-
데이터 변경이력
데이터 변경이력 버전 일자 변경내용 비고 1.1 2023-12-22 데이터 최종 개방 1.0 2023-07-31 데이터 개방(Beta Version) 데이터 히스토리
데이터 히스토리 일자 변경내용 비고 2025-05-09 AI모델 소스코드 수정 2024-11-06 산출물 수정 데이터설명서,활용가이드라인,구축업체 정보 2024-03-05 산출물 전체 공개 소개
- 본 데이터는 경제 및 스포츠 분야의 뉴스 기사 지문(324,026건)에 숫자의 가감산, 비율연산, 날짜의 가감산과 추출, 양자 혹은 다자 대상의 수량적 비교 등의 숫자연산이 포함된 질의와 이에 대응하는 응답(414,940쌍)을 라벨링한 인공지능 학습용 데이터임
구축목적
- 숫자연산이 포함된 질의에 대한 응답을 주어진 지문으로부터 도출하는 수리추론 능력을 갖춘 인공지능 기계독해 모델의 학습에 필요한 데이터셋의 구축
-
메타데이터 구조표 데이터 영역 한국어 데이터 유형 텍스트 데이터 형식 txt 데이터 출처 신문 및 방송 라벨링 유형 질의응답(자연어) 라벨링 형식 JSON 데이터 활용 서비스 질의응답 서비스, 챗봇 서비스 등 데이터 구축년도/
데이터 구축량2022년/지문: 324,026건, 질의응답: 414,940쌍 -
○ 데이터 통계
- 구축 규모데이터 통계 - 구축 규모 도메인 지문 질의응답쌍 지문 유형 항목 수 합계 응답 유형 연산 유형 항목 수 합계 경제 1지문 1질의응답 118,428 164,561 Number 가산/감산 50,625 210,694 비율연산 33,459 소계 84,084 Date 날짜가산/감산 11,709 날짜추출 26,431 1지문 2질의응답 46,133 소계 38,140 Spans 양자/다자비교 37,581 경계추출 25,772 단서추출 25,117 소계 88,470 스포츠 1지문 1질의응답 114,684 159,465 Number 가산/감산 49,135 204,246 비율연산 28,749 소계 77,884 Date 날짜가산/감산 11,368 날짜추출 27,076 1지문 2질의응답 44,781 소계 38,444 Spans 양자/다자비교 38,811 경계추출 25,889 단서추출 23,218 소계 87,918 총계 1지문 1질의응답 233,112 324,026 Number 가산/감산 99,760 414,940 비율연산 62,208 소계 161,968 Date 날짜가산/감산 23,077 날짜추출 53,507 1지문 2질의응답 90,914 소계 76,584 Spans 양자/다자비교 76,392 경계추출 51,661 단서추출 48,335 소계 176,388 - 도메인 분포
데이터 통계 - 도메인 분포 도메인 지문 항목 수 비율 경제 164,561 50.79% 스포츠 159,465 49.21% 합계 324,026 100.00% 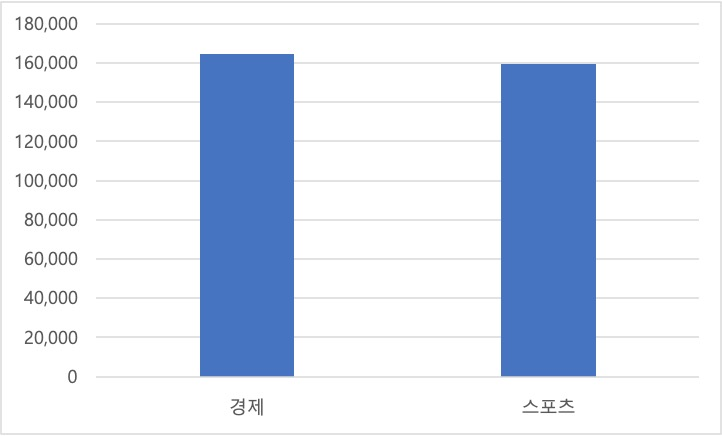
- 지문 유형별 분포
데이터 통계 - 지문 유형별 분포 지문 유형 지문 항목 수 비율 1지문 1질의응답 233,112 71.94% 1지문 2질의응답 90,914 28.06% 합계 324,026 100.00% 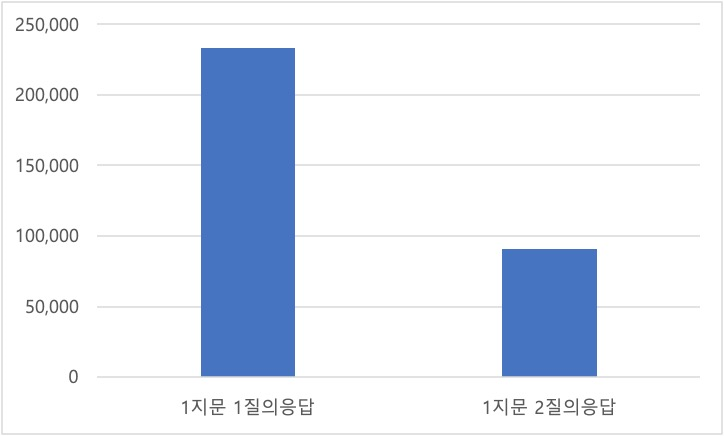
- 응답 유형별 분포
데이터 통계 - 응답 유형별 분포 응답 유형 질의응답쌍 항목 수 비율 number 161,968 39.03% date 76,584 18.46% spans 176,388 42.51% 합계 414,940 100.00% 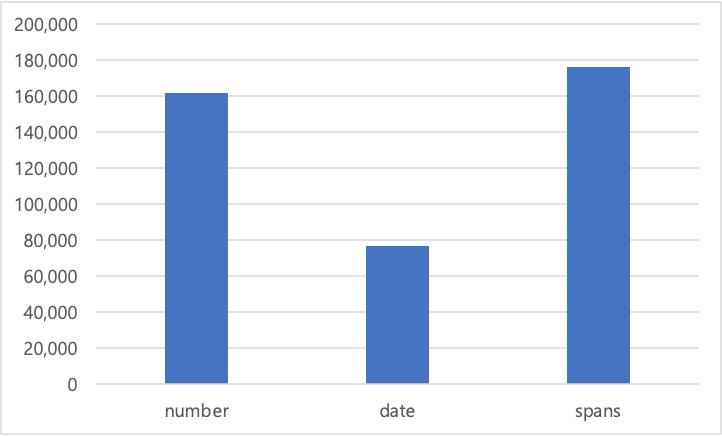
- 연산 유형별 분포
데이터 통계 - 연산 유형별 분포 응답 유형 연산 유형 질의응답쌍 항목 수 비율 number 가산/감산 99,760 24.04% 비율연산 62,208 14.99% date 날짜가산/감산 23,077 5.56% 날짜추출 53,507 12.90% spans 양자/다자비교 76,392 18.41% 경계추출 51,661 12.45% 단서추출 48,335 11.65% 합계 414,940 100.00% 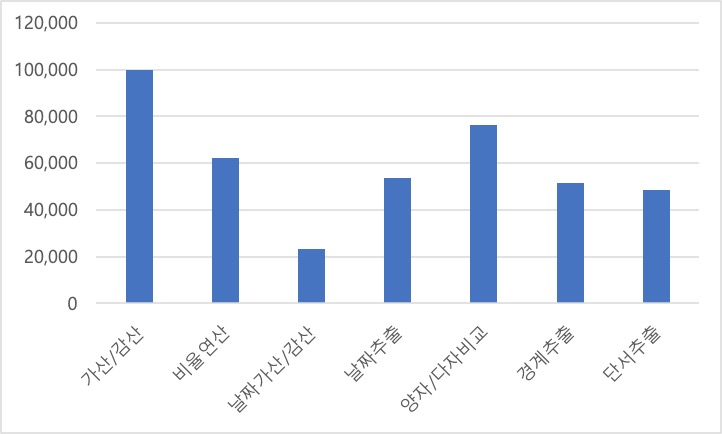
-
-
AI 모델 상세 설명서 다운로드
AI 모델 상세 설명서 다운로드 AI 모델 다운로드○ 활용 모델
- 모델 개요
● 숫자연산 기계독해 AI 모델의 명칭은 한국어 기반 NumNet+ 모델로서 영어 기반 NumNet+ 모델에 기초를 두고 있음
● NumNet+ 모델의 기반 모델인 NumNet은 숫자들의 크기 비교 등을 포함하는 수치추론(numerical reasoning)을 담당하는 숫자 인식 그래프 신경망(NumGNN: Numerically aware Graph Neural Network)을 도입하여 정수뿐 아니라 실수도 다룰 수 있으며, 비율 계산 등의 복잡한 계산을 다룰 수 있는 모델로 영어 이산추론(Discrete Reasoning) 데이터셋인 DROP에 적용하여 67.97%의 F1 점수를 획득함(Ran et al 2019)
● NumNet+(https://github.com/llamazing/numnet_plus)는 NumNet과 유사한 접근을 하나 사전학습 언어모델로 BERT 계열의 RoBERTa를 사용하며, DROP 리더보드에서 F1 84.84를 기록하였음(https://leaderboard.allenai.org/drop/submission/bmfuq9e0v32fq8pskug0)
● 한국어 기반 NumNet+ 모델은 영어 기반 NumNet+ 모델에 기초하며, 사전학습 언어모델로 한국어 RoBERTa 모델인 KLUE-Roberta Large(https://huggingface.co/klue/roberta-large)를 사용함- 모델 구조
● NumNet+ 모델은 크게 입력층, 인코더, 숫자 인식 그래프 신경망(NumGNN), 그리고 응답 모듈로 구성됨
● 입력층은 토큰화된 질의(question)와 지문(passage)를 이어붙여 구성함
● 인코더는 사전학습 언어모델인 RoBERTa 기반의 인코더임
● 숫자 인식 그래프 신경망은 다층으로 구성되어 지문에 등장한 숫자들의 비교 연산 등의 수치추론을 담당함
● 응답 모듈은 Number, Date, Spans 응답 유형(answer type)을 예측하는 부분(type prediction)과 각 응답 유형에 적합한 응답을 예측하는 부분으로 구성됨
● NumNet+의 구조를 도식화하면 아래 그림과 같음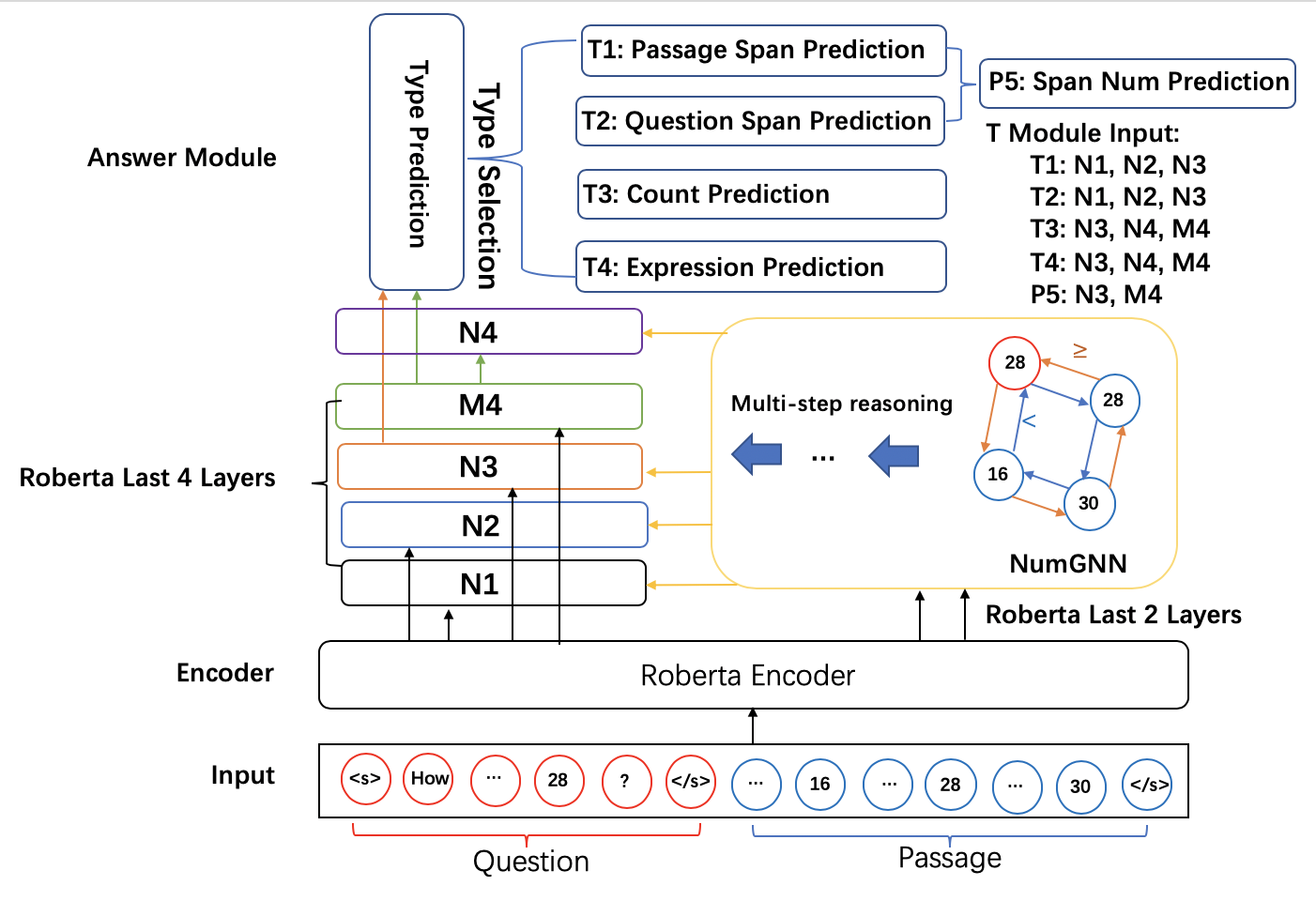
- 학습 데이터셋
● 한국어 기반 NumNet+ 모델의 학습(training), 검증(validation), 평가(evaluation)에 사용된 숫자연산 기계독해 데이터의 구성은 다음과 같음학습 데이터셋 데이터셋 정답 유형 합계 number date spans 항목수 비율 항목수 비율 항목수 비율 항목수 비율 Training 129,574 80% 61,267 80% 141,110 80% 331,951 80% Validation 16,196 10% 7,658 10% 17,638 10% 41,492 10% Test 16,198 10% 7,659 10% 17,640 10% 41,497 10% 합계 161,968 100% 76,584 100% 176,388 100% 414,940 100% 구성비 39.03% 18.46% 42.51% - 학습 환경
● Ubuntu 18.04.5 LTS (GNU/Linux 4.15.0-162-generic x86_64)
● Python 3.8
● CUDA- 학습 수행 방법
● AI 모델 설명서 참조○ 활용 분야
- 숫자연산이 필요한 비대면 대국민 서비스를 제공하는 공공기관 및 단체
● 통계청 등에서 각종 통계 수치 간 연산을 통해 사용자 맞춤형 챗봇 서비스에 활용 가능
● 국세청의 비대면 세무행정 서비스 구축의 일환인 챗봇 서비스 운영
● 부가가치세, 소득세 등의 자동 세무 상담
● 연말정산, 학자금 등의 국세 행정까지 처리 가능한 챗봇 고도화 계획에 부합함
- 금융, 스포츠, 우주과학 등 숫자연산이 필요한 산업 분야
● 특정 분야 중심의 기계독해 데이터셋은 해당 분야에 특화된 인공지능 응용 서비스 개발에 활용
● 고도화된 RPA(Robotic Process Automation) 시스템에 기계독해 기술을 더하여 영업 현장에서 금융 상품 안내의 효율성을 높일 수 있음
● 스포츠 산업에서 각종 스포츠 규정 문서를 읽고 이해하고 경기 결과를 분석해 스포츠 경기 운영의 공정성과 효율성 제고, 심판의 주관적인 해석의 영역 축소 및 판정 근거로 활용
- 핀테크, 리걸테크, 레그테크, AICC 등의 서비스 분야
● 기존 컨택트 센터의 물리적인 한계 극복 및 상담사의 감정노동 강도를 줄이는 방안
● 공공기관, 대기업, 벤처기업, 스타트업, 소상공인까지 고객 응대 서비스 제공에 효과적으로 기여함
● 고객의 -
데이터 성능 점수
측정값 (%)기준값 (%)데이터 성능 지표
데이터 성능 지표 번호 측정항목 AI TASK 학습모델 지표명 기준값 점수 측정값 점수 1 질의응답 성능 Question Answering NumNet+ for Korean Dataset F1-Score 0.55 점 0.5965 점
※ 데이터 성능 지표가 여러 개일 경우 각 항목을 클릭하면 해당 지표의 값이 그래프에 표기됩니다.
※ AI모델 평가 지표에 따라 측정값의 범위, 판단 기준이 달라질 수 있습니다. (ex. 오류율의 경우, 낮을수록 좋은 성능을 내는 것으로 평가됩니다)
-
설명서 및 활용가이드 다운로드
데이터 설명서 다운로드 구축활용가이드 다운로드○ 데이터 포맷
- 원시 데이터데이터 포맷 - 원시 데이터
{
"news_id": "02100311.20190730122326001",
"title": "<코>액션스퀘어, 매도잔량 1324% 급증",
"content": "오후 12시 21분 현재 액션스퀘어(205500)의 매도잔량이 34,045주로 1분전 매도잔량 2,390주 대비 1324% 급증했다. 거래대금은 177억8,088만이며 거래량은 621만3,439주로 거래량회전율은 23.46%로 나타났다. \n \n \n \n \n이 시각 현재 액션스퀘어는 26.27% 내린 2,835원에 거래되고 있으며, 42(매도):58(매수)의 매수우위를 기록하고 있다. \n \n[이 기사는 증시분석 전문기자 서경뉴스봇(newsbot@sedaily.com)이 실시간으로 작성했습니다.]/서경뉴스봇 newsbot@sedaily.com",
"published_at": "2019-07-30T00:00:00.000+09:00",
"enveloped_at": "2019-07-30T12:23:26.000+09:00",
"dateline": "2019-07-30T12:22:22.000+09:00",
"provider": "서울경제",
"category": [
"경제>증권_증시",
"경제>유통",
"경제>부동산"
],
"category_incident": [],
"byline": "뉴스봇",
"provider_link_page": "http://www.sedaily.com/NewsView/1VLW93NDRW"
}- 원천 데이터(정제 이후)
데이터 포맷 - 원천 데이터(정제 이후)
{
"idx":"kpf.02100311.20190730122326001",
"mediatype":"뉴스",
"medianame":"서울경제",
"category":"경제",
"source":"http://www.sedaily.com/NewsView/1VLW93NDRW",
"date":"2019-07-30",
"title":"<코>액션스퀘어, 매도잔량 1324% 급증",
"passage":"오후 12시 21분 현재 액션스퀘어(205500)의 매도잔량이 34,045주로 1분전 매도잔량 2,390주 대비 1324% 급증했다. 거래대금은 177억8,088만이며 거래량은 621만3,439주로 거래량회전율은 23.46%로 나타났다.\n이 시각 현재 액션스퀘어는 26.27% 내린 2,835원에 거래되고 있으며, 42(매도):58(매수)의 매수우위를 기록하고 있다."
}- 라벨링 데이터(가공 이후)
데이터 포맷 - 라벨링 데이터(가공 이후)
{
"idx":"kpf.02100311.20190730122326001",
"mediatype":"뉴스",
"medianame":"서울경제",
"category":"경제",
"source":"http://www.sedaily.com/NewsView/1VLW93NDRW",
"date":"2019-07-30",
"title":"<코>액션스퀘어, 매도잔량 1324% 급증",
"passage":"오후 12시 21분 현재 액션스퀘어(205500)의 매도잔량이 34,045주로 1분전 매도잔량 2,390주 대비 1324% 급증했다. 거래대금은 177억8,088만이며 거래량은 621만3,439주로 거래량회전율은 23.46%로 나타났다.\n이 시각 현재 액션스퀘어는 26.27% 내린 2,835원에 거래되고 있으며, 42(매도):58(매수)의 매수우위를 기록하고 있다.",
"qa_pairs":[
{
"query_id":"f91275e3-d051-4e4d-affc-ff38f0258051",
"question":"12시 21분 액션스퀘어의 매도 잔량은 1분 전 매도 잔량보다 몇 주 증가했는가?",
"answer":{
"number":{
"calculation":"34045-2390",
"calculation_type":"가산/감산",
"number":"31655",
"transcription":"삼만천육백오십오",
"unit":"주"
},
"date":null,
"spans":null
}
}
]
}○ 데이터 구성
데이터 구성 Key Description Type Child Type dataset 메타정보 객체 JsonObject identifier 데이터셋 식별자 String name 데이터셋 명칭 String category 데이터셋 범주 String type 데이터셋 타입 String data 데이터 JsonArray [ 데이터 배열 JsonArray JsonObject idx 데이터 인덱스 String mediatype 미디어유형 String medianame 미디어명칭 String category 기사 범주 String source 기사 URL String date 기사 게재일 String title 기사 제목 String passage 지문 String qa_pairs 질의응답쌍 JsonArray [ 질의응답쌍 배열 JsonArray JsonObject { 질의응답쌍 JsonObject query_id 질의 ID String question 질의 String answer 응답 객체 JsonObject JsonObject number Number 응답 String calculation 수식 String calculation_type 연산유형 String number 응답 String transcription 숫자 응답 문자 표기 String unit 단위어 String date Date 응답 JsonObject calculation_type 연산유형 String year 연 String month 월 String day 일 String spans Spans 응답 JsonArray [ Spans 응답 배열 JsonArray JsonObject calculation 수식 String calculation_type 연산유형 String text 응답문자열 String start_index 응답 시작 위치 Number end_index 응답 끝 위치 Number ] } ] ] ○ 어노테이션 포맷
어노테이션 포맷 번호 항목 길이 타입 필수여부 비고 국문명 영문명 1 메타정보 객체 dataset JsonObject 1-1 데이터셋 식별자 identifier String Y 기정의 값 1-2 데이터셋 명칭 name String Y 기정의 값 1-3 데이터셋 범주 category String Y 기정의 값 1-4 데이터셋 타입 type String Y 기정의 값 2 데이터 data Array Y 2-1 데이터 배열 [ Array Y 2-1-1 데이터 항목 { JsonObject Y 2-1-1-1 데이터 인덱스 idx String Y 기정의 값 2-1-1-2 미디어유형 mediatype String Y 기정의 값 2-1-1-3 미디어명칭 medianame String Y 기정의 값 2-1-1-4 기사 범주 category String Y 기정의 값 2-1-1-5 기사 URL source String Y URL 2-1-1-6 기사 게재일 date String Y YYYY-MM-DD 2-1-1-7 기사 제목 title String Y 2-1-1-8 지문 passage [150-1000] String Y 2-1-1-9 질의응답 qa_pairs Array Y 2-1-1-9-1 질의응답쌍배열 [ Array Y 2-1-1-9-1-1 질의응답쌍 { JsonObject Y 2-1-1-9-1-1-1 질의 ID query_id String Y UUID 2-1-1-9-1-1-2 질의 question [20-100] String Y 2-1-1-9-1-1-3 응답 객체 answer JsonObject 2-1-1-9-1-1-3-1 Number 응답 number JsonObject 2-1-1-9-1-1-3-1-1 수식 calculation String Y 2-1-1-9-1-1-3-1-2 연산유형 calculation_type String Y 기정의 값 2-1-1-9-1-1-3-1-3 응답 number String Y 2-1-1-9-1-1-3-1-4 숫자응답문자표기 transcription String Y 2-1-1-9-1-1-3-1-5 단위어 unit String Y 2-1-1-9-1-1-3-2 Date 응답 date JsonObject - 2-1-1-9-1-1-3-2-1 연산유형 calculation_type String Y 기정의 값 2-1-1-9-1-1-3-2-2 연 year 4 String Y YYYY 2-1-1-9-1-1-3-2-3 월 month 2 String Y MM 2-1-1-9-1-1-3-2-4 일 day 2 String Y DD 2-1-1-9-1-1-3-3 Spans 응답 spans Array Y 2-1-1-9-1-1-3-3-1 Spans 응답배열 [ Array Y 2-1-1-9-1-1-3-3-1-1 Spans 응답항목 { JsonObject Y 2-1-1-9-1-1-3-3-1-1-1 수식 calculation String Y 2-1-1-9-1-1-3-3-1-1-2 연산유형 calculation_type String Y 기정의 값 2-1-1-9-1-1-3-3-1-1-3 응답문자열 text [1-999] String Y 2-1-1-9-1-1-3-3-1-1-4 응답 시작 위치 start_index [0-1000] Integer Y 2-1-1-9-1-1-3-3-1-1-5 응답 끝 위치 end_index [0-1000] Integer Y } ] } ] } ] - JSON 어노테이션 항목 기정의 값
JSON 어노테이션 항목 기정의 값 번호 항목 유형 값 국문명 영문명 1-1 데이터셋 식별자 identifier 문자열 “TEXT_MRC_NO” 1-2 데이터셋 명칭 name 문자열 “숫자연산기계독해데이터” 1-3 데이터셋 범주 category 정수 2 1-4 데이터셋 타입 type 정수 0 2-1-1-1 데이터 인덱스 idx 정규식 “^kpf\.[0-9]{8}.[0-9]{17}(P[0-9]{3}L?)?$|^skhan\.[0-9]{15}(P[0-9]{3}L?)?$” 2-1-1-2 미디어 유형 mediatype 문자열 “뉴스” 2-1-1-3 미디어 명칭 mediatype 나열형 ["KBS", "MBC", "SBS", "YTN", "강원일보", "경기일보", "광주일보", "국민일보", "노컷뉴스", "뉴스핌", "데일리안", "매일신문", "머니투데이", "부산일보", "서울경제", "서울신문", "세계일보", "스포츠>경향", "스포츠서울", "스포츠월드", "아시아경제", "아주경제", "영남일보", "이데일리", "이투데이", "전남일보", "중부일보", "한겨레", "한국일보", "한라일보", "헤럴드경제"] 2-1-1-4 기사 범주 category 나열형 [“경제”, “스포츠”] 2-1-1-0-1-1-3-1-2 연산 유형 calculation_type 나열형 [“가산/감산”, “비율연산”] 2-1-1-0-1-1-3-2-1 연산 유형 calculation_type 나열형 [“날짜가산/감산”, “날짜추출”] 2-1-1-0-1-1-3-3-1-1-5 연산 유형 calculation_type 나열형 [“단서추출”, “경계추출”, “양자/다자비교”] ○ 실제 예시
-
데이터셋 구축 담당자
수행기관(주관) : 주식회사 바이브컴퍼니
수행기관(주관) 책임자명 전화번호 대표이메일 담당업무 김수경 02-565-0531 ckaskan@vaiv.kr 실무책임자 수행기관(참여)
수행기관(참여) 기관명 담당업무 주식회사 딥네츄럴 데이터 가공 및 검수 주식회사 포티투마루 AI 모델링 데이터 관련 문의처
데이터 관련 문의처 담당자명 전화번호 이메일 김수경 02-565-0531 ckaskan@vaiv.kr
-
인터넷과 물리적으로 분리된 온라인·오프라인 공간으로 의료 데이터를 포함하여 보안 조치가 요구되는 데이터를 다운로드 없이 접근하고 분석 가능
* 온라인 안심존 : 보안이 보장된 온라인 네트워크를 통해 집, 연구실, 사무실 등 어디서나 접속하여 데이터에 접근하고 분석
* 오프라인 안심존 : 추가적인 보안이 필요한 데이터를 대상으로 지정된 물리적 공간에서만 접속하여 데이터에 접근하고 분석 -
- AI 허브 접속
신청자 - 안심존
사용신청신청자신청서류 제출* - 심사구축기관
- 승인구축기관
- 데이터 분석 활용신청자
- 분석모델반출신청자
- AI 허브 접속
-
1. 기관생명윤리위원회(IRB) 심의 결과 통지서 [IRB 알아보기] [공용IRB 심의신청 가이드라인]
2. 기관생명윤리위원회(IRB) 승인된 연구계획서
3. 신청자 소속 증빙 서류 (재직증명서, 재학증명서, 근로계약서 등 택1)
4. 안심존 이용 신청서 [다운로드]
5. 보안서약서 [다운로드]
※ 상기 신청서 및 첨부 서류를 완비한 후 신청을 진행하셔야 정상적으로 절차가 이루어집니다. -
신청 및 이용관련 문의는 safezone1@aihub.kr 또는 02-525-7708, 7709로 문의
데이터셋 다운로드 승인이 완료 된 후 API 다운로드 서비스를 이용하실 수 있습니다.
API 다운로드 파일은 분할 압축되어 다운로드 됩니다. 분할 압축 해제를 위해서는 분할 압축 파일들의 병합이 필요하며 리눅스 명령어 사용이 필요합니다.
리눅스 OS 계열에서 다운로드 받으시길 권장하며 윈도우에서 파일 다운로드 시 wsl(리눅스용 윈도우 하위 시스템) 설치가 필요합니다.
※ 파일 병합 리눅스 명령어
find "폴더경로" -name "파일명.zip.part*" -print0 | sort -zt'.' -k2V | xargs -0 cat > "파일명.zip"
- 해당 명령어 실행 시, 실행 경로 위치에 병합 압축 파일이 생성됩니다.
- 병합된 파일 용량이 0일 경우, 제대로 병합이 되지 않은 상태이니 "폴더경로"가 제대로 입력되었는지 확인 부탁드립니다.
※ 데이터셋 소개 페이지에서 다운로드 버튼 클릭하여 승인이 필요합니다.
오프라인 데이터 이용 안내
본 데이터는 K-ICT 빅데이터센터에서도 이용하실 수 있습니다.
다양한 데이터(미개방 데이터 포함)를 분석할 수 있는 오프라인 분석공간을 제공하고 있습니다.
데이터 안심구역 이용절차 및 신청은 K-ICT빅데이터센터 홈페이지를 참고하시기 바랍니다.

국방데이터 개방 안내
본 데이터는 국방데이터로 군사 보안에 따라 AI허브에서 데이터를 제공하지 않으며,
군 담당자를 통한 별도의 사용 신청이 필요합니다.