-
데이터 변경이력
데이터 변경이력 버전 일자 변경내용 비고 1.1 2023-12-22 데이터 최종 개방 1.0 2023-07-31 데이터 개방(Beta Version) 데이터 히스토리
데이터 히스토리 일자 변경내용 비고 2025-06-17 구축업체 정보수정 2024-01-24 산출물 전체 공개 소개
인터넷 커뮤니티에서 발생하는 문화/게임 분야의 제품명, 서비스명, 특정 축약어, 특정 용어 등의 신조어 및 각종 용어를 수집, 라벨링 하여 기계가 빠르게 인식할 수 있도록 학습용 데이터를 구축함
구축목적
인터넷 커뮤니티가 활발한 사업 분야에서 발생하는 신조어 및 각종 전문용어를 기계가 빠르게 인식할 수 있도록 지원하는 데이터 생성과 소셜네트워크와 인터넷 커뮤니티를 중심으로 발생하는 신조어에 대한 목록화로 신조어 연구의 기본 자료로 활용할 수 있도록 함
-
메타데이터 구조표 데이터 영역 한국어 데이터 유형 텍스트 데이터 형식 txt 데이터 출처 인터넷 커뮤니티 게시판 라벨링 유형 단어(구문) 라벨링 및 두 단어 사이의 관계 라벨링 형식 JSON 데이터 활용 서비스 검색 및 추천 서비스, “관계 추출” 모델 개발로 활용이 가능 데이터 구축년도/
데이터 구축량2022년/용어 : 90,433건 용례 : 428,298건 -
1. 데이터 구축 규모
데이터 구축 규모 도메인 출처 용어 용례 태깅 게임 인벤/루리웹닷컴 49,348 249,389 289,264 미디어 루리웹닷컴 20,905 84,674 85,750 레저 루리웹닷컴 20,180 94,235 95,169 합계 90,433 428,298 470,183 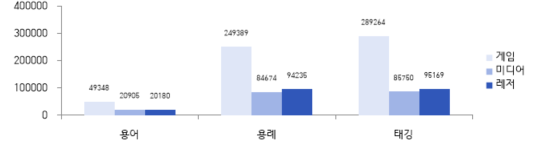
1. 데이터 분포
2.1 장르별 분포데이터 분포 - 장르별 분포 도메인 장르 용어 용례 태깅 수량 비율 수량 비율 수량 비율 게임 액션RPG 11,536 12.76% 56,582 13.21% 65,456 13.92% 게임 MMORPG 7,574 8.38% 40,177 9.38% 46,861 9.97% 게임 RPG 3,140 3.47% 13,210 3.08% 16,137 3.43% 게임 슈팅 1,121 1.24% 7,590 1.77% 8,806 1.87% 게임 스포츠 1,155 1.28% 4,822 1.13% 5,556 1.18% 게임 액션 8,070 8.92% 41,518 9.69% 47,530 10.11% 게임 전략 6,153 6.80% 34,492 8.05% 40,370 8.59% 게임 카드 10,354 11.45% 50,393 11.77% 57,927 12.32% 게임 커뮤니티어 14 0.02% 149 0.03% 165 0.04% 게임 게임공용어 231 0.26% 456 0.11% 456 0.10% 미디어 드라마 32 0.04% 258 0.06% 281 0.06% 미디어 영화 716 0.79% 4,205 0.98% 4,661 0.99% 미디어 이공사회 4,766 5.27% 9,445 2.21% 9,465 2.01% 미디어 인문예술 3,848 4.26% 7,636 1.78% 7,642 1.63% 미디어 커뮤니티어 11,543 12.76% 63,130 14.74% 63,701 13.55% 레저 놀이스포츠 2,868 3.17% 5,669 1.32% 5,686 1.21% 레저 대상도구 2,072 2.29% 4,105 0.96% 4,106 0.87% 레저 여행음식 3,594 3.97% 7,137 1.67% 7,138 1.52% 레저 커뮤니티어 11,201 12.39% 75,052 17.52% 75,723 16.11% 레저 토이 445 0.49% 2,272 0.53% 2,516 0.54% 합계 90,433 428,298 470,183 2.2 용어 품사 분포
데이터 분포 - 용어 품사 분포 구분 게임 미디어 레저 합계 일반명사(NNG) 39,590 15,335 12,304 67,229 대명사(NP) - - 2 2 준명사(NPH) 9,730 5,454 7,508 22,692 수사(NR) 4 1 - 5 동사(VV) 20 78 140 238 형용사(VA) - 13 77 90 관형사(MM) - 15 3 18 부사(MA) 2 9 89 100 감탄사(IC) 2 - 55 57 조사(JK) - - 2 2 합계 49,348 20,905 20,180 90,433 2.3 용어 패싯 분포
2.3.1 게임용어 패싯 분포 - 게임 구분 패싯 하위패싯 수량 비율 누가 온라인 주체 캐릭터 3,513 7.12% 직업 1,264 2.56% 종족 227 0.46% 계급 184 0.37% 소속 515 1.04% 역할 209 0.42% 오프라인 주체 고유명 825 1.67% 언제 일시 시즌 542 1.10% 어디서 장소 온라인 2,888 5.85% 오프라인 22 0.04% 무엇을 대상 몬스터 6,938 14.06% 동료 355 0.72% NPC 1,984 4.02% 아이템 11,361 23.02% 오브젝트 1,359 2.75% 기술 7,384 14.96% 임무 1,108 2.25% 시스템용어 8,632 17.49% 어떻게 어떻게 조작도구 38 0.08% 합계 49,348 100% 2.3.2 미디어
용어 패싯 분포 - 미디어 구분 패싯 수량 비율 누가 인물 일반인 2,595 12.41% 전문가 1,295 6.19% 연예인/스포츠인/언론인 214 1.02% 무엇을 대상 추상물 5,627 26.92% 구체물 2,478 11.85% 도구 수단 1,248 5.97% 어떻게 속성 기타 전문적 1,409 6.74% 레저/취미적 726 3.47% 연예/스포츠/언론/미디어적 427 2.04% 교육적 399 1.91% 어디서 공간 구체 공간 1,341 6.41% 가상 공간 120 0.57% 계통 분야 704 3.37% 언제 시간 역사적 87 0.42% 현대적 343 1.64% 하다 행위 기타 전문적 활동 1,226 5.86% 레저/취미 활동 228 1.09% 연예/스포츠/언론/미디어 활동 256 1.22% 교육 활동 182 0.87% 합계 20,905 100% 2.3.3 레저
용어 패싯 분포 - 레저 구분 패싯 수량 비율 누가 인물 일반인 1,393 6.90% 전문가 367 1.82% 연예인/스포츠인/언론인 226 1.12% 무엇을 대상 추상물 1,343 6.66% 구체물 7,777 38.54% 도구 수단 1,410 6.99% 어떻게 속성 기타 전문적 1,032 5.11% 레저/취미적 1,943 9.63% 연예/스포츠/언론/미디어적 548 2.72% 교육적 132 0.65% 어디서 공간 기타 전문분야계 396 1.96% 레저/취미계 996 4.94% 연예/스포츠/언론/미디어계 220 1.09% 교육계 102 0.51% 언제 시간 역사적 30 0.15% 현대적 285 1.41% 하다 행위 기타 전문적 활동 676 3.35% 레저/취미 활동 895 4.44% 연예/스포츠/언론/미디어 활동 366 1.81% 교육 활동 42 0.21% 합계 20,180 100% -
-
AI 모델 상세 설명서 다운로드
AI 모델 상세 설명서 다운로드 AI 모델 다운로드모델 학습]
용어 탐지 및 중의성 해결 모델의 학습을 위해 전체 말뭉치를 8:1:1로 분리하여 80%의 학습 말뭉치, 10%의 검증 말뭉치, 10%의 평가 말뭉치로 제시하며 각 데이터의 단위는 문장이다. 학습 말뭉치는 총 342,644문장으로 모든 학습 말뭉치를 사용하는 것은 학습 시간이 오래 소요될 수 있으므로 5만 문장을 이용하여 학습하는 것을 권장함.
모델 학습 학습(Train) 검증(Validataion) 평가(Test) 개요 - 모델의 학습 - 모델 학습 중 검증 - 모델 학습 완료 후 - GPU 활용 필수 - 성능 향상 시 모델 저장 성능 평가 필요 문장 최소 5만 문장 10%(42,831문장) 10%(42,831문장) (많을수록 성능 향상) 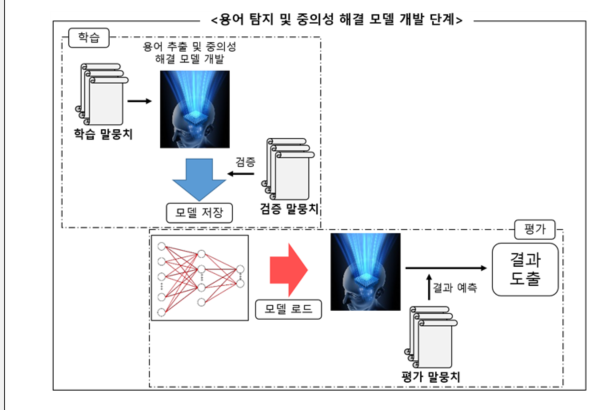
서비스 활용 시나리오]
○ 모델 활용
- 용어 추천 기능이 제공되는 동시에 해당 용어에 따른 최적화된 검색 결과까지 손쉽게 검색하는 등의 검색 및 추천 서비스에 활용 가능함.
- 게임 커뮤니티 내의 특정 기간 내 입력된 사용자의 작성글, 댓글들을 해당 모델로 분석하여 게임 트랜드 및 동향 파악 등에 활용 가능○ 코퍼스 연구 활용
- 구축된 말뭉치는 검증, 평가데이터가 분리되어 있어 사용자가 개발한 모델의 정량적, 정성적 평가가 가능함
- 구축된 데이터셋은 “용어 추출”, “중의성 해결” 등 최신 딥러닝 모델 개발에 활용될 수 있음.
- 또한, 구축된 데이터셋은 구축된 용어 간의 상위어, 하위어 등의 관계를 포함하고 있어 “관계 추출” 모델 개발에 활용도 가능하며, 용어들을 위키피디아의 개체로의 연결하는 등의 데이터 확장이 가능함. -
데이터 성능 점수
측정값 (%)기준값 (%)데이터 성능 지표
데이터 성능 지표 번호 측정항목 AI TASK 학습모델 지표명 기준값 점수 측정값 점수 1 용어 추출 유효성 검증 성능 Estimation EfficientNet D2 F1-Score 0.87 점 0.8782 점 2 용어 탐지 및 중의성 해결 성능 Estimation EfficientNet D2 F1-Score 0.84 점 0.8441 점
※ 데이터 성능 지표가 여러 개일 경우 각 항목을 클릭하면 해당 지표의 값이 그래프에 표기됩니다.
※ AI모델 평가 지표에 따라 측정값의 범위, 판단 기준이 달라질 수 있습니다. (ex. 오류율의 경우, 낮을수록 좋은 성능을 내는 것으로 평가됩니다)
-
설명서 및 활용가이드 다운로드
데이터 설명서 다운로드 구축활용가이드 다운로드1. 데이터 포맷
- JSON2. 데이터 구조
2.1 용어데이터 구조 - 용어 구분 속성명 타입 필수여부 설명 1 id int32 Y 용어의 ID 2 term string Y 용어의 한글 표기 3 sense_no int32 Y 의미번호 4 definition string Y 정의 5 pos string Y 품사, 국립국어원기준 6 bts [] Token N 상의어 6-1 bts[].id int32 Y 상위어의 ID 6-2 bts[].term int32 Y 상위어의 표제어(용어) 6-3 bts[].sense_no int32 Y 상위어의 의미번호 7 nts Source N 하위어의 배열 7-1 nts[].id string Y 하위어의 ID 7-2 nts[].term string Y 하위어의 표제어(용어) 7-3 nts[].sense_no int32 Y 하위어의 의미번호 8 rts [] Relation N 관계어의 배열 8-1 rts[].id string Y 관계어의 ID 8-2 rts[].type enum RelationSubType Y 관계의 유형 8-3 rts[].term string Y 관계어의 표제어(용어) 8-4 rts[].sense_no int32 Y 관계어의 의미번호 9 facet [] string Y 패싯 제시 10 top_level_domain string Y 최상위 도메인 11 level2 string N 레벨2 단계의 이름 12 level3 string N 레벨3 단계의 이름 2.2 용례
데이터 구조 - 용례 구분 속성명 타입 필수여부 설명 1 id int32 Y 문장의 ID 2 sentence string Y 용어가 포함된 문장 3 tokens [] Token N 위치 및 분류 3-1 tokens[].start int32 Y 시작위치 3-2 tokens[].length int32 Y 길이 3-3 tokens[].sub string Y 전체 토큰 3-4 tokens[].facet string Y 패싯 3-5 tokens[].term_id int32 Y 용어의 ID 3-6 tokens[].sense_no int32 Y 용어의 의미번호 4 source Source {} Y 4-1 source.url string Y 원 출처의 URL 4-2 source.text string Y 원 출처의 원문 4-3 source.written_at datetime Y 작성일자 2.1 데이터 예시
- 용어
{
"id": 112345,
“top level_domain”: “게임”
“level2”: “롤플레잉”
“level3”: “월드오브워크래프트”
"term": "부탱",
"sense_no": 1,
"definition": "메인 탱커를 보조하는 탱커라는 말로, 레이드와 같이 큰 규모의 전투가 진행될 때 방어를 담당하는 탱커 역할",
"pos": "NNG",
"bts": [ {"id": 12231, "term": "탱커"} ],
"nts": [],
"rts": [
{"id": 21212, "type": "origin", "term": "보조탱커"},
{"id": 21211, "type": "sibling", "term": "메인탱" }
],
"facet": ["역할"],
"top_level_domain": "게임",
"level2": "롤플레잉“
"level3": "월드오브워크래프트"
}- 용례
{
"id": 241022,
"sentence": "다음 보스에서는 부탱이 쫄어그로 먹고 뒤로 빼주세요.",
"tokens": [
{"start": 10, "length": 2, "sub": "부탱", "facet": "역할", term_id: 1122, "sense_no": 1},
{"start": 14, "length": 4, "sub": "쫄어그로", "facet": "행위", “term_id”: 2233, "sense_no": 1}
],
"source": {
"url": "https://www.inven.co.kr/blah",
"text": "다음 보스에서는 부탱이 쫄어그로 먹고 뒤로 빼주세요."
}
} -
데이터셋 구축 담당자
수행기관(주관) : ㈜나라지식정보
수행기관(주관) 책임자명 전화번호 대표이메일 담당업무 조경찬 02-3141-7644 wkcho0691@hanmail.net 사업총괄관리, 2차 집필, 데이터 품질관리 수행기관(참여)
수행기관(참여) 기관명 담당업무 루리웹닷컴 원시데이터 수집 비플라이소프트㈜ 데이터 정제 ㈜알토비전 1차 집필 ㈜인벤 원시데이터 수집 전북대학교 산학협력단 모델링 데이터 관련 문의처
데이터 관련 문의처 담당자명 전화번호 이메일 조경찬 02-3141-7644 wkcho0691@hanmail.net
-
인터넷과 물리적으로 분리된 온라인·오프라인 공간으로 의료 데이터를 포함하여 보안 조치가 요구되는 데이터를 다운로드 없이 접근하고 분석 가능
* 온라인 안심존 : 보안이 보장된 온라인 네트워크를 통해 집, 연구실, 사무실 등 어디서나 접속하여 데이터에 접근하고 분석
* 오프라인 안심존 : 추가적인 보안이 필요한 데이터를 대상으로 지정된 물리적 공간에서만 접속하여 데이터에 접근하고 분석 -
- AI 허브 접속
신청자 - 안심존
사용신청신청자신청서류 제출* - 심사구축기관
- 승인구축기관
- 데이터 분석 활용신청자
- 분석모델반출신청자
- AI 허브 접속
-
1. 기관생명윤리위원회(IRB) 심의 결과 통지서 [IRB 알아보기] [공용IRB 심의신청 가이드라인]
2. 기관생명윤리위원회(IRB) 승인된 연구계획서
3. 신청자 소속 증빙 서류 (재직증명서, 재학증명서, 근로계약서 등 택1)
4. 안심존 이용 신청서 [다운로드]
5. 보안서약서 [다운로드]
※ 상기 신청서 및 첨부 서류를 완비한 후 신청을 진행하셔야 정상적으로 절차가 이루어집니다. -
신청 및 이용관련 문의는 safezone1@aihub.kr 또는 02-525-7708, 7709로 문의
데이터셋 다운로드 승인이 완료 된 후 API 다운로드 서비스를 이용하실 수 있습니다.
API 다운로드 파일은 분할 압축되어 다운로드 됩니다. 분할 압축 해제를 위해서는 분할 압축 파일들의 병합이 필요하며 리눅스 명령어 사용이 필요합니다.
리눅스 OS 계열에서 다운로드 받으시길 권장하며 윈도우에서 파일 다운로드 시 wsl(리눅스용 윈도우 하위 시스템) 설치가 필요합니다.
※ 파일 병합 리눅스 명령어
find "폴더경로" -name "파일명.zip.part*" -print0 | sort -zt'.' -k2V | xargs -0 cat > "파일명.zip"
- 해당 명령어 실행 시, 실행 경로 위치에 병합 압축 파일이 생성됩니다.
- 병합된 파일 용량이 0일 경우, 제대로 병합이 되지 않은 상태이니 "폴더경로"가 제대로 입력되었는지 확인 부탁드립니다.
※ 데이터셋 소개 페이지에서 다운로드 버튼 클릭하여 승인이 필요합니다.
오프라인 데이터 이용 안내
본 데이터는 K-ICT 빅데이터센터에서도 이용하실 수 있습니다.
다양한 데이터(미개방 데이터 포함)를 분석할 수 있는 오프라인 분석공간을 제공하고 있습니다.
데이터 안심구역 이용절차 및 신청은 K-ICT빅데이터센터 홈페이지를 참고하시기 바랍니다.

국방데이터 개방 안내
본 데이터는 국방데이터로 군사 보안에 따라 AI허브에서 데이터를 제공하지 않으며,
군 담당자를 통한 별도의 사용 신청이 필요합니다.