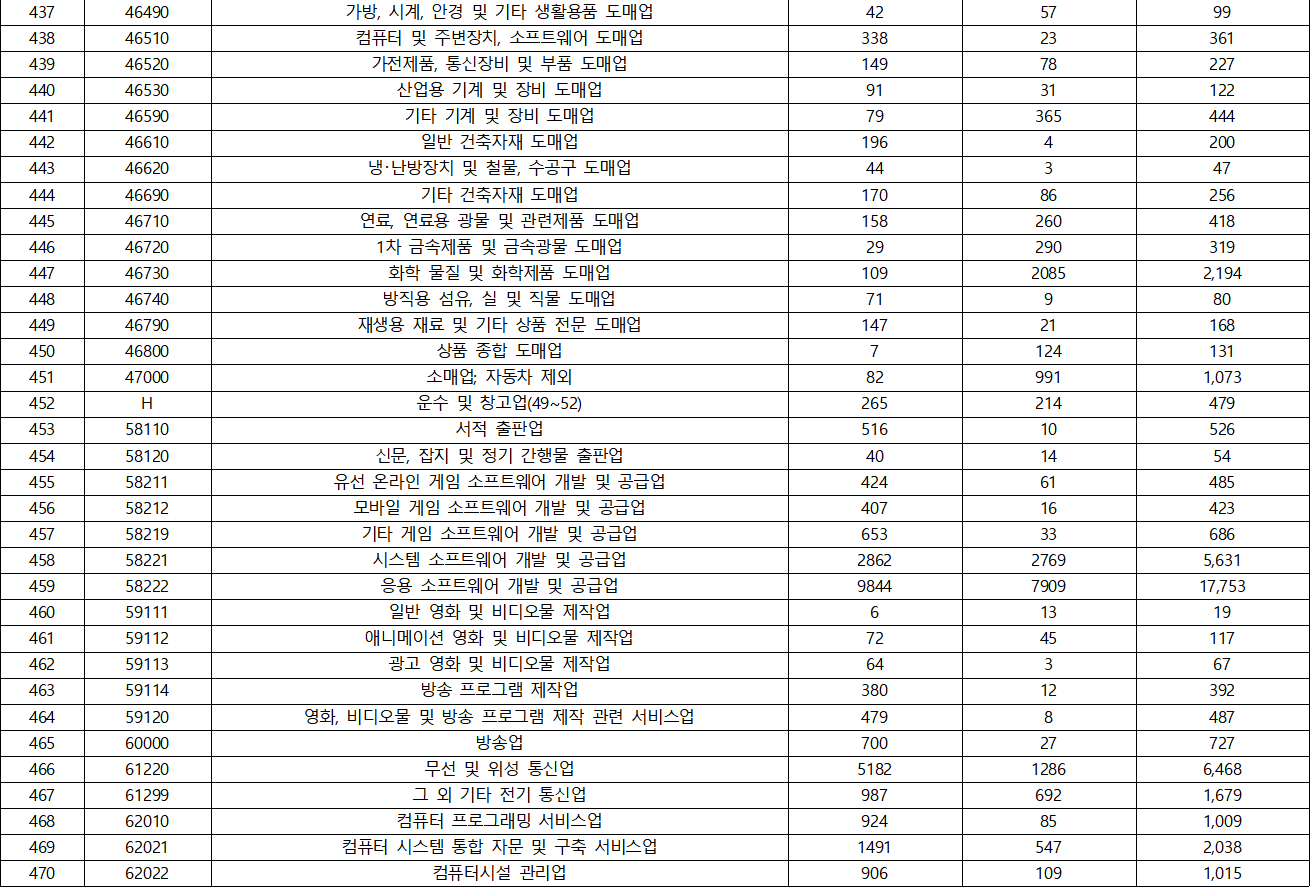
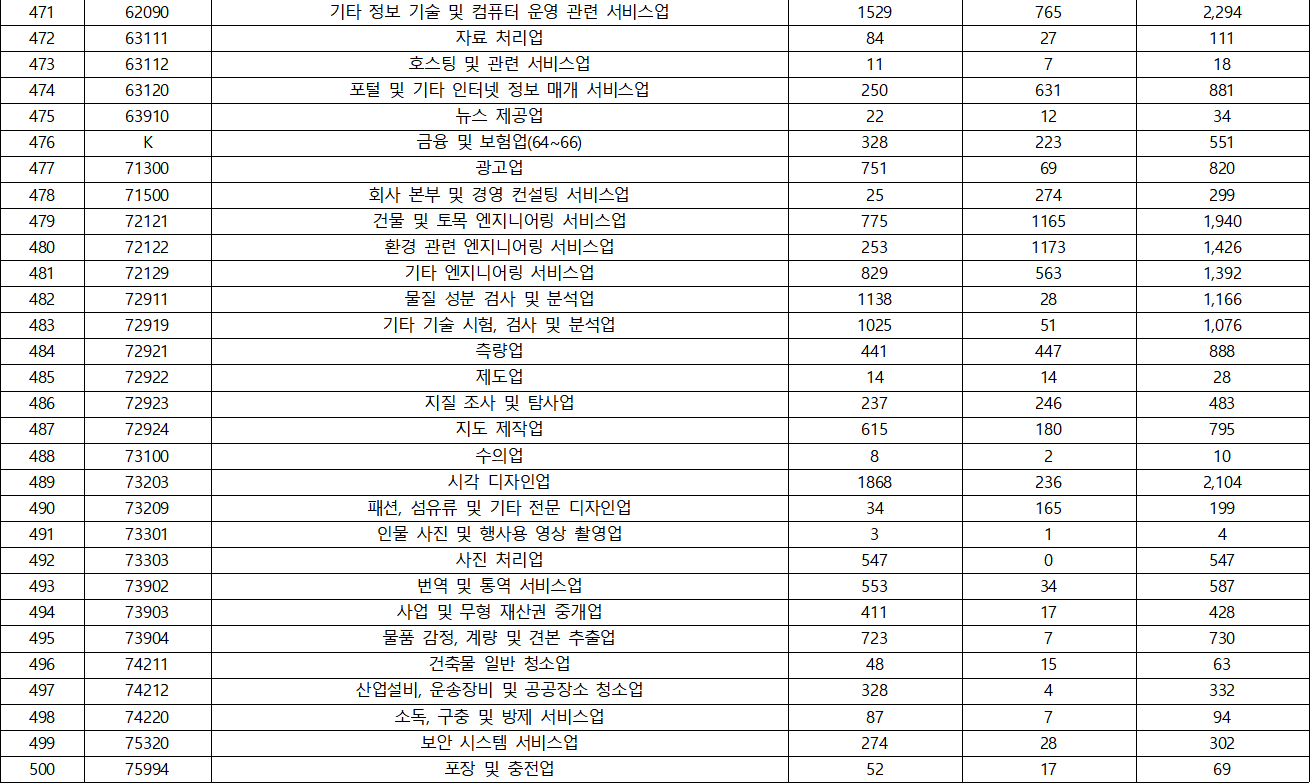
- 국가별 분포
-
-
AI 모델 상세 설명서 다운로드
AI 모델 상세 설명서 다운로드 AI 모델 다운로드산업정보 연계 주요국 특허 영한데이터 활용 AI 모델
- (한글 특허 문서 학습모델) 한국 특허 문서 학습모델 선정기준에 적합할 것으로 예상되는 AI 모델들에 대해 조사한 결과 BERT-base-Multilingual-cased를 학습모델로 선정
- 1cycle 실험 결과 정확도를 포함하여 사전 학습된 모델의 데이터의 특징과 본 과제에서 연구하고자 하는 데이터 특징과 유사하여야 함.
- 모델을 학습하는 과정에서 BERT 모델 fine-tuning이 학습데이터에 맞게 적절하게 이루어져야 하는 것을 고려해야 함.
- 위와 같은 이유에 의해서 최종적으로 BERT-base-Multilingual-cased를 학습모델로 선정하였음.
[그림] 한글 특허 문서 BERT 모델 기본 구조
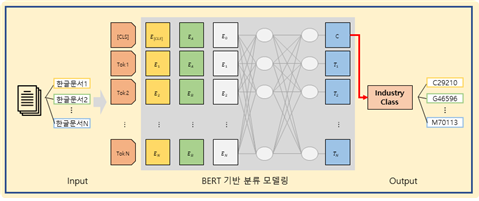
- (영문 특허 문서 학습 모델) 설정한 영문 특허 문서 학습모델 선정기준에 적합할 것으로 예상되는 AI 모델들에 대해 조사한 결과 BERT-Base/Cased를 학습모델로 선정
- 1cycle 실험 결과 정확도를 포함하여 사전 학습된 모델의 데이터의 특징과 본 과제에서 연구하고자 하는 데이터 특징과 유사하여야 함.
- 모델을 학습하는 과정에서 BERT 모델 fine-tuning이 학습데이터에 맞게 적절하게 이루어져야 하는 것을 고려해야 함.
- 위와 같은 이유에 의해서 최종적으로 BERT-Base/Cased를 학습모델로 선정하였음.
[그림] 영문 특허 문서 BERT 모델 기본 구조
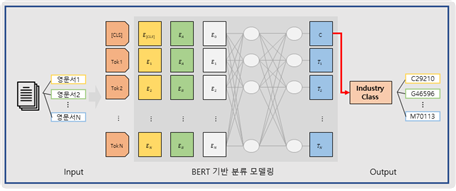
- (한글 특허 문서 학습모델) 한국 특허 문서 학습모델 선정기준에 적합할 것으로 예상되는 AI 모델들에 대해 조사한 결과 BERT-base-Multilingual-cased를 학습모델로 선정
-
데이터 성능 점수
측정값 (%)기준값 (%)데이터 성능 지표
데이터 성능 지표 번호 측정항목 AI TASK 학습모델 지표명 기준값 점수 측정값 점수 1 산업 라벨 예측 정확도 Text Classification BERT AccuracyTop-1 85 % 90 % 2 산업 라벨 예측 정확도 Text Classification BERT AccuracyTop-3 95 % 95 %
※ 데이터 성능 지표가 여러 개일 경우 각 항목을 클릭하면 해당 지표의 값이 그래프에 표기됩니다.
※ AI모델 평가 지표에 따라 측정값의 범위, 판단 기준이 달라질 수 있습니다. (ex. 오류율의 경우, 낮을수록 좋은 성능을 내는 것으로 평가됩니다)
-
설명서 및 활용가이드 다운로드
데이터 설명서 다운로드 구축활용가이드 다운로드1. 대표 특허명세서
1. 대표 특허명세서 제목 Method for Producing a Cooling Element for Pyrometallurgical Reactor and the Cooling Element 출원번호 13318647 문헌번호 201200043065A1 국가코드 US IPC F28F 1/00, B23P 15/26 요약 Cooling element (2) for pyrometallurgical reactors and method of manufacturing the element, wherein at least one cooling channel (1) having two ends is provided first. Each end of the cooling channel (1) has connection means (17) for cooling medium and at least one cooling channel (1) is connected connecting means to a wall of pyrometallurgical reactor. Further, at least one tube having an outer cross section and inner cross section is formed and the tube bent to an open loop to form at least one cooling channel, the ends of which being joinable to the means (3) for connecting the cooling channel (1) to a wall of pyrometallurgical reactor. 대표청구항 Method for manufacturing a cooling element for pyrometallurgical reactors, the method comprising forming at least one tube having an outer cross section and inner cross section, bending the at least one tube to an open loop to form at least one cooling channel, the ends of which being joinable to the means for connecting the cooling channel (1) to a wall of pyrometallurgical reactor to form at least one cooling channel (1) having two ends, providing each end of the cooling channel (1) with connection means (17) for cooling medium, and joining at least one cooling channel (1) with means for connecting it to a wall of a pyrometallurgical reactor, characterized by forming the open loop of the cooling channel (1) to a wedge shape so that the thickness of the cooling element (1) is bigger on the side of the means for connecting to the wall of the pyrometallurgical reactor (s1) than at the bottom of the loop (s2). 2. 라벨링데이터 구성
2. 라벨링데이터 구성 구분 항목명 타입 필수여부 설명 범위 비고 1 labeled_data String Y Json_key 값 1.1 application_number String Y 출원번호 literature_number String Y 문헌번호 invention_title_eng String Y 발명의 명칭-영문 invention_title_kor String Y 발명의 명칭-번역국문 country_code String Y 국가코드 astrt_cont_eng String Y 영문초록 astrt_cont_kor String Y 번역국문초록 claim_eng String Y 영문청구항 claim_kor String Y 번역국문청구항 ipc_number String Y IPC 번호 tech_word_eng String Y 영문기술용어 tech_word_kor String Y 번역국문기술용어 Indstryclass_name_kor String Y 국문산업분류 ksic_code String Y KSIC 산업분류 코드 3. 라벨링데이터(Json) 실제예시

-
데이터셋 구축 담당자
수행기관(주관) : 한국지식재산연구원
수행기관(주관) 책임자명 전화번호 대표이메일 담당업무 임효정 02-2189-2627 hjlim@kiip.re.kr · 데이터 품질관리 및 총괄 수행기관(참여)
수행기관(참여) 기관명 담당업무 ㈜마크클라우드 · 데이터 수집 및 정제 아이웹 · 어노테이션 툴 광운대학교 · AI 모델 특허법인로얄 · 데이터 가공 해율특허법률사무소 · 데이터 가공 특허법인KBK · 데이터 가공 지심특허법률사무소 · 데이터 가공 데이터 관련 문의처
데이터 관련 문의처 담당자명 전화번호 이메일 ㈜마크클라우드 02-1833-4992 sijeong@markcloud.co.kr
-
인터넷과 물리적으로 분리된 온라인·오프라인 공간으로 의료 데이터를 포함하여 보안 조치가 요구되는 데이터를 다운로드 없이 접근하고 분석 가능
* 온라인 안심존 : 보안이 보장된 온라인 네트워크를 통해 집, 연구실, 사무실 등 어디서나 접속하여 데이터에 접근하고 분석
* 오프라인 안심존 : 추가적인 보안이 필요한 데이터를 대상으로 지정된 물리적 공간에서만 접속하여 데이터에 접근하고 분석 -
- AI 허브 접속
신청자 - 안심존
사용신청신청자신청서류 제출* - 심사구축기관
- 승인구축기관
- 데이터 분석 활용신청자
- 분석모델반출신청자
- AI 허브 접속
-
1. 기관생명윤리위원회(IRB) 심의 결과 통지서 [IRB 알아보기] [공용IRB 심의신청 가이드라인]
2. 기관생명윤리위원회(IRB) 승인된 연구계획서
3. 신청자 소속 증빙 서류 (재직증명서, 재학증명서, 근로계약서 등 택1)
4. 안심존 이용 신청서 [다운로드]
5. 보안서약서 [다운로드]
※ 상기 신청서 및 첨부 서류를 완비한 후 신청을 진행하셔야 정상적으로 절차가 이루어집니다. -
신청 및 이용관련 문의는 safezone1@aihub.kr 또는 02-525-7708, 7709로 문의
데이터셋 다운로드 승인이 완료 된 후 API 다운로드 서비스를 이용하실 수 있습니다.
API 다운로드 파일은 분할 압축되어 다운로드 됩니다. 분할 압축 해제를 위해서는 분할 압축 파일들의 병합이 필요하며 리눅스 명령어 사용이 필요합니다.
리눅스 OS 계열에서 다운로드 받으시길 권장하며 윈도우에서 파일 다운로드 시 wsl(리눅스용 윈도우 하위 시스템) 설치가 필요합니다.
※ 파일 병합 리눅스 명령어
find "폴더경로" -name "파일명.zip.part*" -print0 | sort -zt'.' -k2V | xargs -0 cat > "파일명.zip"
- 해당 명령어 실행 시, 실행 경로 위치에 병합 압축 파일이 생성됩니다.
- 병합된 파일 용량이 0일 경우, 제대로 병합이 되지 않은 상태이니 "폴더경로"가 제대로 입력되었는지 확인 부탁드립니다.
※ 데이터셋 소개 페이지에서 다운로드 버튼 클릭하여 승인이 필요합니다.
오프라인 데이터 이용 안내
본 데이터는 K-ICT 빅데이터센터에서도 이용하실 수 있습니다.
다양한 데이터(미개방 데이터 포함)를 분석할 수 있는 오프라인 분석공간을 제공하고 있습니다.
데이터 안심구역 이용절차 및 신청은 K-ICT빅데이터센터 홈페이지를 참고하시기 바랍니다.

국방데이터 개방 안내
본 데이터는 국방데이터로 군사 보안에 따라 AI허브에서 데이터를 제공하지 않으며,
군 담당자를 통한 별도의 사용 신청이 필요합니다.