-
데이터 변경이력
데이터 변경이력 버전 일자 변경내용 비고 1.1 2023-12-13 데이터 최종 개방 1.0 2023-07-31 데이터 개방(Beta Version) 데이터 히스토리
데이터 히스토리 일자 변경내용 비고 2023-12-27 산출물 전체 공개 소개
실제 채용면접과 유사한 환경의 질문과 답변의 음성을 제작하여 텍스트로 변환한후 내용 요약, 채용면접에서 표현되는 답변의 감정과 의도를 라벨링하여 원격 면접의 서비스를 고도화
구축목적
언어적 분석이 가능한 채용 면접 인터뷰 데이터셋 구축을 통해 인공지능 국가 기술력 제고, 일자리 창출, AI 면접 서비스 활용 및 확산
-
메타데이터 구조표 데이터 영역 한국어 데이터 유형 오디오 , 텍스트 데이터 형식 면접 원천 데이터 : wav 파일 , 라벨링 데이터 : json 형식의 text 파일 데이터 출처 모의 면접 형식으로 직접 제작 라벨링 유형 stt전사 (텍스), 감정/의도 라벨링(텍스트), 내용요약(텍스트) 라벨링 형식 json 데이터 활용 서비스 음성 기반의 원격 면접 서비스, 화자의 감정/의도 판단 관련 서비스 데이터 구축년도/
데이터 구축량2022년/라벨링 데이터 84,134건, 원천 데이터 168,268건, 음성원천 데이터 용량 약 245GB -
데이터 통계
<데이터 규축 규모>
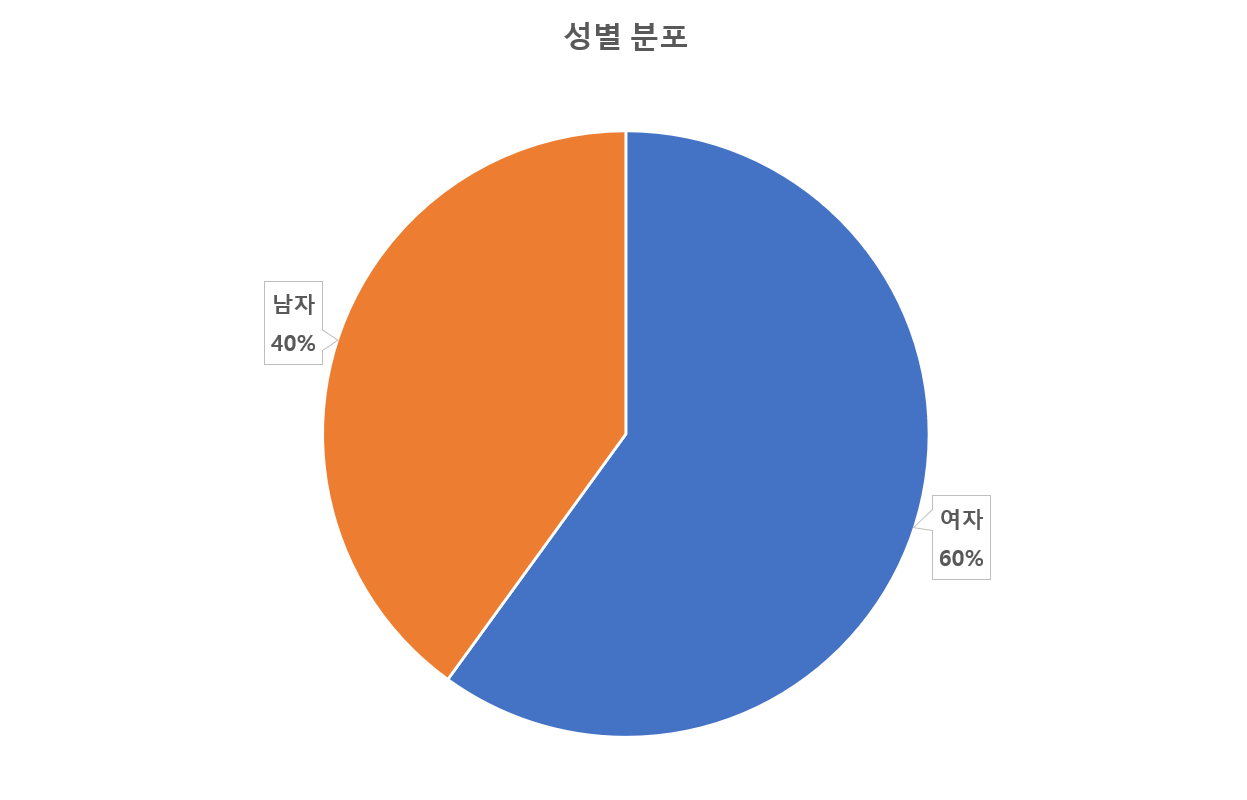
라벨링 데이터 84,134건, 원천 데이터 168,268건직군 성별 경력/신입 파일 포맷 라벨링(건) 원천(건) 01.Management Female Experienced text 1,289 2,578 New text 10,334 20,668 Male Experienced text 1,700 3,400 New text 5,668 11,336 02.SalesMarketing Female Experienced text 1,057 2,114 New text 7,444 14,888 Male Experienced text 1,378 2,756 New text 4,015 8,030 03.PublicService Female Experienced text 2,019 4,038 New text 12,866 25,732 Male Experienced text 1,123 2,246 New text 5,248 10,496 04.RND Female Experienced text 98 196 New text 2,310 4,620 Male Experienced text 375 750 New text 3,164 6,328 05.ICT Female Experienced text 226 452 New text 2,189 4,378 Male Experienced text 585 1,170 New text 4,299 8,598 06.Design Female Experienced text 482 964 New text 5,407 10,814 Male Experienced text 199 398 New text 2,063 4,126 07.ProductionManufacturing Female Experienced text 262 524 New text 4,490 8,980 Male Experienced text 650 1,300 New text 3,194 6,388 <데이터 분포>
직군 비율(%) 성별 비율(%) 경력/신입 비율(%) 01.Management 22.60% Female 13.81% Experienced 1.53% New 12.28% Male 8.76% Experienced 2.02% New 6.74% 02.SalesMarketing 16.50% Female 10.10% Experienced 1.26% New 8.85% Male 6.41% Experienced 1.64% New 4.77% 03.PublicService 25.30% Female 17.69% Experienced 2.40% New 15.29% Male 7.57% Experienced 1.33% New 6.24% 04.RND 7.10% Female 2.86% Experienced 0.12% New 2.75% Male 4.21% Experienced 0.45% New 3.76% 05.ICT 8.70% Female 2.87% Experienced 0.27% New 2.60% Male 5.81% Experienced 0.70% New 5.11% 06.Design 9.70% Female 7.00% Experienced 0.57% New 6.43% Male 2.69% Experienced 0.24% New 2.45% 07.ProductionManufacturing 10.20% Female 5.65% Experienced 0.31% New 5.34% Male 4.57% Experienced 0.77% New 3.80% 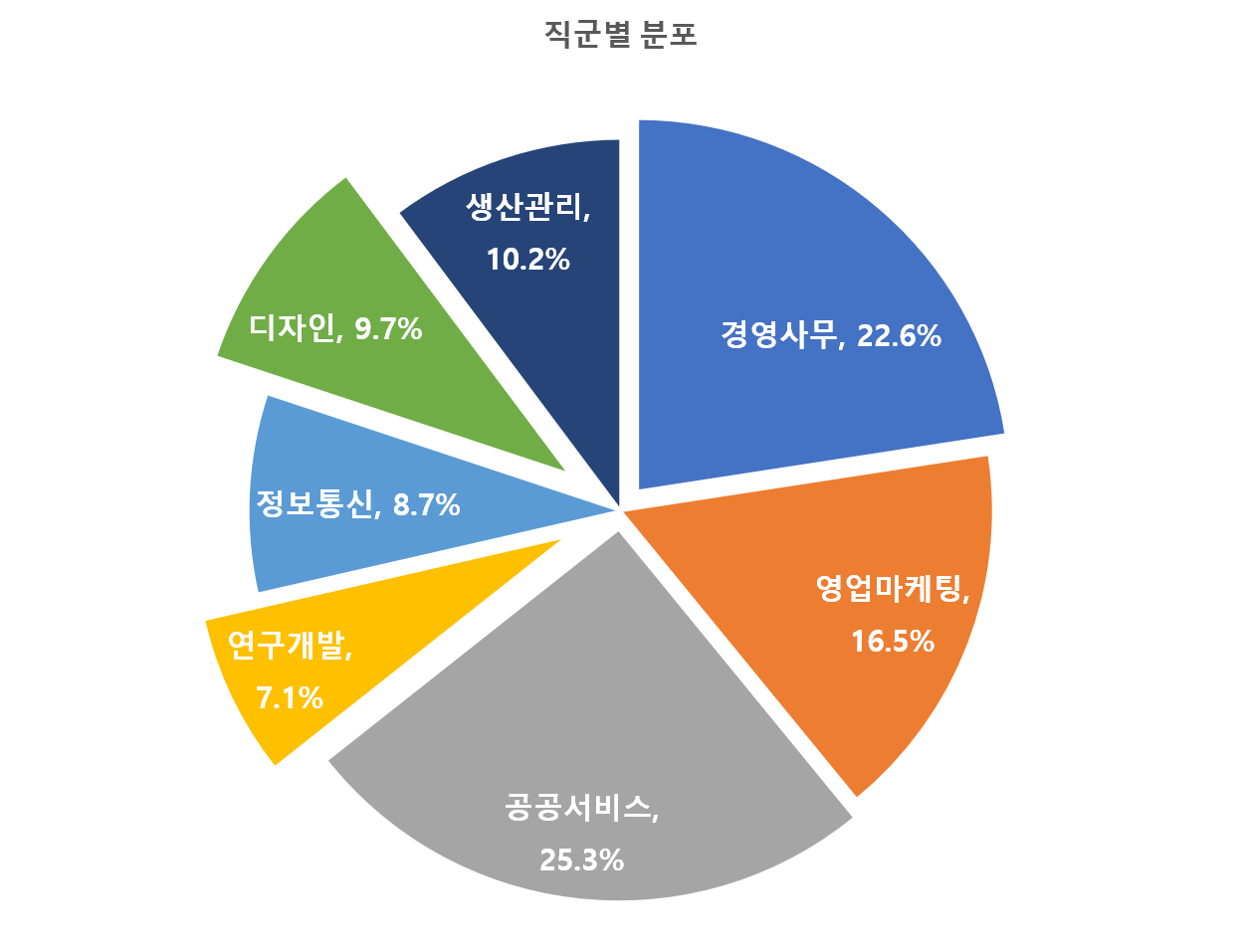
-
-
AI 모델 상세 설명서 다운로드
AI 모델 상세 설명서 다운로드 AI 모델 다운로드활용모델
<모델학습>
항목명 면접 데이터 스크립트의 감정 분석 학습 알고리즘 KoBERT BERT 원리 - 문장을 토큰화 시키고, 토큰 임베딩 - position embeddings(문장 내의 위치정보)를 더함 - 문장을 position embeddings와 함께 BERT layer에 Input 수행 - BERT 모델은 트랜스포머 모델 기반으로, 트랜스포머의 인코더 부분으로 구성 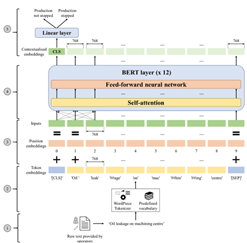
KoBERT 학습 방법 ➀ 면접 데이터 전처리 진행(불용어 제거 및 토큰화) ➁ 감정(긍정, 부정, 중립)이 라밸링된 값과 같이 모델에 넣고 학습 진행 ➂ 감정의 예측 값과 실제 값의 오차를 통해 가중치를 업데이트하면서 감정 분류가 원활하도록 학습 진행 학습 조건 num_epochs = 20, batch_size = 64, optimizer = AdamW lr (learning_rate) = 5e-5, loss_fn = CrossEntropyLoss 파일 형식 • 학습 데이터셋: JSON • 평가 데이터셋: JSON 전체 구축 데이터 대비 모델에 적용되는 비율 AI모델 사용 라벨링 데이터 비율(수량) - 클래스 1 (부정) : 100% (1,518건) - 클래스 2 (중립) : 100% (6,596건) - 클래스 3 (긍정) : 100% (5,994건) 모델 학습 과정별 데이터 분류 및 비율 정보 - Training Set 비율(수량) (1) 클래스 1 (부정) : 80% (1,213건) (2) 클래스 2 (중립) : 80% (5,289건) (3) 클래스 3 (긍정) : 80% (4,847건) - Validation Set 비율(수량) (1) 클래스 1 (부정) : 10% (153건) (2) 클래스 2 (중립) : 10% (641건) (3) 클래스 3 (긍정) : 10% (573건) - Test Set 비율(수량) (1) 클래스 1 (부정) : 10% (152건) (2) 클래스 2 (중립) : 10% (666건) (3) 클래스 3 (긍정) : 10% (574건) 항목명 면접 데이터의 스크립트 요약 학습 알고리즘 KoBART 모델 개요 - BART: Bidirectional(BERT)과 Auto-Regressive(GPT) Transformer를 합친 모델, seq2seq transformer를 사용한 구조이다, - Bart는 손상된 텍스트로 학습하며, 출력과 원본의 loss를 줄이는 데에 목표가 있다. - 손상된(masking된) 문서는 왼쪽의 bidirectional encoder(bert)로 인코딩 되고, 정답 text에 대한 likelihood를 autoregressive decoder(GPT)로 계산한다. - 위와 같은 작동방식은 nosing이 자유롭다는 장점이 있다. 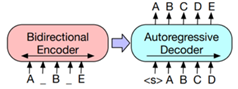
세부구조/사전학습 원리 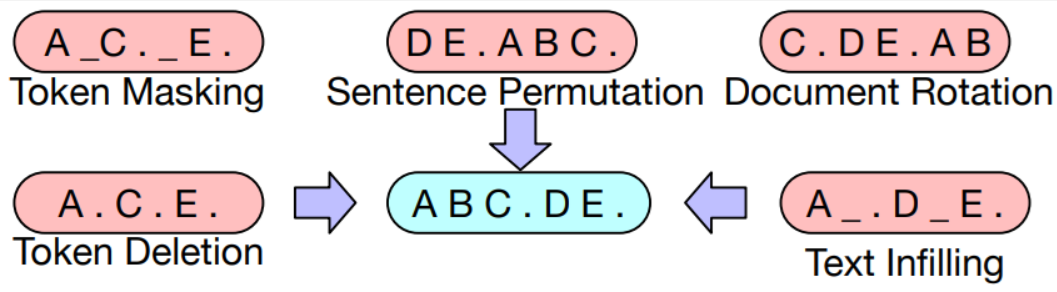
BART에서 사용한 5가지 기법 1) Token Masking: 랜덤 토큰을 masking(가린다)하고 이를 복구하는 방식 2) Token Deletion: 랜덤 토큰을 삭제하고 이를 복구하는 방식 (Masking과의 차이점은 어떤 위치의 토큰이 지워졌는지 알 수 없다는 점) 3) Text Infilling: 포아송 분포를 따르는 길이의 text span을 생성 -> 이를 하나의 토큰으로 처리해 masking 하는 방식. (여러 토큰이 하나의 mask 토큰으로 바뀔 수 있다. Mask된 길이는 모른다) 4) Sentence Permutaion: Document를 문장 단위로 나눠서 섞음 5) Document Rotation: 랜덤으로 토큰 하나를 정해서 그 토큰부터 문장이 시작되게 함. 학습 조건 ephoc 5, batch size=64, optimizer=adamW 파일 형식 • 학습 데이터셋: JSON • 평가 데이터셋: JSON 전체 구축 데이터 대비 모델에 적용되는 비율 AI 모델 사용 라벨링 데이터 수량 (비율) 요약문이 있는 84,134건 모델 학습 과정별 데이터 분류 및 비율 정보 - Training Set 비율 (수량) : 80% (67,307건) - Validation Set : 10% (8,414건) - Test Set : 10% (8,413건) 항목명 면접 데이터의 스크립트 STT 학습 알고리즘 joint CTC transformer 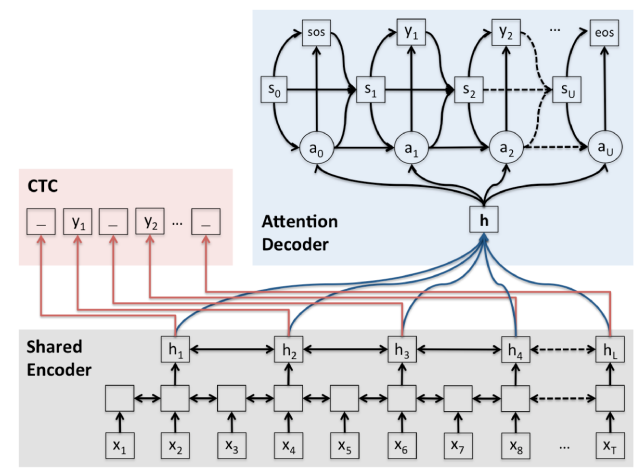
- ESPNet 프로젝트의 핵심 구성원들이 제안한 모델. E2E 음성 인식 분야의 주요 학습 기법인 CTC(Connectionist Temporal Classification)와 Attention 기법을 학습 단계에 함께 적용하여 multi-task learning을 진행하고, 실제 추론 시에는 가중치를 부여하여 추론 결과에 반영하는 방식. - CTC는 입력되는 음성 신호가 프레임 단위로 명시적인 라벨링이 되어 있지 않고 (음성 파일과 텍스트 라벨링만 있을 때) 정답 레이블 시퀀스 길이가 l일 때, 레이블 시퀀스 시작과 끝, 음절 사이에 공백(blank, ‘_’)을 추가한 길이 (l x 2) + 1의 확률 벡터 시퀀스를 만들고 이를 학습해서 프레임 단위 라벨링을 자가 학습시키는 기법. 즉 CTC를 사용한다면 음성 신호를 음성 프레임 각각으로 분리하고 음소 라벨링을 하는 작업을 대체할 수 있음. 학습 조건 EspnetLanguageModel epoch : 200, batch : N-batch = 2848, Optimizer : Adam EspnetASRModel epoch : 500, batch : N-batch = 2630, Optimizer : Adam 파일 형식 • 학습 데이터셋: TXT, WAV, TRN • 평가 데이터셋: TXT, WAV, TRN 전체 구축 데이터 대비 모델에 적용되는 비율 AI모델 사용 raw 데이터 비율 -100% 모델 학습 과정별 데이터 분류 및 비율 정보 Training Set 비율 : 80% Validation Set 비율 : 10% Test Set 비율 : 10% -
데이터 성능 점수
측정값 (%)기준값 (%)데이터 성능 지표
데이터 성능 지표 번호 측정항목 AI TASK 학습모델 지표명 기준값 점수 측정값 점수 1 감정 분류 Audio Classification KoBERT Accuracy 90 % 95.19 % 2 음성인식 Speech Recognition joint CTC transformer CER 20 % 12.55 % 3 요약 Text Summary KoBART ROUGE-{Recall} 50 % 67.76 % 4 요약 Text Summary KoBART ROUGE-{Precision} 50 % 64.34 % 5 음성인식 Speech Recognition joint CTC transformer WER 10 % 3.57 %
※ 데이터 성능 지표가 여러 개일 경우 각 항목을 클릭하면 해당 지표의 값이 그래프에 표기됩니다.
※ AI모델 평가 지표에 따라 측정값의 범위, 판단 기준이 달라질 수 있습니다. (ex. 오류율의 경우, 낮을수록 좋은 성능을 내는 것으로 평가됩니다)
-
설명서 및 활용가이드 다운로드
데이터 설명서 다운로드 구축활용가이드 다운로드<데이터 포맷>
{
"version": json 파일 버젼
"dataSet": { //데이터셋 구조체
"info": { //메타데이터 정보
"date": //작성일자
"occupation": //직업군
"channel": //원천 데이터 제작 채널
"place": //면접 장소
"gender": //성별
"ageRange": //나이대
"experience": //경력 여부
},
"question": { //질문 원천 데이터
"raw": { //원천 데이터
"text": //질문 텍스트
"wordCount"://어절수
},
"emotion": [ //감정 라벨링 데이터
],
"intent": [//의도 라벨링 데이터
]
},
"answer": { //답변 원천 데이터
"raw": { //원천 데이터
"text": //답변 텍스트
"wordCount": //어절수
},
"emotion": [ //감정 라벨링 데이터
{
"text": //감정 라벨링 데이터
"expression": //상세 감정 라벨링
"category": //상위 감정 라벨링
}
],
"intent": [ //의도 라벨링 데이터
{
"text": //의도 라벨링 데이터
"expression": //상세 의도 라벨링
"category": //상의 의도 라벨링
}
],
"summary": { //요약 데이터
"text": //요약 원천데이터 라벨링 데이터
"wordCount": //어절수
}
}
},
"rawDataInfo": { //음성 원천 데이터 정보
"question": { //질문 음성 원천 데이터 정보
"fileFormat": //원천 원천 데이터 포맷
"fileSize": //음성 원천 데이터파일 사이즈
"duration": //음성 원천 데이터 길이
"samplingBit": //음성 원천 데이터 샘플링 BIT
"channelCount": //음성 원천 데이터 녹음 채널 수
"samplingRate": //음성 원천 데이터 샘플링 RATE
"audioPath": //음성 원천 데이터 저장 위치
},
"answer": { //답변 음성 원천 데이터 정보
"fileFormat": //원천 원천 데이터 포맷
"fileSize": //음성 원천 데이터파일 사이즈
"duration": //음성 원천 데이터 길이
"samplingBit": //음성 원천 데이터 샘플링 BIT
"channelCount": //음성 원천 데이터 녹음 채널 수
"samplingRate": //음성 원천 데이터 샘플링 RATE
"audioPath": //음성 원천 데이터 저장 위치
}
}
}<데이터 구성>
key Description Type ChildType date 데이터셋(json) 생성 날짜 string occupation 채용면접 직군 string channel 면접형식(FACE-TO-FACE) string place 면접장소 string gender 성별 (FEMALE, MALE) string ageRange 나이대 string experience 경력여부 string question 질문 대화내용 string text 대화 텍스트 string wordCount 대화 내용 어절 수 number emotion 감정 라벨링 string category 감정/의도/역량 대분류 string expression 상세 감정/역량 string intent 질문 의도 라벨링 string answer 답변 내용 string summary 답변 요약 string fileFormat 원천데이터 파일 포맷 (wav) string fileSize 파일 사이즈(byte) number duration 원천데이터 파일길이(ms) number samplingBit 원천데이터 음성 샘플링 비트 number channelCount 원천데이터 음성 채널(1ch) number samplingRate 원천데이터 음성 샘플링 레이트 string audioPath 음성파일 폴더 및 파일명 string <어노테이션 포맷>
구 분 속성명 타입 필수 설명 범위 1 version string y 데이터셋 버전 정보 (1.0) 2 dataSet 데이터셋 2-1 info string y 채용면접 메타 정보 2-1-1 date string y 데이터셋(json) 생성 날짜 20221229 2-1-2 occupation string y 채용면접 직군 "BM", "SM", "PS", "RND", "ICT", "ARD", "MM 2-1-3 channel string y 면접형식(FACE-TO-FACE) “MOCK“, ”FACE-TO-FACE“ 2-1-4 place string y 면접장소 “ONLINE“, ”OFFLINE” 2-1-5 gender string y 성별 (FEMALE, MALE) FEMAIL, MAILE 2-1-6 ageRange string y 나이 “-34“, “35-44“, “45-54“, “55-“ 2-1-7 experience string y 경력여부 “NEW”,“EXPERIENCED” 2-2 question 질문 대화내용 2-2-1 raw string y 질문 원천 데이터 2-2-1-1 text string y 질문 대화 텍스트 2-2-1-2 wordCount number y 대화 내용 어절 수 2-2-2 emotion 질문 감정 라벨링 2-2-2-1 text string n 감정 태깅 질문 텍스트 2-2-2-2 category string n 감정 대분류 2-2-2-3 expression string n 상세 감정 2-2-3 intent 질문 의도 라벨링 2-2-3-1 text string n 의도 태깅 질문 텍스트 2-2-3-2 category string n 직군별 질문 상위 특성/역량 지식/기술, 태도, 공통 2-2-3-3 expression string n 답변내용의 하위특성/역량 2-3 answer 답변 내용 2-3-1 raw y 답변 내용 원천 데이터 2-3-1-1 text string y 답변내용 텍스트 2-3-1-2 wordCount number y 답변내용 어절수 1~1000 2-3-2 emotion 감정 라벨링 2-3-2-1 text string y 답변내용의 해당 감정 대화 내용 2-3-2-2 category string y 감정 대분류 (“긍정”, “부정”, “중립”) “positive”, “negative”, “neutral” 2-3-2-3 expression string y 상세 감정 2-3-3 intent 의도 라벨링 2-3-3-1 text string y 답변내용의 해당 의도 대화 내용 2-3-3-2 category string n 답변내용의 상위 특성/역량 (지식/기술, 태도, 공통) 답변내용의 상위 특성/역량 (지식/기술, 태도, 공통) 다양성 항목중 실무(직무)면접 및 인성 면접 구분 실무(직무) 면접 : "technology", "attitude" 인성 면접: "background", "personality" ,"etc" 2-3-3-3 expression string y 답변내용의 하위(상세) 특성/역량 (해당직군별 역량) 2-3-4 summary string y 답변 요약 2-3-4-1 text string y 답변 내용의 요약 2-3-4-2 wordCount number y 답변 내용 요약의 어절수 1~1000 2-4 rawdataInfo 원천데이터 메타 정보 2-4-1 question 질문 원천 데이터 메타 정보 2-4-1-1 fileFormat string y 원천데이터 파일 포맷 (wav) 2-4-1-2 fileSize number y 파일 사이즈(byte) 2-4-1-3 duration number y 원천데이터 파일길이(ms) 2-4-1-4 samplingBit number y 원천데이터 음성 샘플링 비트 2-4-1-5 channelCount number y 원천데이터 음성 채널(1ch) 2-4-1-6 samplingRate string y 원천데이터 음성 샘플링 레이트 2-4-1-7 audioPath string y 음성파일 폴더 및 파일명 2-4-2 answer 답변 원천 데이터 메타 정보 2-4-2-1 fileFormat string y 원천데이터 파일 포맷 (wav) 2-4-2-2 fileSize number y 파일 사이즈(byte) 2-4-2-3 duration number y 원천데이터 파일길이(ms) 2-4-2-4 samplingBit number y 원천데이터 음성 샘플링 비트 2-4-2-5 channelCount number y 원천데이터 음성 채널(1ch) 2-4-2-6 samplingRate string y 원천데이터 음성 샘플링 레이트 2-4-2-7 audioPath string y 음성파일 폴더 및 파일명 <실제 예시>
{
"version": "1.0",
"dataSet": {
"info": {
"date": "20230116",
"occupation": "SM",
"channel": "MOCK",
"place": "ONLINE",
"gender": "MALE",
"ageRange": "-34",
"experience": "EXPERIENCED"
},
"question": {
"raw": {
"text": "지원자님이 생각하시기에 글로벌 인재에게 필수적인 요소는 무엇인가요 그리고 본인이 생각할 때 그러한 필수적인 요소를 위해서 지금까지 본인이 노력했던 것들은 무엇인지 궁금합니다",
"wordCount": 21
},
"emotion": [
],
"intent": [
]
},
"answer": {
"raw": {
"text": "최근에는 글로벌 인재에게 가장 중요한 요소가 협상 능력이라고 생각합니다. 과거에는 어학 능력을 가장 중요하다고 생각했다면 최근에는 협상 능력이 더 중요해졌다고 생각합니다. 언어 능력은 번역기도 있고 번역을 해주는 통역사들도 많아졌기 때문에 언어 능력보다는 이제는 협상 능력이 더 중요한 시대가 되었다고 생각합니다. 협상 능력을 갖추고 있어야만 어느 나라에 어떤 씨이오를 만나더라도 좋은 결과로 이끌어 낼 수 있기 때문입니다. 기업은 결국 이익을 극대화하는 데 있기 때문에 가장 좋은 협상을 이뤄내는 것이 기업의 이익을 극대화하는 지름길이라고 생각합니다. 이를 위해서 저는 대학원에서 협상과 관련된 수업을 듣고 실제로 기업 씨이오들과 협상을 하는 실습을 해 본 경험이 있습니다. 이런 경험을 토대로 이 회사에서도 협상에 뛰어난 인재로 성장하겠습니다.",
"wordCount": 100
},
"emotion": [
{
"text": "이를 위해서 저는 대학원에서 협상과 관련된 수업을 듣고 실제로 기업 씨이오들과 협상을 하는 실습을 해 본 경험이 있습니다.",
"expression": "u-fact",
"category": "neutral"
}
],
"intent": [
{
"text": "",
"expression": "",
"category": "attitude"
}
],
"summary": {
"text": "글로벌 인재에게 가장 중요한 요소는 협상 능력입니다. 언어 능력보다 협상 능력이 중요한 시대가 되었습니다. 좋은 협상을 이뤄내는 것이 기업의 이익을 극대화하는 지름길입니다. 대학원에서 협상 수업을 듣고 기업 씨이오들과 협상을 하는 실습을 한 경험이 있습니다. 이 회사에서도 협상에 뛰어난 인재로 성장하겠습니다.",
"wordCount": 40
}
}
},
"rawDataInfo": {
"question": {
"fileFormat": "wav",
"fileSize": 553678,
"duration": 17300,
"samplingBit": 16,
"channelCount": 1,
"samplingRate": "16kHz",
"audioPath": "/Mock/02.SalesMarketing/Male/Experienced/ckmk_q_sm_m_e_208288.wav"
},
"answer": {
"fileFormat": "wav",
"fileSize": 2736398,
"duration": 85510,
"samplingBit": 16,
"channelCount": 1,
"samplingRate": "16kHz",
"audioPath": "/Mock/02.SalesMarketing/Male/Experienced/ckmk_a_sm_m_e_208288.wav"
}
}
}
-
데이터셋 구축 담당자
수행기관(주관) : 무하유
수행기관(주관) 책임자명 전화번호 대표이메일 담당업무 왕일 1588-9784 iwang@muhayu.com 프로젝트 총괄, 데이터 라벨링, 데이터 품질 관리 수행기관(참여)
수행기관(참여) 기관명 담당업무 ㈜사람과숲 원천 데이터 구축 및 정제 ㈜넥스인테크놀로지 원천 데이터 구축 및 정제 ㈜에버영피플 데이터 정제 및 라벨링 숙명여자대학교 산학협력단 구축 데이터 활용 AI모델 설계 및 구현 데이터 관련 문의처
데이터 관련 문의처 담당자명 전화번호 이메일 왕일 1588-9784 iwang@muhayu.com
-
인터넷과 물리적으로 분리된 온라인·오프라인 공간으로 의료 데이터를 포함하여 보안 조치가 요구되는 데이터를 다운로드 없이 접근하고 분석 가능
* 온라인 안심존 : 보안이 보장된 온라인 네트워크를 통해 집, 연구실, 사무실 등 어디서나 접속하여 데이터에 접근하고 분석
* 오프라인 안심존 : 추가적인 보안이 필요한 데이터를 대상으로 지정된 물리적 공간에서만 접속하여 데이터에 접근하고 분석 -
- AI 허브 접속
신청자 - 안심존
사용신청신청자신청서류 제출* - 심사구축기관
- 승인구축기관
- 데이터 분석 활용신청자
- 분석모델반출신청자
- AI 허브 접속
-
1. 기관생명윤리위원회(IRB) 심의 결과 통지서 [IRB 알아보기] [공용IRB 심의신청 가이드라인]
2. 기관생명윤리위원회(IRB) 승인된 연구계획서
3. 신청자 소속 증빙 서류 (재직증명서, 재학증명서, 근로계약서 등 택1)
4. 안심존 이용 신청서 [다운로드]
5. 보안서약서 [다운로드]
※ 상기 신청서 및 첨부 서류를 완비한 후 신청을 진행하셔야 정상적으로 절차가 이루어집니다. -
신청 및 이용관련 문의는 safezone1@aihub.kr 또는 02-525-7708, 7709로 문의
데이터셋 다운로드 승인이 완료 된 후 API 다운로드 서비스를 이용하실 수 있습니다.
API 다운로드 파일은 분할 압축되어 다운로드 됩니다. 분할 압축 해제를 위해서는 분할 압축 파일들의 병합이 필요하며 리눅스 명령어 사용이 필요합니다.
리눅스 OS 계열에서 다운로드 받으시길 권장하며 윈도우에서 파일 다운로드 시 wsl(리눅스용 윈도우 하위 시스템) 설치가 필요합니다.
※ 파일 병합 리눅스 명령어
find "폴더경로" -name "파일명.zip.part*" -print0 | sort -zt'.' -k2V | xargs -0 cat > "파일명.zip"
- 해당 명령어 실행 시, 실행 경로 위치에 병합 압축 파일이 생성됩니다.
- 병합된 파일 용량이 0일 경우, 제대로 병합이 되지 않은 상태이니 "폴더경로"가 제대로 입력되었는지 확인 부탁드립니다.
※ 데이터셋 소개 페이지에서 다운로드 버튼 클릭하여 승인이 필요합니다.