-
데이터 변경이력
데이터 변경이력 버전 일자 변경내용 비고 1.0 2022-07-12 데이터 최초 개방 데이터 히스토리
데이터 히스토리 일자 변경내용 비고 2022-10-13 신규 샘플데이터 개방 2022-07-12 콘텐츠 최초 등록 소개
다양한 기상 상황에서의 주행데이터 셋을 구축하여 추후 자율주행 연구에 있어서 날씨 변수 데이터셋을 제공
구축목적
국내 자율 주행 데이터는 맑은 날씨에 대한 데이터가 현저히 많으며 기상 악천후와 같은 폭설,폭우, 도로 반사, 안개 등으로 인해 정적, 동적객체 인지가 어려운 주행환경 데이터 생성.
-
메타데이터 구조표 데이터 영역 교통물류 데이터 유형 3D , 이미지 , 텍스트 데이터 형식 txt 데이터 출처 한국전자기술연구원 라벨링 유형 2d Polygon, 3D Cuboid box 라벨링 형식 JSON 데이터 활용 서비스 센서 퓨전을 통한 차량 및 보행자 인식 기반 위험 알림 서비스, 악천후 조건을 포함한 도로 정보 인식 후 차량 속도제어 서비스, 수집된 데이터와 활용 모델을 기반으로 한 도로 상황 판단 및 예측 서비스 데이터 구축년도/
데이터 구축량2021년/Image 360,000장, Lidar 360,000장 -
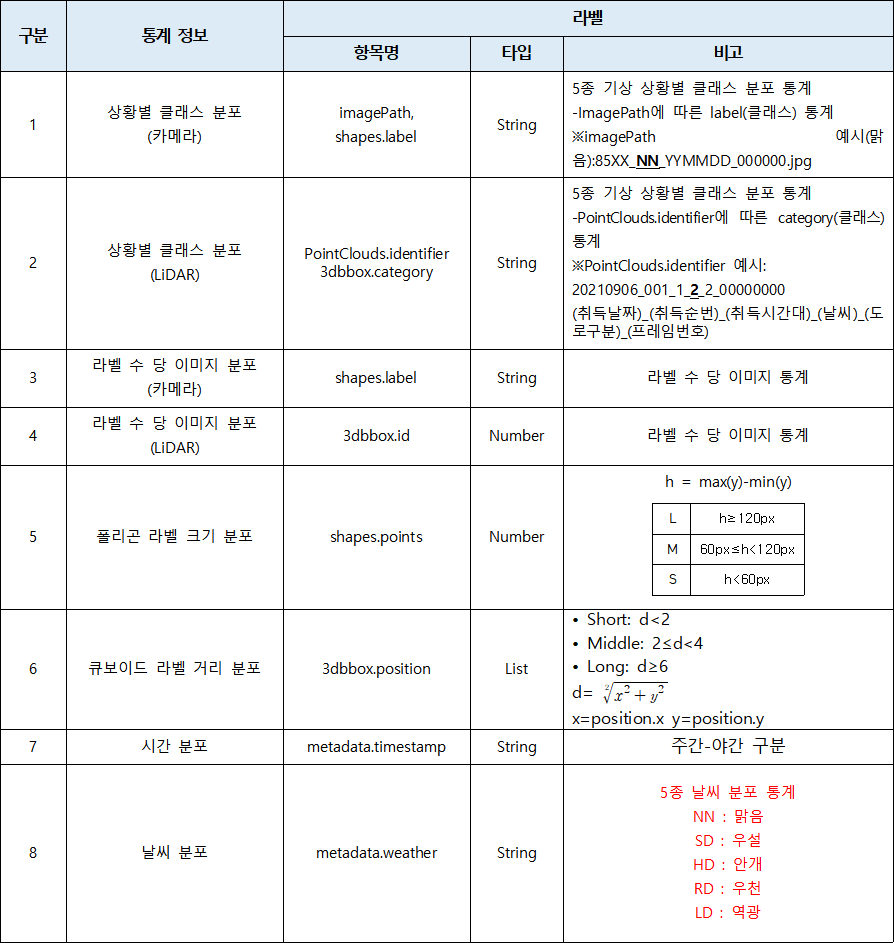
1. 데이터 구축 규모
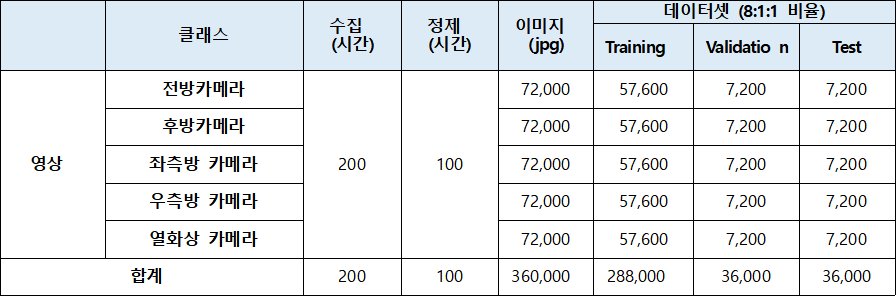
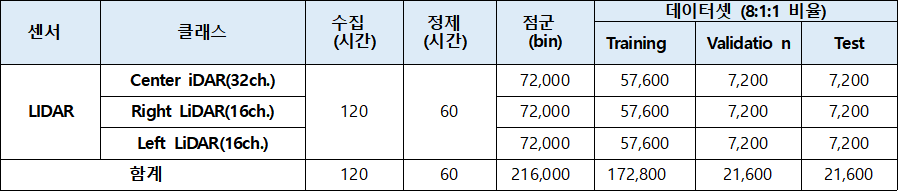
2. 데이터 분포
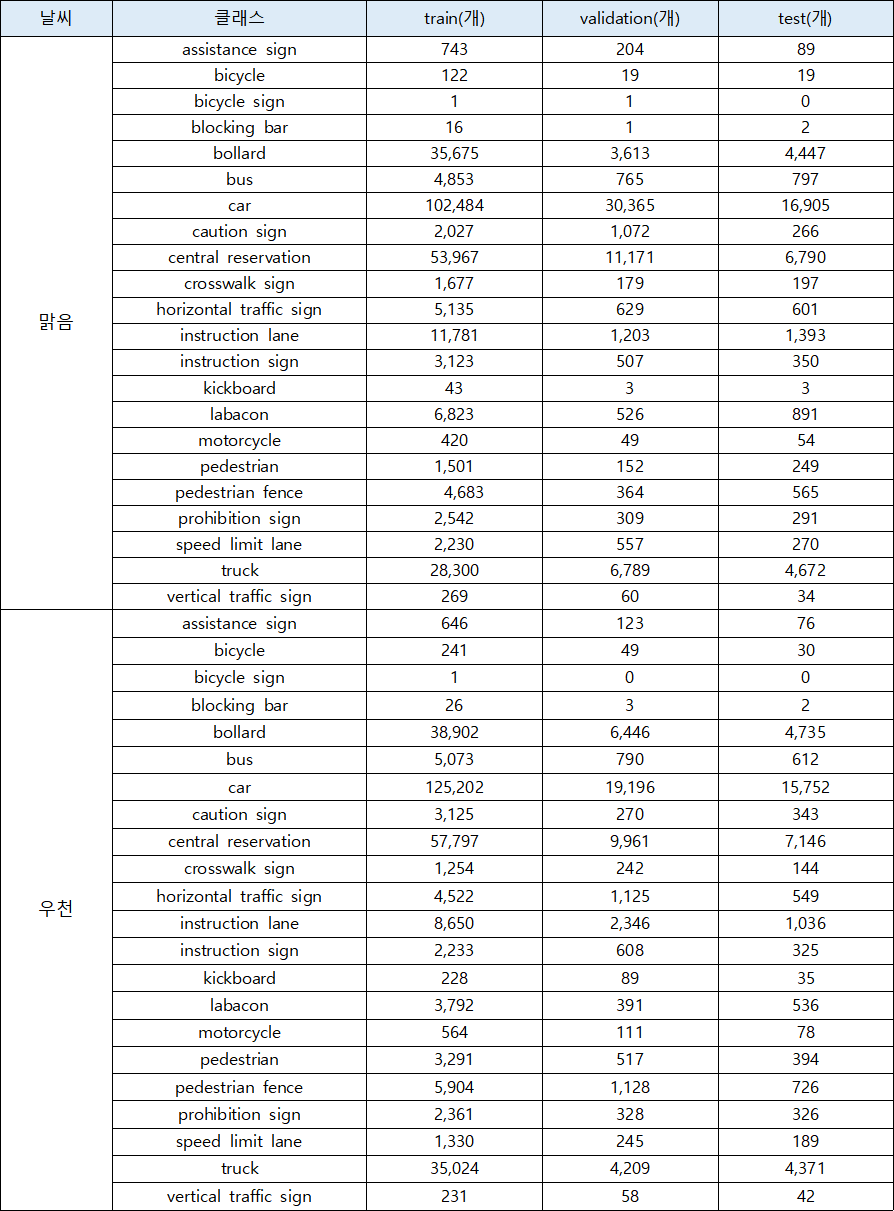
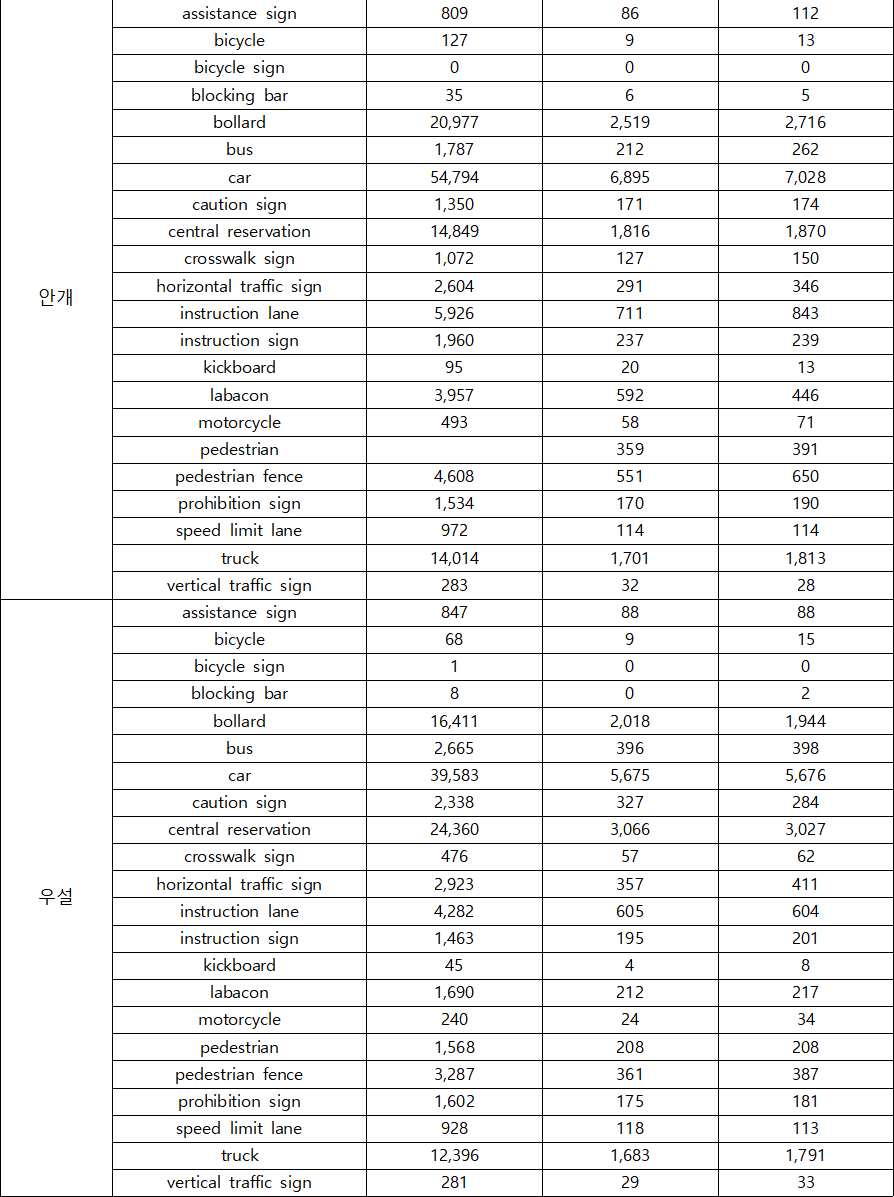
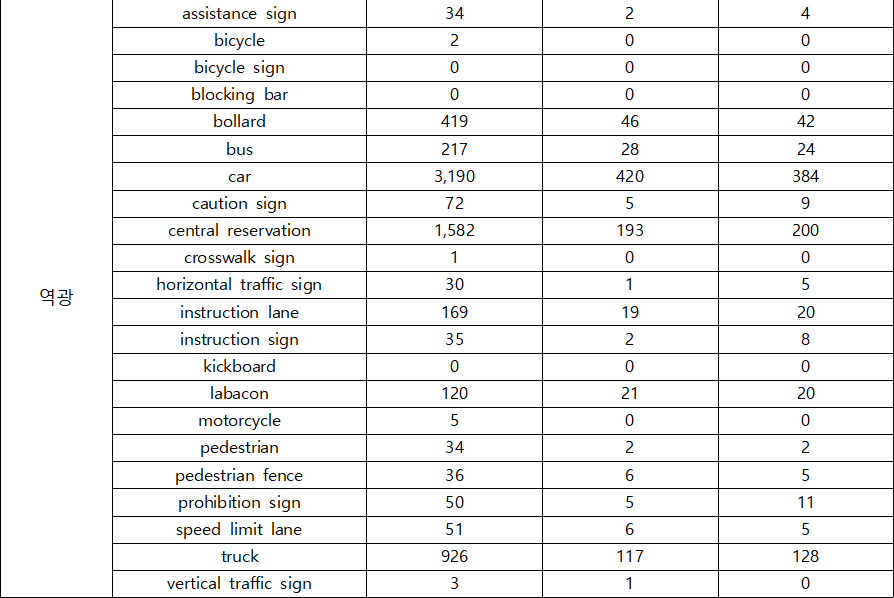
-
-
AI 모델 상세 설명서 다운로드
AI 모델 상세 설명서 다운로드 AI 모델 다운로드1. 학습 모델 선정 방안
- 객체 이미지로부터 공간정보를 포함한 메타데이터 기반 다양한 특징들을 추출 할 수 있어야 함
- 모델의 사이즈(=파라미터 수)가 커짐에 따라 발생할 수 있는 오버피팅(Overfitting) 문제를 해결할 수 있어야 함
- 변하는 계절과 날씨에 따른 자율주행 객체 인식에 대한 시계열 데이터를 지속적으로 업데이트해 줄 수 있어야 함.
- 라벨링 정보뿐만 아니라 센서의 메타 데이터를 함께 분석할 수 있어야 함
- 라벨링 정보 대비 기존 모델과 실제 유효성을 비교할 수 있어야 함
2. 모델 적합성 검토
- 서포터 벡터 머신 모델
- 서포트 벡터 머신(support vector machine, SVM)은 기계 학습의 분야 중 하나로 패턴 인식, 자료 분석을 위한 지도 학습 모델이며, 주로 분류와 회귀 분석을 위해 사용함.
- 두 카테고리 중 어느 하나에 속한 데이터의 집합이 주어졌을 때, SVM 알고리즘은 주어진 데이터 집합을 바탕으로 하여 새로운 데이터가 어느 카테고리에 속할지 판단하는 비확률적 이진 선형 분류 모델을 만듬.
- 만들어진 분류 모델은 데이터가 사상된 공간에서 경계로 표현되는데 SVM 알고리즘은 그 중 가장 큰 폭을 가진 경계를 찾는 알고리즘임
- SVM은 선형 분류와 더불어 비선형 분류에서도 사용될 수 있음. 비선형 분류를 하기 위해서 주어진 데이터를 고차원 특징 공간으로 사상하는 작업이 필요한데, 이를 효율적으로 하기 위해 커널 트릭을 사용하기도 함
- 합성곱 신경망 모델
- CNN에서는 하위 계층부터 상위 계층을 지나면서 점차 수준이 높은 특징을 추출한다. 하위 계층에서는 복수의 합성곱(convolution)과 풀링(pooling)을 통해 특징 맵(feature map) 구성
- 합성곱 계층에서는 이전 계층의 복수의 출력 값을 입력받아 공유된 가중치 연산(convolution filters) 처리를 수행하고, 풀링 계층에서는 합성곱 계층과 1:1로 연결되어 맥스-풀링(max-pooling)을 수행함.
- 맥스-풀링(Max-pooling)에서는 블록 내의 특징값 중 최대 값을 취함으로써 위치에 상관없이 특징이 되는 값은 보존하고 특징맵의 크기를 줄여 연산을 빠르게 해주는 역할을 한다. 최상위 fully-connected 계층에서는 이전 계층에서 추출된 높은 수준의 특징을 사용해 최종 인식 결과를 결정하게 됨
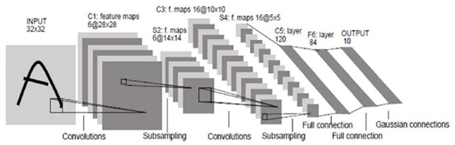
[그림 5] 합성곱 신경망 구조 예시- 순환 신경망 모델(Recurrent Neural Network, RNN)
- RNN(Recurrent Neural Network, 순환신경망)은 시퀀스 데이터를 모델링 하기 위해 사용됨.
- RNN이 기존의 뉴럴 네트워크와 다른 점은 ‘기억’(다른 말로 hidden state)을 갖고 있음. 네트워크의 기억은 지금까지의 입력 데이터를 요약한 정보임.
- 새로운 입력이 들어올 때마다 네트워크는 자신의 기억을 조금씩 수정하고, 결국 입력을 모두 처리하고 난 후 네트워크에게 남겨진 기억은 시퀀스 전체를 요약하는 정보가 됨.
- 하나의 입출력 패턴을 가진 DNN 병렬체인 구조로 연결한 형태로, 과거 학습결과를 현재학습에 사용하는 딥러닝 네트워크로서, 시계열 데이터를 처리하는데 효과적임
- RNN은 하나의 tanh 혹은 ReLU 활성화함수를 가진 구조로서, 체인이 길어지면 과거의 학습 결과가 사라지는 장기 의존성 문제가 있음
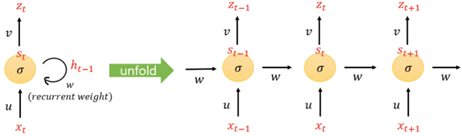
[그림 6] 순환신경망 구조 예시- 장단기 메모리 모델(Long Short Term Memory, LSTM)
- LSTM(Long Short Term Memory, 장단기 메모리 모델)은 RNN의 주요 모델 중 하나로 장기 의존성 문제를 해결할 수 있음.
- 직전 데이터 뿐만 아니라 거시적인 과거 데이터를 고려하여 미래 데이터를 예측함.
- cell-gate는 gate조절을 통해 이전 state정보가 현재 state로 끼치는 영향을 조절할 수도 있음
- 현재 입력과 경과된 정보를 추가할 수도 있으며 다시 출력에 끼치는 영향의 수준을 정할 수 있음
- 게이트(Gate)들은 선택적으로 정보들이 흘러들어갈 수 있도록 만드는 장치로 시그모이드 뉴럴넷(sigmoid neural net layer)와 dot product 연산으로 이루어져있음
- 시그모이드 레이어(Sigmoid Layer)는 0 혹은 1의 값을 출력하고 각 구성 요소가 얼마만큼의 영향을 주게 될지를 결정해주는 역할을 함
- 결과적으로 0의 값을 가지면 미래의 결과에 아무런 영향을 주지 않도록 하고 1의 값은 해당 구성요소가 확실히 미래 예측결과에 영향을 주도록 흘러가게 함.
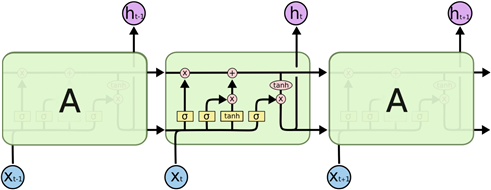
[그림 7] 장단기 메모리 구조 예시- GoogLeNet 모델
- GoogLeNet은 구글에서 발표한 22개의 레이어 층으로 구성된 CNN(Convolution Neural Network) 구조의 심층 신경망으로 ILSVRC2014(ImageNet Large-Scale Visual Recognition Challenge2014)에서 우승한 모델임
- GoogLeNet의 특징은 Inception 모듈을 통해 신경망을 더 깊고 넓게 구성하였음에도 모델의 연산량은 추가적으로 늘지 않고 정확도는 향상되었다는 것으로 Inception v1이라고도 칭함.
- Inception 모듈은 다수의 필터를 통해 입력 값에 대해 컨볼루션(Convolution)과 풀링(Pooling)을 수행한 후 생성된 특징 맵을 연결함
- 특히 1×1 컨볼루션을 통해 차원을 축소시켜 파라미터 개수와 리소스의 손실을 줄였다. 또한 관련성을 가진 노드만 연결하면서(Sparse Connectivity), 행렬연산 자체는 전결합층(Dense)으로 구성하여 성능 향상 시켰음
- 이후 VGGNet의 인수분해(Factorization) 개념을 반영하여 5×5 컨볼루션을 2번의 3×3 컨볼루션으로 개선한 Inception v2, 배치 정규화(Batch normalization) 및 필터 사이즈 감소 등을 적용한 Inceptionv3, 그리고 Inception 모듈에 ResNet의 스킵 연결(Skip Connection)을 더한 Inception-ResNet등이 있음
- 다중 모드 학습(Multi-modal Deep Learning)
- 다른 형태의 정보로 이루어진 두 개 이상의 모드 데이터를 조합하여 데이터의 특징을 효과적으로 학습하기 위한 기법이며 데이터 통합적인 분석을 하기 위해 용이
- 서로 다른 Modality를 가지고 있는 데이터 간의 충돌을 방지하기 위해 현실 상황과 비슷하게 데이터 형태에 따른 가중치(weight)를 달리한 subnetwork를 결합함
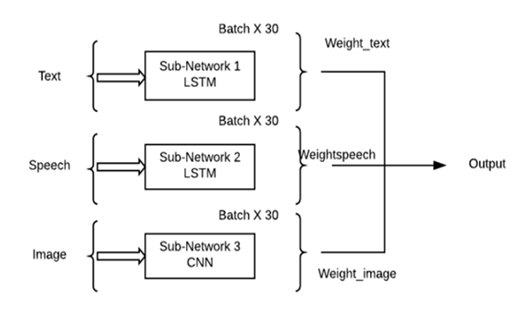
[그림 8] 다중 모드 학습 구조 예시 -
데이터 성능 점수
측정값 (%)기준값 (%)데이터 성능 지표
데이터 성능 지표 번호 측정항목 AI TASK 학습모델 지표명 기준값 점수 측정값 점수 1 큐보이드 객체 인식 Object Detection Voxel RCNN mAP 70 % 75.54 % 2 폴리곤 객체 인식(맑은(주, 야간)) Object Detection Mask-RCNN mIoU 60 % 68.39 % 3 폴리곤 객체 인식(우천) Object Detection Mask-RCNN mIoU 50 % 58.01 % 4 폴리곤 객체 인식(안개) Object Detection Mask-RCNN mIoU 50 % 64.19 % 5 폴리곤 객체 인식(역광) Object Detection Mask-RCNN mIoU 60 % 70.92 % 6 폴리곤 객체 인식(우설) Object Detection Mask-RCNN mIoU 60 % 74.17 %
※ 데이터 성능 지표가 여러 개일 경우 각 항목을 클릭하면 해당 지표의 값이 그래프에 표기됩니다.
※ AI모델 평가 지표에 따라 측정값의 범위, 판단 기준이 달라질 수 있습니다. (ex. 오류율의 경우, 낮을수록 좋은 성능을 내는 것으로 평가됩니다)
-
설명서 및 활용가이드 다운로드
데이터 설명서 다운로드 구축활용가이드 다운로드1. 폴리곤
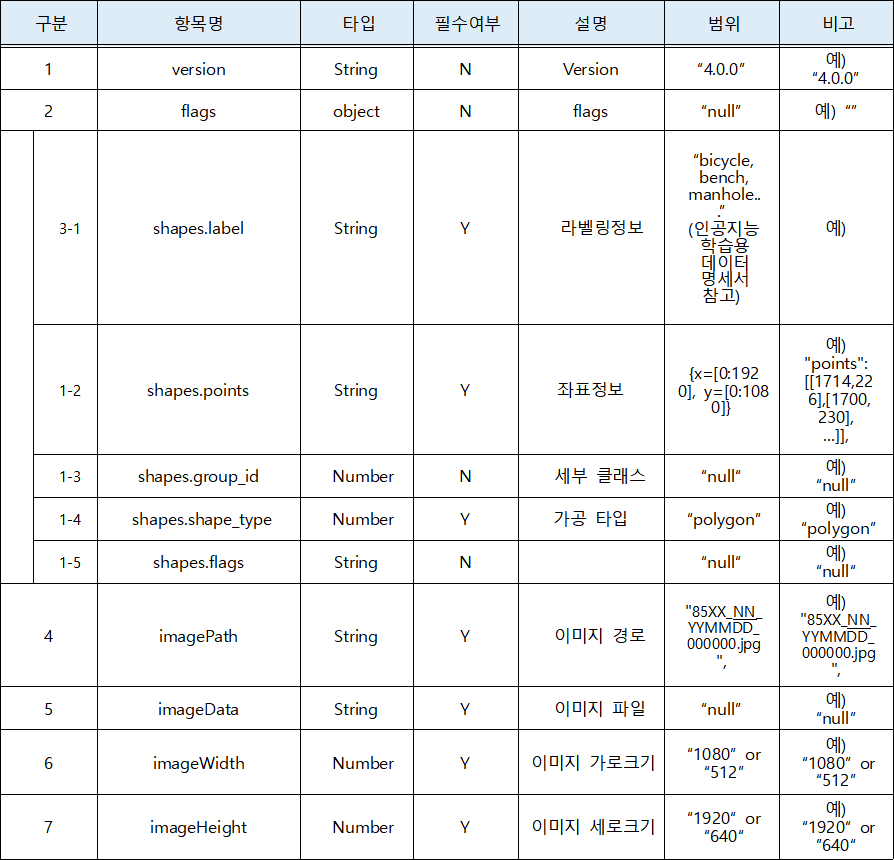
- ‘항목명’, ‘타입’, ‘설명’은 필수 입력 대상이며, ‘필수여부’에 해당하는 항목의 경우, 반드시 ‘Y’로 표기한다.
- 동일한 데이터 셋에 다수 개 스키마를 적용한 경우, 스키마 별로 라벨 구성요소를 작성한다.
2. 3D 바운딩 박스
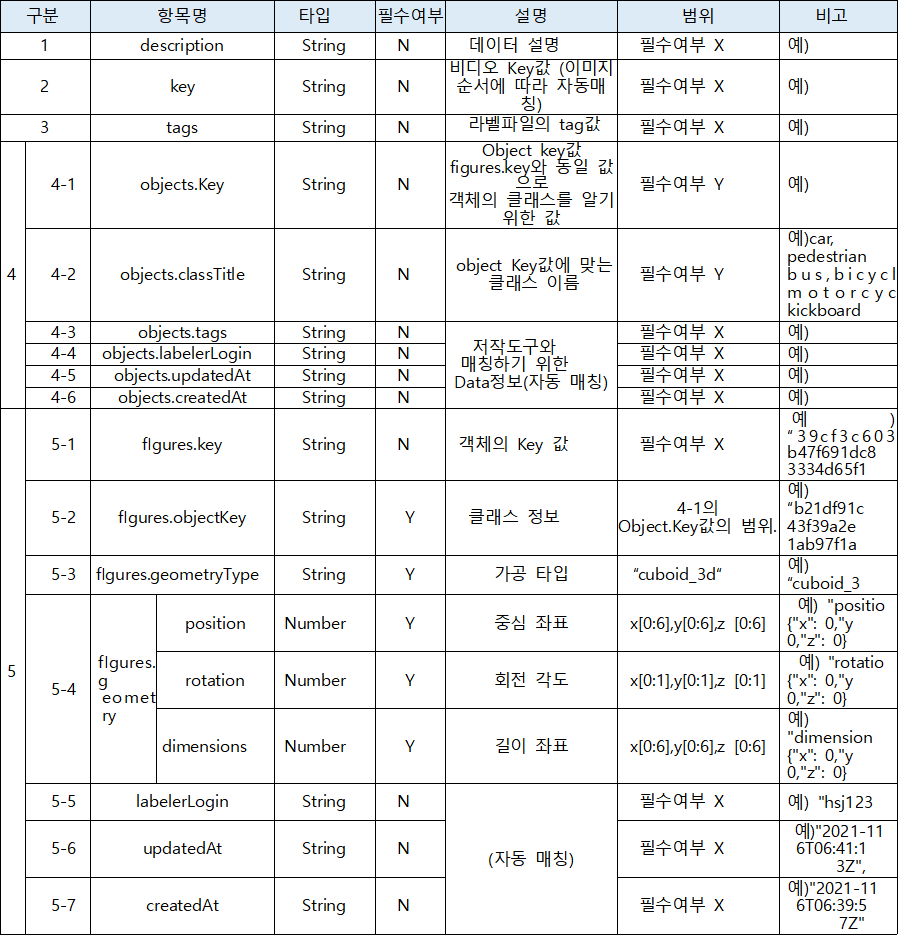
3. 라벨링데이터 실제예시

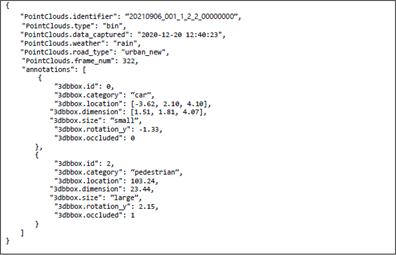
-
데이터셋 구축 담당자
수행기관(주관) : 한국전자기술연구원
수행기관(주관) 책임자명 전화번호 대표이메일 담당업무 박상현 031-739-7436 shpark@keti.re.kr · 데이터 구축 총괄 수행기관(참여)
수행기관(참여) 기관명 담당업무 ㈜인텔리전스 · 데이터 수집
· 데이터 가공㈜세보시스템즈 · 데이터 가공 ㈜어노테이션에이아이 · 데이터 가공 씨너지큐브 · 데이터 품질 검수 데이터 관련 문의처
데이터 관련 문의처 담당자명 전화번호 이메일 박상현 031-739-7436 shpark@keti.re.kr
-
인터넷과 물리적으로 분리된 온라인·오프라인 공간으로 의료 데이터를 포함하여 보안 조치가 요구되는 데이터를 다운로드 없이 접근하고 분석 가능
* 온라인 안심존 : 보안이 보장된 온라인 네트워크를 통해 집, 연구실, 사무실 등 어디서나 접속하여 데이터에 접근하고 분석
* 오프라인 안심존 : 추가적인 보안이 필요한 데이터를 대상으로 지정된 물리적 공간에서만 접속하여 데이터에 접근하고 분석 -
- AI 허브 접속
신청자 - 안심존
사용신청신청자신청서류 제출* - 심사구축기관
- 승인구축기관
- 데이터 분석 활용신청자
- 분석모델반출신청자
- AI 허브 접속
-
1. 기관생명윤리위원회(IRB) 심의 결과 통지서 [IRB 알아보기] [공용IRB 심의신청 가이드라인]
2. 기관생명윤리위원회(IRB) 승인된 연구계획서
3. 신청자 소속 증빙 서류 (재직증명서, 재학증명서, 근로계약서 등 택1)
4. 안심존 이용 신청서 [다운로드]
5. 보안서약서 [다운로드]
※ 상기 신청서 및 첨부 서류를 완비한 후 신청을 진행하셔야 정상적으로 절차가 이루어집니다. -
신청 및 이용관련 문의는 safezone1@aihub.kr 또는 02-525-7708, 7709로 문의
데이터셋 다운로드 승인이 완료 된 후 API 다운로드 서비스를 이용하실 수 있습니다.
API 다운로드 파일은 분할 압축되어 다운로드 됩니다. 분할 압축 해제를 위해서는 분할 압축 파일들의 병합이 필요하며 리눅스 명령어 사용이 필요합니다.
리눅스 OS 계열에서 다운로드 받으시길 권장하며 윈도우에서 파일 다운로드 시 wsl(리눅스용 윈도우 하위 시스템) 설치가 필요합니다.
※ 파일 병합 리눅스 명령어
find "폴더경로" -name "파일명.zip.part*" -print0 | sort -zt'.' -k2V | xargs -0 cat > "파일명.zip"
- 해당 명령어 실행 시, 실행 경로 위치에 병합 압축 파일이 생성됩니다.
- 병합된 파일 용량이 0일 경우, 제대로 병합이 되지 않은 상태이니 "폴더경로"가 제대로 입력되었는지 확인 부탁드립니다.
※ 데이터셋 소개 페이지에서 다운로드 버튼 클릭하여 승인이 필요합니다.
오프라인 데이터 이용 안내
본 데이터는 K-ICT 빅데이터센터에서도 이용하실 수 있습니다.
다양한 데이터(미개방 데이터 포함)를 분석할 수 있는 오프라인 분석공간을 제공하고 있습니다.
데이터 안심구역 이용절차 및 신청은 K-ICT빅데이터센터 홈페이지를 참고하시기 바랍니다.

국방데이터 개방 안내
본 데이터는 국방데이터로 군사 보안에 따라 AI허브에서 데이터를 제공하지 않으며,
군 담당자를 통한 별도의 사용 신청이 필요합니다.