-
데이터 변경이력
데이터 변경이력 버전 일자 변경내용 비고 1.1 2024-02-28 데이터 최종 개방 1.0 2023-07-31 데이터 개방(Beta Version) 데이터 히스토리
데이터 히스토리 일자 변경내용 비고 2025-06-12 구축업체정보수정 2024-03-06 산출물 전체 공개 소개
스토리 작품의 서사단위를 유닛으로 하여 줄거리를 작성하고 설정, 모티프, 인물, 서사단계, 감정, 장소 등의 스토리 창작 요소를 라벨링
구축목적
ㅇ 창작 지원을 위하여, 작가의 구상에 따라 스토리 추천 및 자동 생성을 하기 위한 인공지능 모델의 개발을 위한 스토리 데이터를 구축 - 스토리의 줄거리 데이터 구축 및 스토리 유닛 구분, 장르, 주제, 서사구조 분석 - 인물, 감정, 모티프, 상황, 맥락, 서사단계 등의 분석 및 라벨링 -
메타데이터 구조표 데이터 영역 한국어 데이터 유형 텍스트 데이터 형식 json 데이터 출처 영화, 드라마, 소설, 만화 등 스토리 분석에 의한 줄거리 창작, 재창작 및 저작권 구입 라벨링 유형 내용요약(자연어),시퀀스라벨링,태깅 라벨링 형식 json 데이터 활용 서비스 영화, 소설, 시리즈 , 만화 등 스토리의 기획 및 개발, 작성을 도와주는 작가 지원 도구 데이터 구축년도/
데이터 구축량2022년/100,000 -
데이터 구축 규모
최종 인공지능 데이터: 3,953건 스토리 작품의 줄거리 유닛 100,077건, 어노테이션 json파일 3,953건
> 3,953건 스토리 작품의 줄거리 작성, 약 83MB
> 서사 단위 분석 수행, 100,077건의 스토리 유닛 생성
> 작품 단위 스토리 분석 수행: 장르, 주제, 기본 설정, 서사구조, 모티프, 갈등구조 분석
> 유닛 단위 스토리 분석 수행: 서사단계, 스토리라인, 모티프, 인과관계, 행동, 감정 분석
> 지문 873462건, 대사 503,127건, 총 1,376,589건의 스크립트 분석
> 스토리 작품 및 스토리 유닛 줄거리에 대해 분석 데이터 라벨링, JSON 파일 약 585MB스토리 추천 학습 데이터 규모
스토리 추천 학습 데이터 규모 전체 구축 데이터 대비
모델에 적용되는 비율AI모델 사용 데이터 비율(수량) 100% 모델 학습 과정별
데이터 분류 및 비율 정보• 학습용 데이터셋: 90,069 (90%)
• 검증용 데이터셋: 5,003 (5%)
• 평가용 데이터셋: 5,005 (5%)데이터 분포
스토리 유형별 분포:
한 유형이 50%를 초과하지 않도록 구성스토리 유형별 분포 유형 수량(건) 비율 영화 1,604 40.58% 시리즈 1,641 41.51% 소설 218 5.51% 만화 490 12.40% 합계 3,953 100% 장르별 분포:
한 장르가 40%를 초과하지 않도록 구성장르별 분포 장르 수량(건) 비율 SF 97.3 2.46% 공포(호러) 59.8 1.51% 드라마 1,523.70 38.55% 멜로/로맨스 943.5 23.87% 미스터리 122 3.09% 스릴러 486.1 12.30% 액션 255.7 6.47% 전쟁 31.9 0.81% 코미디 127 3.21% 판타지 306 7.74% 합계 3,593 100% * 장르 복수 선택 시 비율 산정:
1개 100% 가중치
2개 50:50 가중치
3개 40:40:20 가중치 적용
-
-
AI 모델 상세 설명서 다운로드
AI 모델 상세 설명서 다운로드 AI 모델 다운로드학습 모델 개발
▪ ScriptWriter-CPre(Content Prediction) 모델 개요
네러티브와 최초 스토리가 주어질 때 다음과 같은 스토리 생성이 진행된다.
ScriptWriter-CPre(Content Prediction) 모델 개요 구분 내 용 네러티브
(Narative)제니는 집에 가고 싶어 하지 않는다. 검프는 제니와 함께하기 위해 집으로는 나중에 가기로 한다. 검프는 제니의 가장 친한 친구이다. 최초 스토리
(대사)엄마가 걱정할 거야. 첫 번째 스토리 조금 더 있자. V 맞아, 그가 비웃는다는 것에 내 전재산을 걸지. 두 번째 스토리 좋아, 더 같이 있을게. V 그녀는 낡은 집에 살고 있었다. 세 번째 스토리 그는 꽤 다정한 남자였다. 넌 나에게 가장 특별한 친구야. V 출력된 스토리 중 체크표시된 것은 참 값(Ground truth)으로부터 추출된 것이고, 표시되지 않은 것은 관련성이 없는 문장으로부터 추출된 것이다.
▪ 모델의 정의
다음과 같이 모델의 데이터를 정의한다.
데이터셋 D는 다음과 같다.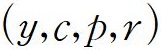
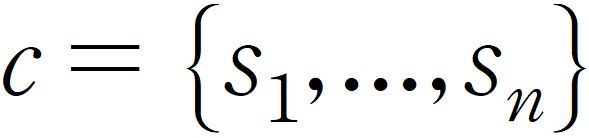 : 컨텍스트(context)로서 이전 스토리 라인들
: 컨텍스트(context)로서 이전 스토리 라인들
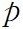 : 사전에 정의된(pre-defined) 네러티브
: 사전에 정의된(pre-defined) 네러티브
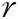 : 응답(response) - 생성 스토리 후보
: 응답(response) - 생성 스토리 후보
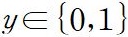 : 이진 라벨로서 응답이 적절한지를 지정
: 이진 라벨로서 응답이 적절한지를 지정본 모델 은 컨텍스트(context), 네러티브(pre-defined narrative), 응답(response)을 입력받아서 응답이 스토리 문맥과 순서에 맞는지에 대한 적절성을 판정한다.
▪ 모델의 알고리즘
Scriptwriter-CPre는 네러티브(narrative)를 중심으로 연속적인 스토리(혹은 대사) 구조를 생성한다. 자연어의 representation을 matching하고 aggregate하는 부분이 중심 모델 구조이다.
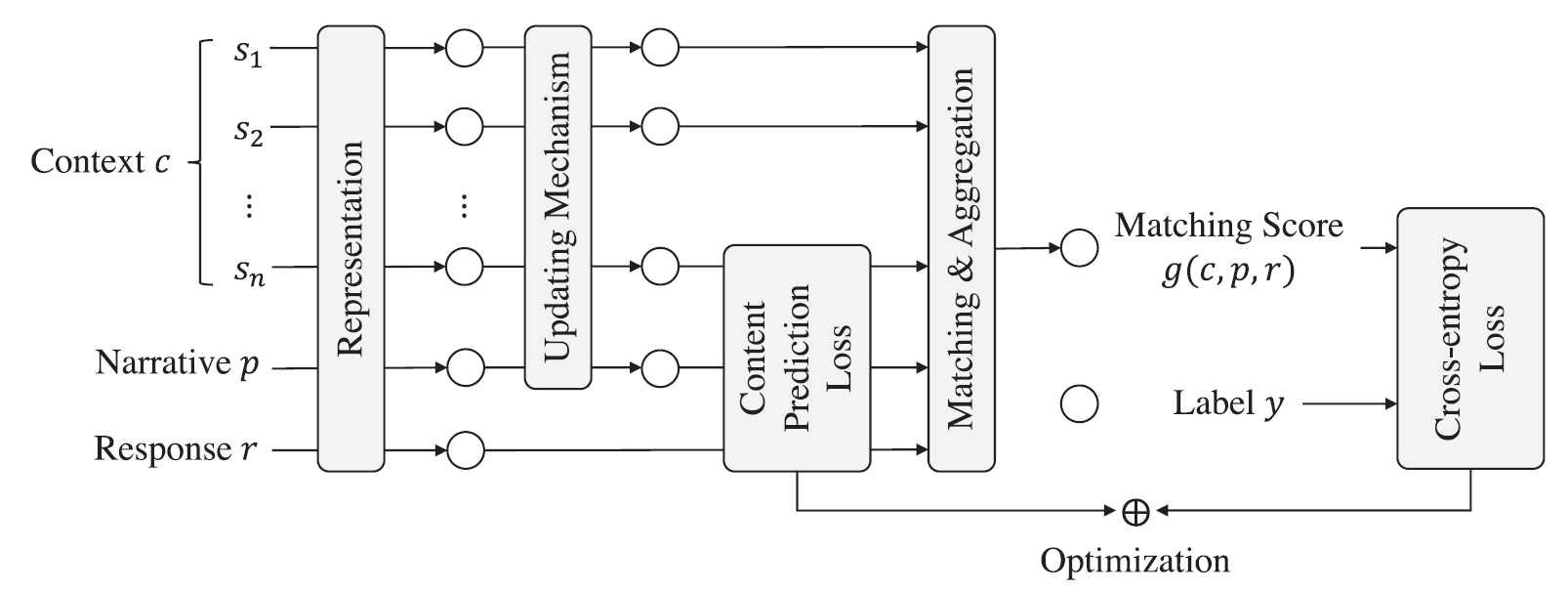
< ScriptWriter-CPre 모델의 기본 구조 >
위의 그림은 ScriptWriter-CPre 모델의 기본 구조이다. 먼저 네러티브와 컨텍스트(이전 스토리), 그리고 응답(생성 후보)은 multi-level attention 모듈에 의해 복수개의 cell 데이터로 표현(represent)된다. 두 번째로 업데이트 방식을 이용하여, 나중 스토리가 네러티브 및 앞선 스토리보다 높은 가중치를 가지도록 한다. 세 번째로 부가적인 손실함수를 통해서 네러티브의 어떤 부분이 다음 스토리를 예측할 수 있는지를 attention하도록 한다. 네 번째로 매칭되는 특징(feature)이 이전 스토리가 네러티브의 어떤 부분에 주목(attention)하였는지를 출력하도록 만들어진다. 마지막으로 이렇게 생성된 매칭 특징을 concatatenate하여서 CNN(convolutional neural network)과 MLP(multi-layer perception)을 통하여 최종 매칭 점수를 산출하도록 한다.
▪ 모델의 구현
- Scriptwriter-CPre의 공개된 소스 https://github.com/DaoD/ScriptWriter를 활용하여 구현한다.
- Scriptwriter-CPre는 tensorflow 1에서 개발되었다. 이를 tensorflow 2에서 동작하도록 모델을 개발한다.
- 또한, 멀티 GPU 학습을 위해 pytorch 상에서도 동작하도록 모델을 확장 개발한다.
- 개발된 모델은 https://github.com/ewhacc/ScriptWriter에 공개하고 관리한다.서비스 활용 서비스
▪ 작가 지원 스토리 검색 서비스
- 작가가 구상하는 스토리를 개념화하여 유사 사례를 검색하는 서비스
- 장르, 주제, 모티프, 인물 등의 설정으로 스토리 예시를 검색
▪ AI 스토리 장작 지원 분야
- 인물 성향/관계, 모티프, 스토리라인(상황) 등을 설정하면 AI가 이어지는 스토리를 생성
- 작가들의 구상에 따라 AI가 창작의 가능성을 보여주고, 이로부터 창작의 소재를 확장해가는 창작 지원 서비스
▪ <스토리헬퍼 AI> 서비스 개발을 통한 데이터 활용 및 작가지원 서비스
- 서비스 개발 : 이화여자대학교
- 서비스 개발 배경
● 2014년 개발되어 작가들의 창작 지원을 하였던 <스토리헬퍼> 작가의 구상에 대응하는 스토리 요소 추천 서비스로 작가 및 지망생들의 호평을 받음
● <스토리헬퍼> 서비스의 차세대 서비스로서 구축된 스토리데이터를 활용하여 확장된 창작 지원 서비스 개발
● AI 스크립트 생성 기능으로 작가의 설정에 따른 창작의 가능성 제공 서비스
● 본 사업에서 구축된 데이터를 추가하여 <스토리헬퍼 확장판> 서비스를 개발하고 나아가 인공지능 스토리 추천 및 생성 기술을 시도하는 <스토리헬퍼 AI> 서비스 개발 추진 -
데이터 성능 점수
측정값 (%)기준값 (%)데이터 성능 지표
데이터 성능 지표 번호 측정항목 AI TASK 학습모델 지표명 기준값 점수 측정값 점수 1 10-candidate selection 성능 Text Classification ScriptWriter-CPre R10@1 0.35 단위없음 0.7 단위없음 2 2-candidate selection 성능 Text Classification ScriptWriter-CPre R2@1 0.7 단위없음 0.93 단위없음
※ 데이터 성능 지표가 여러 개일 경우 각 항목을 클릭하면 해당 지표의 값이 그래프에 표기됩니다.
※ AI모델 평가 지표에 따라 측정값의 범위, 판단 기준이 달라질 수 있습니다. (ex. 오류율의 경우, 낮을수록 좋은 성능을 내는 것으로 평가됩니다)
-
설명서 및 활용가이드 다운로드
데이터 설명서 다운로드 구축활용가이드 다운로드데이터 포맷
● 작품 단위 분석 (장르, 주제, 모티프, 사서구조, 설정)과 유닛 단위 분석 (서사단계, 스토리라인, 유닛모티프, 인과관계, 인물의 감정 및 행동) 데이터를 구분하여 라벨링
● 창작이론 및 작품 분석에 근거하여 서사단계, 모티프, 주제, 인과관계, 행위, 감정 등의 분석을 체계화하고 라벨링 내용을 표준화하여 데이터 품질 및 AI학습 품질을 향상
● 작품 데이터 예시작품 데이터 예시 유형 영화 제목 수상한 그녀 에피소드번호 1 장르 스릴러 창작시점 2019 주제 구출 기본설정 프랜시스는 자신을 납치 감금한 그레타의 집요한 집착에서 벗어나려고 한다. 서사구조 스토리헬퍼 15단계 모티프 감금 주인공 순진함 갈등구조 엄마를 잃은 프랜시스는 엄마(프랜시스 모) 생각에 그레타를 좋은 친구로 생각하지만, 그레타는 프랜시스에게 집착을 한다. 등장인물 프랜시스 맥컬린 그레타 히멕 에리카 펜 크리스 맥컬린 알렉사 해먼드 브라이언 코디 사만다 베일 ● 유닛 데이터 예시 (작품별 3~50개)
유닛 데이터 형식 유닛id 6 등장인물 프랜시스 맥컬린 에리카 펜 그레타 히덱 서사단계 1st Accident 스토리라인(상황) 프랜시스의 직장으로 에리카가 찾아온다. 유닛모티프 말싸움/의견충돌 인과관계 Possession(집착) 유닛 데이터 예시 장소 인물 행동 감정 스토리스크립트 Y N N N Y 단,스크립트일 경우,G열로 한 열 들여 쓰시오. 전철 안 프랜시스 맥컬린 간다/이동한다 담담하다 프랜시스는 레스토랑으로 출근하기 위해 전철을 타고 이동한다. 전철 안 프랜시스 맥컬린 무시하다 짜증나다 프랜시스는 그레타에게 전화가 왔지만, 받지 않는다. 레스토랑 프랜시스 맥컬린 보다 짜증나다 프랜시스는 레스토랑에서 일하다가 그레타가 보낸 문자들을 확인한다. 레스토랑 프랜시스 맥컬린 연락하다 짜증나다 프랜시스는 에리카에게 전화를 건다. 레스토랑 프랜시스 맥컬린 연락하다 짜증나다 그 여자(그레타 히덱) 미쳤나봐. 계속 연락해. 에리카 집 에리카 펜 말하다 짜증나다 그 여자(그레타 히덱)가 집으로도 계속 전화해. 짜증 나. 레스토랑 헨리 말하다 담담하다 레스토랑 매니저(헨리)는 프랜시스에게 누가 찾아왔다고 말한다. 레스토랑 프랜시스 맥컬린 발견하다 짜증나다 프랜시스는 레스토랑으로 찾아온 그레타를 발견한다. 레스토랑 프랜시스 맥컬린 말하다 짜증나다 여긴 왜 온 거예요? 레스토랑 그레타 히덱 대답한다 걱정 연락이 안 되니까 걱정이 돼서 찾아왔어요. 레스토랑 프랜시스 맥컬린 말하다 화나다 프랜시스는 찬장 안에서 봤던 가방 이야기를 한다. 레스토랑 프랜시스 맥컬린 말하다 화나다 일부러 전철 안에 놓고 다니면서, 누구 하나 걸려라 그랬던 거 겠죠? 레스토랑 그레타 히덱 대답한다 당황하다 그레타는 설명할 기회를 달라고 한다. 레스토랑 프랜시스 맥컬린 말하다 화나다 프랜시스는 다시 오지 말라며 화를 낸다. 레스토랑 그레타 히멕 간다/이동한다 혼란스럽다 그레타는 알 수 없는 표정으로 레스토랑을 나간다. 어노테이션 포맷
어노테이션 포맷 구분 속성명 타입 필수여부 설명 범위 비고 1 id String y 스토리 ID type String y 스토리 유형 "movie","series","novel","comics" title String y 제목 genre[] [String] y 장르 "드라마","코미디","멜로/로맨스","액션","스릴러","SF","공포(호러)","미스터리","판타지","전쟁" year Number y 창작시점 1~2023 theme String y 주제 concept String y 기본설정 structure String y 서사구조 motif String y 스토리 모티프 main_character String y 주인공 conflict String y 갈등구조 characters[] [String] y 등장인물 2 units [Object] y 스토리 유닛 2-1 units[].id String y 스토리 유닛 ID units[].prev_id String 이전 유닛 ID 2-2 units[].next_id String 다음 유닛 ID units[].characters[] [String] y 유닛 등장인물 2-3 units[].stage String y 서사단계 units[].storyline String y 스토리라인(상황) 2-4 units[].unit_motif String 유닛 모티프 units[].causality String 인과관계 3 units[].story_scripts [Object] y 스토리 스크립트 3-1 units[].story_scripts[].type String y 스크립트 형태 "narrative", "script" units[].story_scripts[].location String y 장소 3-2 units[].story_scripts[].character[] [String] 인물 units[].story_scripts[].act String 행위 3-3 units[].story_scripts[].emotion String 감정 units[].story_scripts[].content String y 내용 - JSON 파일(스토리 텍스트 정보)
● 작품 라벨링 데이터작품 라벨링 데이터 설명 json key value 비고 필수
여부유형 type "movie" or "series" or "comics" or "novel" 영화,시리즈, Y 만화,소설 제목 title "트루먼쇼" Y 작성자 [writers] ["앤드루 니콜", "J. 마이클 스트러진스키"] Y 장르 [genre] ["드라마", "코미디","판타지"] {장르} Y 창작시점 year “1998’ Y 주제 theme "탈출" {주제} Y 기본설정 concept "트루먼은 '트루먼쇼'라는 티비쇼의 주인공. Y 트루먼의 삶과 일상은 모두 방송에 의해 조작되었다." 모티프 motif "조작된 삶" {모티프} Y 주인공 main_character "방송에 의해 조작된 삶을 사는 피해자" Y 갈등구조 conflict "조작된 방송 인물로서의 삶에서 벗어나고자 하는 트루먼과 '트루먼쇼' 유지를 위해 트루먼의 탈출을 저지하고자 하는 PD와 연기자들 " Y 유닛 목록 [units] [ unit1, unit2,unit3] Y ● 유닛 라벨링 데이터
유닛 라벨링 데이터 설명 json key value 비고 필수 여부 ID id "#7-12" Y 이전,다음ID [prev_id,next_id] ["#7-11","#7-13"] Y 등장인물 [characters] ["트루먼 ,"말론"] Y 서사단계 stage "2막피치2" 서사단계목록 Y 스토리 storyline "트루먼은 실비아를 그리워하며 잡지 사진을 오려 실비아의 얼굴을 조합해본다. 그러던 어느 날 주변의 모든 것들에 수상함을 느끼던 트루먼은 말론에게 자신이 느낀 것들을 말해보지만 말론은 과대망상이며 일축 한다." Y 라인(상황) 유닛 모티프 unit_motif "뜻밖의편지" {모티프} N 인과관계 causality N 스토리 스크립트 [story_scripts] [story_script1, story_script2, story_script3, story_script4, story_script5, story_script6, story_script7, story_script8,story_script9story_script10, story_script11,...] Y ● 줄거리/대사 데이터
줄거리/대사 데이터 설명 json key value 비고 필수여부 형태 type "narrative" "narrative"or "script" Y 내용 content "트루먼이 자신에게 일어난 일을 설명하려는데 당황해서 말을 더듬는다." Y 인물 character "트루먼" 대사일 경우 필수 N 감정 emotions "당황" 지문일 경우 필수 N 장소 location "마트" Y JSON 형식
{
"id": "01_0720",
"type": "movie",
"title": "수상한 그녀",
"genre": ["스릴러"],
"year": 2019,
"theme": "구출",
"concept": "C001는 자신을 납치 감금한 C002의 집요한 집착에서 벗어나려고 한다.",
"structure": "스토리헬퍼 15단계",
"motif": "감금",
"main_character": "순진함",
"conflict": "엄마를 잃은 C001는 엄마 생각에 C002를 좋은 친구로 생각하지만, C002는 C001에게 집착을 한다.",
"characters": ["C001", "C002", "C003"],
"units": [
{ "id": "01_0720_05" },
{
"id": "01_0720_06",
"prev_id": "01_0720_05",
"next_id": "01_0720_07",
"characters": ["C001", "C003", "E002", "C002"],
"stage": "1st Accident",
"storyline": "C001의 직장으로 C003가 찾아온다.",
"unit_motif": "말싸움/의견충돌",
"causality": "Possession(집착)",
"story_scripts": [
{ "type": "narrative", "location": "전철 안",
"character": ["C001"], "act": "무시하다", "emotion": "짜증나다",
"content": "C001는 C002에게 전화가 왔지만, 받지 않는다." },
{ "type": "narrative", "location": "레스토랑",
"character": ["C001"], "act": "연락하다", "emotion": "짜증나다",
"content": "C001는 C003에게 전화를 건다."
},
{ "type": "script", "location": "레스토랑",
"character": ["C001"], "act": "연락하다", "emotion": "짜증나다",
"content": "그 여자 미쳤나 봐. 계속 연락해."
},
{ "type": "script", "location": "C003 집",
"character": ["C003"], "act": "말하다", "emotion": "짜증나다",
"content": "그 여자가 집으로도 계속 전화해. 짜증 나."
},
{ "type": "narrative", "location": "레스토랑",
"character": ["E002"], "act": "말하다",
"content": "레스토랑 매니저는 C001에게 누가 찾아왔다고 말한다."
},
{ "type": "script", "location": "레스토랑",
"character": ["C001"], "act": "말하다", "emotion": "짜증나다",
"content": "여긴 왜 온 거예요?"
},
{ "type": "script", "location": "레스토랑",
"character": ["C002"], "act": "대답한다", "emotion": "걱정",
"content": "연락이 안 되니까 걱정이 돼서 찾아왔어요."
},
{ "type": "narrative", "location": "레스토랑",
"character": ["C001"], "act": "말하다", "emotion": "화나다",
"content": "C001는 찬장 안에서 봤던 가방 이야기를 한다."
},
{ "type": "narrative", "location": "레스토랑",
"character": ["C002"], "act": "대답한다", "emotion": "당황하다",
"content": "C002는 설명할 기회를 달라고 한다."
},
{ "type": "narrative", "location": "레스토랑",
"character": ["C001", "C002"], "act": "다투다/대립하다",
"emotion": "화나다", "content": "C001는 다신 오지 말라며 화를 낸다."
}
]
},
{ "id": "01_0720_06" }
]
} -
데이터셋 구축 담당자
수행기관(주관) : 이화여자대학교 산학협력단
수행기관(주관) 책임자명 전화번호 대표이메일 담당업무 김민수 02-3277-3353 minsookim@ewha.ac.kr AI 응용모델, 데이터 검수 수행기관(참여)
수행기관(참여) 기관명 담당업무 ㈜코테크시스템 수집,정제,저작도구개발 데이터 관련 문의처
데이터 관련 문의처 담당자명 전화번호 이메일 김민수 02-3277-3353 minsookim@ewha.ac.kr
-
인터넷과 물리적으로 분리된 온라인·오프라인 공간으로 의료 데이터를 포함하여 보안 조치가 요구되는 데이터를 다운로드 없이 접근하고 분석 가능
* 온라인 안심존 : 보안이 보장된 온라인 네트워크를 통해 집, 연구실, 사무실 등 어디서나 접속하여 데이터에 접근하고 분석
* 오프라인 안심존 : 추가적인 보안이 필요한 데이터를 대상으로 지정된 물리적 공간에서만 접속하여 데이터에 접근하고 분석 -
- AI 허브 접속
신청자 - 안심존
사용신청신청자신청서류 제출* - 심사구축기관
- 승인구축기관
- 데이터 분석 활용신청자
- 분석모델반출신청자
- AI 허브 접속
-
1. 기관생명윤리위원회(IRB) 심의 결과 통지서 [IRB 알아보기] [공용IRB 심의신청 가이드라인]
2. 기관생명윤리위원회(IRB) 승인된 연구계획서
3. 신청자 소속 증빙 서류 (재직증명서, 재학증명서, 근로계약서 등 택1)
4. 안심존 이용 신청서 [다운로드]
5. 보안서약서 [다운로드]
※ 상기 신청서 및 첨부 서류를 완비한 후 신청을 진행하셔야 정상적으로 절차가 이루어집니다. -
신청 및 이용관련 문의는 safezone1@aihub.kr 또는 02-525-7708, 7709로 문의
데이터셋 다운로드 승인이 완료 된 후 API 다운로드 서비스를 이용하실 수 있습니다.
API 다운로드 파일은 분할 압축되어 다운로드 됩니다. 분할 압축 해제를 위해서는 분할 압축 파일들의 병합이 필요하며 리눅스 명령어 사용이 필요합니다.
리눅스 OS 계열에서 다운로드 받으시길 권장하며 윈도우에서 파일 다운로드 시 wsl(리눅스용 윈도우 하위 시스템) 설치가 필요합니다.
※ 파일 병합 리눅스 명령어
find "폴더경로" -name "파일명.zip.part*" -print0 | sort -zt'.' -k2V | xargs -0 cat > "파일명.zip"
- 해당 명령어 실행 시, 실행 경로 위치에 병합 압축 파일이 생성됩니다.
- 병합된 파일 용량이 0일 경우, 제대로 병합이 되지 않은 상태이니 "폴더경로"가 제대로 입력되었는지 확인 부탁드립니다.
※ 데이터셋 소개 페이지에서 다운로드 버튼 클릭하여 승인이 필요합니다.
오프라인 데이터 이용 안내
본 데이터는 K-ICT 빅데이터센터에서도 이용하실 수 있습니다.
다양한 데이터(미개방 데이터 포함)를 분석할 수 있는 오프라인 분석공간을 제공하고 있습니다.
데이터 안심구역 이용절차 및 신청은 K-ICT빅데이터센터 홈페이지를 참고하시기 바랍니다.

국방데이터 개방 안내
본 데이터는 국방데이터로 군사 보안에 따라 AI허브에서 데이터를 제공하지 않으며,
군 담당자를 통한 별도의 사용 신청이 필요합니다.