-
데이터 변경이력
데이터 변경이력 버전 일자 변경내용 비고 1.1 2023-12-15 데이터 최종 개방 1.0 2023-07-05 데이터 개방(Beta Version) 데이터 히스토리
데이터 히스토리 일자 변경내용 비고 2024-01-05 산출물 전체 공개 소개
지문, 전문용어, 단서문장, 요약문으로 구성된 12만건의 데이터셋으로 수식은 LaTex을 이용함. 전문성이 요구되는 기술과학 분야 문서를 국가 오픈액세스 플랫폼 AccessOn, 국내 학회, 전문 서적 출판사 등에서 수집된 원시 데이터를 통해 수집하여 구축함
구축목적
생성요약이 가능한 모델 연구와 문서 분석 및 요약 등의 서비스를 개발할 수 있음. 수식을 LaTex 문법을 이용해 처리함으로써 인공지능 학습이 가능한 형태로 가공하여 기술 과학 도메인에 특화된 데이터셋 구축. 요약문에 포함된 전문 과학/공학분야 전문용어를 태깅하여 키워드를 추출해 개체명 인식 학습에 활용 가능
-
메타데이터 구조표 데이터 영역 한국어 데이터 유형 텍스트 데이터 형식 txt 데이터 출처 국가 오픈액세스 플랫폼 AccessOn, 국내 학회, 전문 서적 출판사 라벨링 유형 문서요약(자연어) 라벨링 형식 JSON 데이터 활용 서비스 생성요약이 가능한 모델 연구, 문서 분석 및 요약 서비스, 개체명 인식 학습 데이터 구축년도/
데이터 구축량2022년/120,000건 -
1. 데이터 통계
- 데이터 구축 규모데이터 구축 규모 수량 원천 데이터 수량 21204 요약문 수량 120046 - 데이터 분포
● 문서 유형 분포문서 유형 분포 문서 유형 수량 구성비 도서 567 3% 논문 20637 97% 합계 21204 100% ● 요약문 길이(문장)
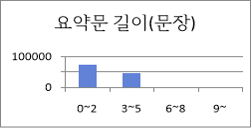
문장 수 문장 수 수량 구성비 0~2 72445 60.30% 3~5 45779 38.10% 6~8 1675 1.40% 9~ 147 0.10% 합계 120046 100% ● 요약문 길이(어절)
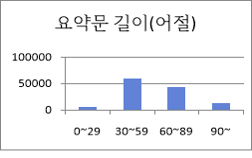
요약문 길이(어절) 어절 수량 구성비 0~29 6364 5% 30~59 58729 49% 60~89 42743 36% 90~ 12210 10% 합계 120046 100% ● 원문 길이(어절)
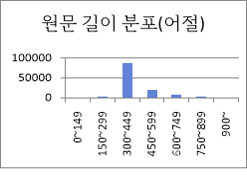
요약문 길이(어절) 어절 수량 구성비 0~149 210 0.20% 150~299 2861 2.40% 300~449 87138 72.60% 450~599 20007 16.70% 600~749 6398 5.30% 750~899 2468 2.10% 900~ 964 0.80% 합계 120046 100% ● 기술 과학 문서 K-NSCC 분포
기술 과학 문서 K-NSCC 분포 대분류 중분류 분류코드 개수 구성비 분류코드 개수 구성비 ED 78919 66% 1 5638 4.70% 2 4054 3.38% 3 5340 4.45% 4 12235 10.19% 5 10738 8.94% 6 2950 2.46% 7 5192 4.33% 8 6450 5.37% 9 2281 1.90% 10 1926 1.60% 11 4686 3.90% 13 9 0.01% 99 17420 14.51% EE 20358 17% 1 4728 3.94% 2 3666 3.05% 3 1064 0.89% 4 826 0.69% 5 948 0.79% 6 1134 0.94% 7 586 0.49% 8 405 0.34% 9 279 0.23% 10 407 0.34% 11 1274 1.06% 12 142 0.12% 13 126 0.10% 14 199 0.17% 99 4574 3.81% LA 8682 7% 1 1105 0.92% 2 884 0.74% 3 224 0.19% 4 1088 0.91% 5 1182 0.98% 6 460 0.38% 7 159 0.13% 8 1264 1.05% 9 883 0.74% 10 95 0.08% 11 145 0.12% 99 1193 0.99% NA 12087 10% 1 2215 1.85% 2 3615 3.01% 3 1242 1.03% 4 1433 1.19% 5 523 0.44% 6 169 0.14% 7 341 0.28% 8 214 0.18% 9 692 0.58% 10 936 0.78% 99 707 0.59% 합계 120046 100% 120046 100% -
-
AI 모델 상세 설명서 다운로드
AI 모델 상세 설명서 다운로드 AI 모델 다운로드학습 모델 데이터 명 기술과학 문서요약 데이터 학습 모델 기술과학 문서 생성 요약 모델 모델 KoBART 성능 지표 rougeL 30% 이상 개발 내용 일반적인 생성 임무에서 좋은 성능을 보여주는 BART 모델을 선정, 개발을 진행. 구축된 대량의 문서 요약 데이터를 통해 기술과학 문서요약 모델 고도화 응용서비스 본 기술과학 특화 모델과 대량의 지식 베이스를 이용해, 논문 요약, 과학 기술 분야 동향 조사 등의 서비스를 개발하여 API 형태로 제공가능함 (예시 및 유의사항) 한국어 기술과학 특화 모델을 만들기 위해서 먼저 한국어 사전학습을 진행하거나 사전 학습된 모델과 토크나이저로 학습을 시작하면 더 좋은 성능을 기대할 수 있음 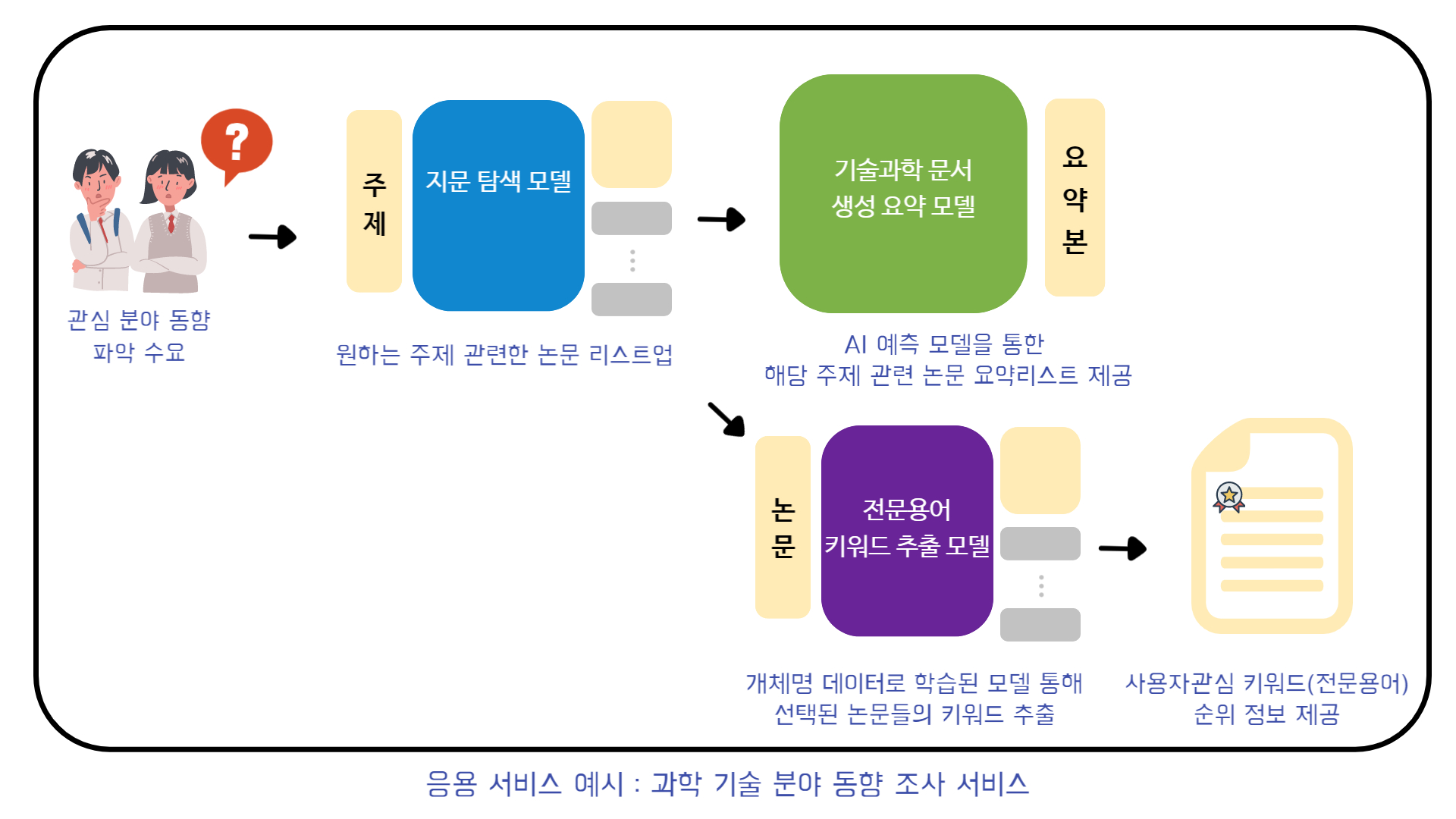
□ 응용 서비스 개발 예시 : 과학 기술 분야 동향 조사 서비스
● 지문 탐색 모델 : 구축된 대량의 전문 과학/공학 데이터를 통해 지식 베이스를 구축하여 사용자가 관심있어하는 주제에 대한 정답이 포함된 논문 탐색 후 리스트업 가능한 모델을 개발하여 관련 논문 빠르게 검색하는 기능 제공
● 기술과학 문서 생성 요약 모델: 빠르게 동향 조사가 이뤄질 수 있도록 리스트업 된 논문들의 요약본 제공
● 전문용어 키워드 추출 모델 : 구축된 데이터 내 개체명 인식 데이터로 학습된 전문용어 추출 모델을 이용하여 사용자가 선택한 논문을 바탕으로 사용자 관심 키워드 추출 가능, 관심 키워드들을 저장하여 해당 순위 정보 등을 사용자들에게 제공 -
데이터 성능 점수
측정값 (%)기준값 (%)데이터 성능 지표
데이터 성능 지표 번호 측정항목 AI TASK 학습모델 지표명 기준값 점수 측정값 점수 1 생성요약 성능 Text Generation Bart ROUGE-L 33 % 33.04 %
※ 데이터 성능 지표가 여러 개일 경우 각 항목을 클릭하면 해당 지표의 값이 그래프에 표기됩니다.
※ AI모델 평가 지표에 따라 측정값의 범위, 판단 기준이 달라질 수 있습니다. (ex. 오류율의 경우, 낮을수록 좋은 성능을 내는 것으로 평가됩니다)
-
설명서 및 활용가이드 다운로드
데이터 설명서 다운로드 구축활용가이드 다운로드1. 데이터 포맷
- 포맷예시포맷예시 문서 제목 전역 및 지역 특징 기반 딥러닝을 이용한 프린터 장치 판별 기술 유형 요약문 분류 ED 지문 Deng et. al은 상기 방법과 유사하게 특정 문자를 분석에 초점을 두었지만 텍스쳐 특징이 아닌 문자 간의 거리를 이용하여 45개의 프린터를 판별하는 연구를 진행하였다. 판별을 위해 각 문서에서 특정 문자의 영상을 획득한 후, 이진화를 통해 깨끗한 문자 영상을 생성하였다. 그 후 거리변환을 통해 문자 픽셀과 배경 픽셀의 거리를 구하였고 입력한 영상의 거리 값과 입력해놓은 프린터 중 가장 근사한 거리 값을 보이는 프린터로 판별하였다. 영문자 3가지 글꼴과 중국어 1가지 글꼴을 대상으로 실험을 하였으며, Top 1 식별률은 평균 25%, Top 5 식별률은 평균 81.7%의 정확도를 보였다. 이전 연구들과 성능은 비슷하면서도 인쇄 DPI와 인쇄 재료에 강인한 결과를 보였다. 하지만 인쇄 부품의 상태에 따라 성능이 변하고 인쇄 시점에 따른 변화에 취약한 결과를 보였다.
Elkasrawi et. al은 프린터별 노이즈 및 인쇄 패턴을 분석하여 20개의 프린터를 식별하는 연구를 진행하였다. 문서에 포함된 문장의 높이를 비교하는 방법, 영상에 이진화를 적용 후 중간값 필터링을 사용하고 이와 원본 영상 간의 차영상을 통해 잡음을 뽑아내 비교하는 방법 등을 통해 식별을 시도하였다. 전체 프린터 데이터셋에 대한 정확도는 76.75%를 달성하였고 잉크젯 프린터에 한하여 93.57%의 성능을 나타내었다.
Choi et al.은 이산 웨이블릿 변환(Discrete Wavelet Transform, DWT)을 이용한 프린터 판별을 제안하였다. 컬러 레이저 프린터로 인쇄한 영상을 RGB와 CMYK 도메인으로 나누고 DWT 연산을 수행하여 각각의 HH 밴드를 특징으로 활용한다. 특징값을 SVM 분류기를 이용하여 분류하였고 프린터 브랜드 판별 및 프린터 장치 판별에 있어서 각각 97.89% 및 80.24%의 정확도를 달성하였다.
Ryu et. al은 사람의 눈으로 인지할 수 없는 하프톤 패턴을 이용한 프린터 판별 연구를 진행하였다. CMYK 도메인의 하프톤 패턴을 분석하여 9개의 프린터를 분류하였다. 그 결과 브랜드 판별은 91.9%의 정확도를 보여주었고 각 프린터 장치판별에서는 평균 63%의 정확도를 나타내었다. 하프톤 패턴의 차이는 잘 구분했지만 같은 브랜드의 프린터가 유사한 패턴을 보이기 때문에 프린터에 대해 독립적이지 않아 개별 프린터 분류에는 취약한 정확도를 보였다. Kim and Lee는 이를 확장하여 하프톤 패턴의 텍스쳐 핑거프린터를 이용하여 5개 프린터 장치 판별을 연구하였고 평균 86.14% 정확도를 보였다.전문용어 프린터, 이진화, 픽셀, DPI, 차영상, 이산 웨이블릿 변환, RGB, CMYK, HH 밴드, SVM 분류기, 하프톤 패턴, 핑거프린터 단서문장 ● Deng et. al은 상기 방법과 유사하게 특정 문자를 분석에 초점을 두었지만 텍스쳐 특징이 아닌 문자 간의 거리를 이용하여 45개의 프린터를 판별하는 연구를 진행하였다.
● Elkasrawi et. al은 프린터별 노이즈 및 인쇄 패턴을 분석하여 20개의 프린터를 식별하는 연구를 진행하였다.
● Choi et al. 은 이산 웨이블릿 변환(Discrete Wavelet Transform, DWT)을 이용한 프린터 판별을 제안하였다.
● Ryu et. al은 사람의 눈으로 인지할 수 없는 하프톤 패턴을 이용한 프린터 판별 연구를 진행하였다.
● Kim and Lee는 이를 확장하여 하프톤 패턴의 텍스쳐 핑거프린터를 이용하여 5개 프린터 장치 판별을 연구하였고 평균 86. 14% 정확도를 보였다.요약문 Deng은 프린터 45개를 식별할 때 텍스쳐 특징이 아닌 문자 간격을 활용했다. Elkasrawi은 노이즈와 인쇄 패턴을 분석해 프린터 20개를 구분했고, Choi는 이산 웨이블릿 변환을 활용하는 방법을 제시했다. Ryu의 프린터 판별 연구는 인간의 눈으로 인지하지 못하는 하프톤 패턴을 적용했다. 나아가 Kim과 Lee는 하프톤 패턴의 텍스쳐 핑거프린터를 활용해 정확도 86.14%를 보였다. - JSON 형식
{
"context_id": b8f1c479-2365-4975-a3fa-da9321fe62f0",
"context_K-NSCC": {
"field": "자연",
"large_category": "ED",
"medium_category": "11“
}
"context_length": 1207,
"context": "Ⅰ.서론
현대의 레이다는 군사용 탐색 및 추적 레이다, 항공 교통 통제 레이다 및 기상 레이다 등 많은 분야에서 다양한 기능을 가지고 사용되고 있다. 아울러 여러 가지 기능을 복합적으로 가지고 있는 다기능 레이다가 개발되어 사용되고 있다. 이러한 레이다의 개발 및 운용을 위해 중요한 부분 중의 하나는 개발된 레이다의 기능과 성능을 시험 및 분석하는 것이다. 따라서 레이다를 분석 평가하기 위한 시험 장비의 개발이 병행되어야만 요구 조건을 충족시킬 수 있는 레이다의 개발이 가능하다.
이러한 시험 장비를 구현하는 효과적인 방법 중 하나는 상용화 되어있는 계측장비를 사용하는 것으로서, 개발기간이 적게 소요되고 장비개발에 따른 위험 요소를 줄일 수 있다. 하지만 상용화된 계측기를 사용하는 데 따르는 문제점으로는 레이다 시험용으로 특화된 계측기가 아니므로 고가 장비의 일부 기능만을 사용하게 됨으로써 많은 장비가 필요하며, 이에 따른 개발비 상승을 가져올 수 있다. 또한 다양한 성능 시험과 특정 신호를 발생하기 위한 장비의 재구성에 어려움이 있다. 따라서 개발 레이다의 시험 항목에 적합한 특정 시험장비의 개발이 요구된다.
그림 $1$. 레이다 시험장비 구성도는 일반적인 레이다 시험 장비 구성도로서 그 중에서 타이밍 신호 발생기는 시험 레이다와 모의 신호 발생기가 정확하게 동기 되어 시험 신호를 송수신 하도록 타이밍 신호를 발생하는 기능을 갖는다.
본 논문에서는 레이다 송수신 안테나의 방위각 측면에서 기계적으로 $360$도 회전을 하여 탐색하고, 고각 측면에서 빔 조향을 통하여 $90$도 영역을 탐색하는 $3$차원 펄스 레이다의 성능 분석을 위한 각 종 레이다 파형, 환경 신호 및 표적 신호를 모의 발생하는데 필요한 모든 타이밍 신호를 발생하는 장비의 설계 및 구현 기법과 함께 그 성능평가 결과를 기술한다.
본 논문의 주요 구성을 보면 제 $1$장에서는 본 논문의 배경 및 목적을 기술하였고, 제 $2$장에서는 $3$차원 펄스레이다의 타이밍 신호에 대한 분석 및 신호발생기의 방위각 관련 타이밍 신호, 레이다 송신 퍼스 관련 타이밍 신호 및 모의 표적 신호 관련 타이밍 신호 발생부에 대한 설계이론 및 블록에 설명하였다. 제 $4$장에서는 제작된 장치의 측정 및 결과에 대한 분석을 다루었으며, 마지막 장에서는 본 장비의 향후 발전 방향과 추가적으로 필요한 성능에 대해 언급하였다.
",
"summary":"레이다를 분석 평가하기 위한 시험장비의 개발은 요구 조건을 충족시킬 수 있는 레이다의 개발에 필수적이다. 하지만 상용화된 계측기를 사용하는 데 한계가 있어 개발 레이다의 시험 항목에 적합한 특정 시험장비의 개발이 요구된다. 본 논문에서는 $3$차원 펄스레이다의 성능 분석을 위한 장비의 설계 및 구현 기법과 함께 그 성능평가 결과를 기술한다.",
"clue":[
{"clue_start": 145, "clue_end": 211},
{"clue_start": 212, "clue_end": 281},
{"clue_start": 384, "clue_end": 434},
{"clue_start": 549, "clue_end": 590},
{"clue_start": 727, "clue_end": 931}
],
"terminology":[
{"word": "레이다", "meaning": "레이다는 전자파를 이용해 원거리에 있는 물체의 위치와 특성을 탐지하고 추적할 수 있는 가장 대표적인 전자파 센서"},
{"word": "방위각", "meaning": "구면좌표계에서 잰 각도로, 원점에 있는 관측자로부터 대상까지의 벡터를 기준 평면에 수직으로 투영하여 그것이 기준 평면 위에 있는 기준 벡터와 이루는 각"}
]}2. 데이터 구성 및 어노테이션 포맷
데이터 구성 및 어노테이션 포맷 구 분 항목명 타입 필수 설명 1 dataset 데이터셋 라벨 정보 1-1 identifier string y 데이터셋 식별자 1-2 name string y 데이터셋 명 1-3 category number n 데이터셋 분류 1-4 last_updated number n 마지막 갱신 날짜 2 doc_info 원시 데이터 정보 2-1 doc_id number y 원시 데이터 일련번호 2-2 doc_type string y 유형 2-3 doc_title 제목 2-3-1 kor string n 국문 제목 2-3-2 eng string n 영문 제목 2-4 doc_category 분류 번호 2-4-1 KDC string n KDC 분류 번호 2-4-2 DDC string n DDC 분류 번호 2-5 doc_number 식별 번호 2-5-1 ISSN string n ISSN 번호 2-5-2 ISBN string n ISBN 번호 2-5-3 DOI string n DOI 번호 2-5-4 UCI string n UCI 번호 2-6 doc_year string n 발행일 2-7 doc_author string n 저자 2-8 doc_publisher string n 출판사 2-9 doc_license string n 저작권 정보 2-10 context_info[] 원천 데이터 정보 2-10-1 context_id number y 원천 데이터 일련번호 2-10-2 context_K-NSCC 국가표준과학분류체계 2-10-2-1 field string y 과학기술 분야 2-10-2-2 large_category string y 대분류 2-10-2-3 medium_category number y 중분류 2-10-3 context_length number y 길이 2-10-4 context string y 원천 데이터 본문 정보 2-10-5 summary string y 라벨 정보 (요약문) 2-10-6 clue[] 단서(중요문장) 2-10-6-9-1 clue_start number n 단서 시작 위치 2-10-6-9-2 clue_end number n 단서 종료 위치 2-10-7 terminology[] string 전문용어에 대한 라벨 정보 2-10-7-1 word string n 단어 2-10-7-2 meaning string n 단어 의미 -
데이터셋 구축 담당자
수행기관(주관) : 경북대학교 산학협력단
수행기관(주관) 책임자명 전화번호 대표이메일 담당업무 정호영 053-950-2337 hoyjung@knu.ac.kr 사업 총괄 수행기관(참여)
수행기관(참여) 기관명 담당업무 유니바 AI 모델 및 저작도구 개발 제이솔루션 데이터 정제 및 가공 엠엔비젼 데이터 정제 및 가공 데이터 관련 문의처
데이터 관련 문의처 담당자명 전화번호 이메일 정호영 053-950-2337 hoyjung@knu.ac.kr
-
인터넷과 물리적으로 분리된 온라인·오프라인 공간으로 의료 데이터를 포함하여 보안 조치가 요구되는 데이터를 다운로드 없이 접근하고 분석 가능
* 온라인 안심존 : 보안이 보장된 온라인 네트워크를 통해 집, 연구실, 사무실 등 어디서나 접속하여 데이터에 접근하고 분석
* 오프라인 안심존 : 추가적인 보안이 필요한 데이터를 대상으로 지정된 물리적 공간에서만 접속하여 데이터에 접근하고 분석 -
- AI 허브 접속
신청자 - 안심존
사용신청신청자신청서류 제출* - 심사구축기관
- 승인구축기관
- 데이터 분석 활용신청자
- 분석모델반출신청자
- AI 허브 접속
-
1. 기관생명윤리위원회(IRB) 심의 결과 통지서 [IRB 알아보기] [공용IRB 심의신청 가이드라인]
2. 기관생명윤리위원회(IRB) 승인된 연구계획서
3. 신청자 소속 증빙 서류 (재직증명서, 재학증명서, 근로계약서 등 택1)
4. 안심존 이용 신청서 [다운로드]
5. 보안서약서 [다운로드]
※ 상기 신청서 및 첨부 서류를 완비한 후 신청을 진행하셔야 정상적으로 절차가 이루어집니다. -
신청 및 이용관련 문의는 safezone1@aihub.kr 또는 02-525-7708, 7709로 문의
데이터셋 다운로드 승인이 완료 된 후 API 다운로드 서비스를 이용하실 수 있습니다.
API 다운로드 파일은 분할 압축되어 다운로드 됩니다. 분할 압축 해제를 위해서는 분할 압축 파일들의 병합이 필요하며 리눅스 명령어 사용이 필요합니다.
리눅스 OS 계열에서 다운로드 받으시길 권장하며 윈도우에서 파일 다운로드 시 wsl(리눅스용 윈도우 하위 시스템) 설치가 필요합니다.
※ 파일 병합 리눅스 명령어
find "폴더경로" -name "파일명.zip.part*" -print0 | sort -zt'.' -k2V | xargs -0 cat > "파일명.zip"
- 해당 명령어 실행 시, 실행 경로 위치에 병합 압축 파일이 생성됩니다.
- 병합된 파일 용량이 0일 경우, 제대로 병합이 되지 않은 상태이니 "폴더경로"가 제대로 입력되었는지 확인 부탁드립니다.
※ 데이터셋 소개 페이지에서 다운로드 버튼 클릭하여 승인이 필요합니다.
오프라인 데이터 이용 안내
본 데이터는 K-ICT 빅데이터센터에서도 이용하실 수 있습니다.
다양한 데이터(미개방 데이터 포함)를 분석할 수 있는 오프라인 분석공간을 제공하고 있습니다.
데이터 안심구역 이용절차 및 신청은 K-ICT빅데이터센터 홈페이지를 참고하시기 바랍니다.

국방데이터 개방 안내
본 데이터는 국방데이터로 군사 보안에 따라 AI허브에서 데이터를 제공하지 않으며,
군 담당자를 통한 별도의 사용 신청이 필요합니다.