-
데이터 변경이력
데이터 변경이력 버전 일자 변경내용 비고 1.1 2023-11-10 데이터 최종 개방 1.0 2023-06-28 데이터 개방(Beta Version) 소개
방송콘텐츠 상에서 한국인 대화체의 음성인식(STT) 기술 및 문맥을 이해하는 언어처리 기술 개발을 위한 인공지능 학습용 데이터로서 8개 카테고리, 대화체 음성인식, 문장별 의도 인공지능 학습용으로 정제된 7,000시간의 음성 데이터
구축목적
방송에서의 자연스러운 환경의 일상적인 대화체, 문장별 의도 분류, 카테고리 분류 서비스를 위한 고품질 방송콘텐츠 음성인식 데이터 확보로 화자를 더 잘 이해하는 지능화 혁신 서비스 기반 마련
-
메타데이터 구조표 데이터 영역 한국어 데이터 유형 텍스트 데이터 형식 tex 데이터 출처 공중파 방송국(TV, 라디오) 라벨링 유형 전사(음성) 라벨링 형식 JSON 데이터 활용 서비스 방송 카테고리 분류 서비스, 자막서비스, 챗봇, 콜센터 데이터 구축년도/
데이터 구축량2022년/7,002.74시간 -
데이터 분포
● 도메인 분포 : 교양, 문화, 시사, 예능, 예술, 지식교육, 토론 총 8종
● 남녀 성비 : 남, 여
● 연령대 : 10대, 20대, 30대, 40대, 50대, 60대 이상
● 화자 규모 : 2인, 3인, 4인, 5인, 6인, 7인, 8인, 9인, 10인, 11인 이상
● 전문용어 : 메타버스, 다다이즘, 디에스알 등
● 어절 수 : 5어절 단위
● 환경정보 : 환경의 종류(배경음악, 잡음, 배경음악/잡음)와 강도(적음, 보통, 많음) 구분
● 의도분류 : 선언, 단순 진술, 주장, 수용/긍정, 거절/부정, 답변 회피, 명령, 제안/요청, 단순 질문, 확인 질문, 약속, 경고/협박, 감사, 사과, 감탄, 칭찬, 비난/불평, 슬픔/괴로움, 기타 표출, 첫인사, 끝인사, 기타 인사, 부름 총 23종
● 요약문 어절 수 : 5어절 단위다양성(요건) :도메인 분포
도메인 분포 (단위: 발화시간) 카테고리 시간 비율 교양 1,050.09 15.00% 문화 771.07 11.01% 시사 770.35 11.00% 예능 1,050.16 15.00% 예술 490.02 7.00% 지식교육 770.59 11.00% 토론 1,050.22 15.00% 토크쇼 1,050.26 15.00% 합계 7,002.74 100% 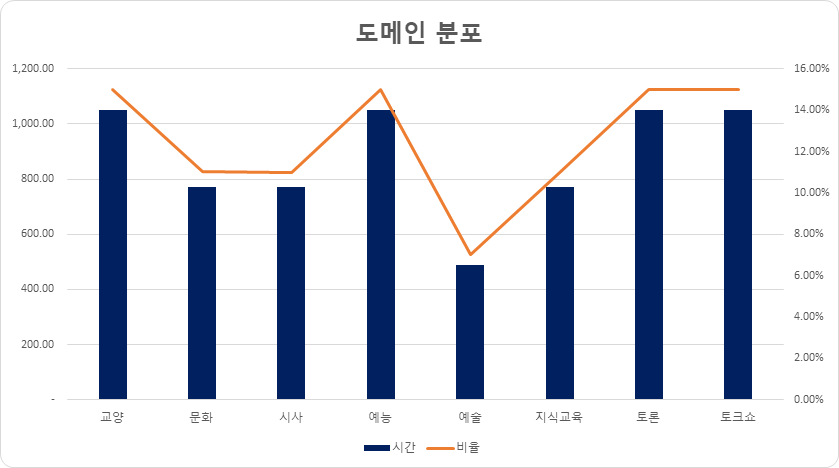
다양성(통계) :남여 성비
남녀 성비 (단위: 방송 건수) 성별 건수 비율 남 37,295 60.93% 여 23,914 39.07% 합계 61,209 100% 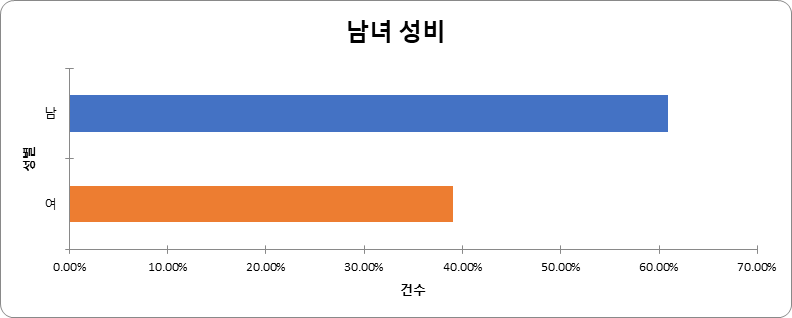
다양성(통계) :연령대
연령대 (단위: 방송 건수) 연령대 건수 비율 10대 4,266 6.97% 20대 6,274 10.25% 30대 15,606 25.50% 40대 21,466 35.07% 50대 10,701 17.48% 60대 이상 2,896 4.73% 합계 61,209 100% 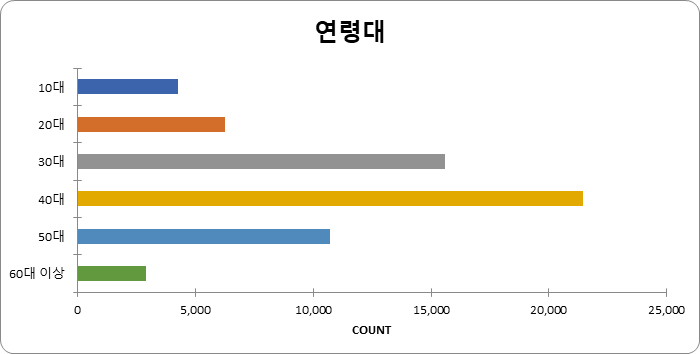
다양성(통계) :화자규모
화자 규모 (단위: 방송 건수) 화자 수 건수 비율 2 4,456 34.25% 3 2,769 21.29% 4 1,598 12.28% 5 1,263 9.71% 6 731 5.62% 7 458 3.52% 8 293 2.25% 9 221 1.70% 10 227 1.74% 11 이상 993 7.69% 합계 13,009 100% 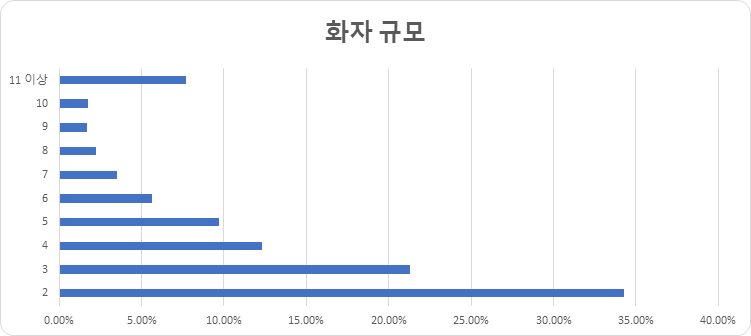
다양성(통계) :전문용어
전문용어 (단위: 방송 건수) 전문용어 건수 비율 메타버스 92 0.83% 인플레이션 56 0.51% 엔에프티 52 0.47% 엔에프티를 47 0.42% 테이퍼링 46 0.41% 디에스알 43 0.39% 에이아이 38 0.34% 엔에프티로 32 0.29% 해치 26 0.23% 다다이즘 23 0.21% 에이아이가 23 0.21% 인플레이션이 23 0.21% 이티에프가 22 0.20% 프로보노 22 0.20% 콘텍스트 21 0.19% 아이피티브이 20 0.18% 벨 칸토 19 0.17% 컷오프 19 0.17% 비트코인 18 0.16% 아리아 18 0.16% (기타 전문용어) 10,428 94.05% 합계 11,088 100% 다양성(통계) :어절수
어절 수 (단위: 건수) 어절 수 건수 비율 1~5 1,239,392 30.41% 6~10 1,016,373 24.94% 11~15 661,725 16.24% 16~20 422,850 10.38% 21~25 264,335 6.49% 26~30 168,712 4.14% 31~35 109,305 2.68% 36~40 71,420 1.75% 41~45 44,829 1.10% 46~50 28,141 0.69% 51~55 16,209 0.40% 56~60 10,510 0.26% 61~65 6,757 0.17% 66~70 4,229 0.10% 71~75 2,928 0.07% 76~80 2,037 0.05% 81~85 1,361 0.03% 86~90 954 0.02% 91~95 721 0.02% 96~100 543 0.01% 100이상 1,670 0.04% 합계 4,075,001 100% 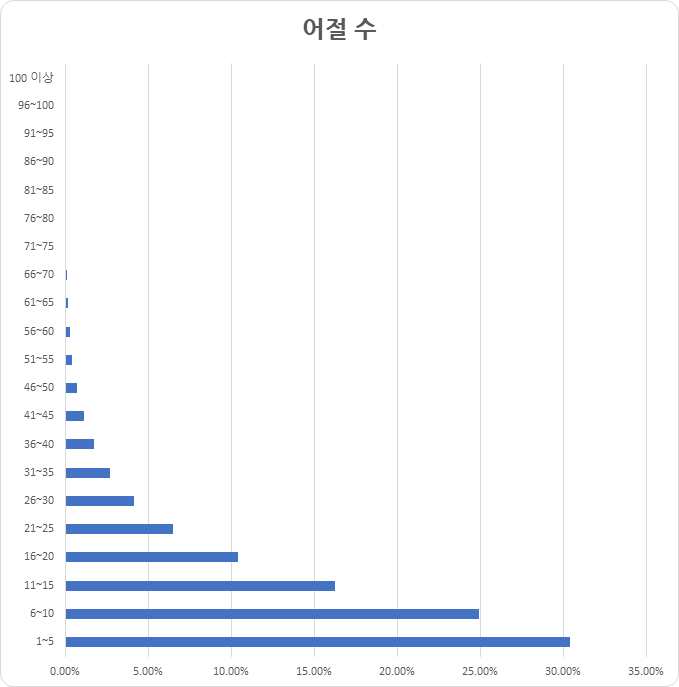
다양성(통계) : 환경정보
환경정보 (단위: 방송 건수) 환경 건수 비율 배경음악, 많음 196 1.51% 배경음악, 보통 600 4.61% 배경음악, 적음 4,029 30.97% 배경음악/잡음, 많음 835 6.42% 배경음악/잡음, 보통 2,238 17.20% 배경음악/잡음, 적음 3,080 23.68% 잡음, 많음 40 0.31% 잡음, 보통 275 2.11% 잡음, 적음 1,716 13.19% 합계 13,009 100% 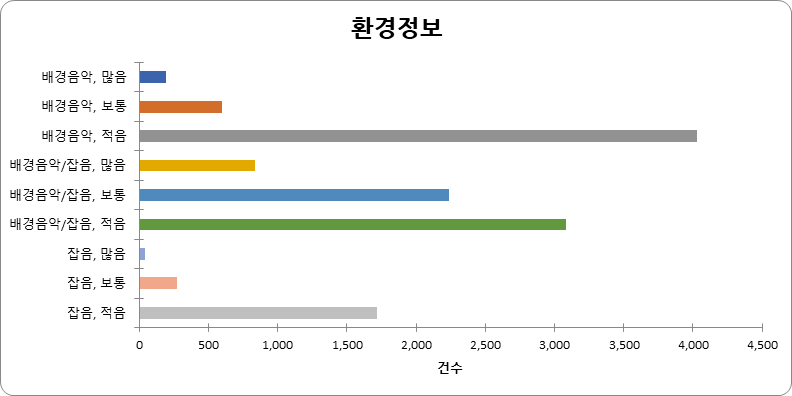
다양성(통계) :의도분류
의도분류 (단위: 발화 건수) 환경 건수 비율 경고/협박 462 0.01% 답변 회피 2,289 0.05% 약속 2,921 0.07% 슬픔/괴로움 3,989 0.09% 명령 4,132 0.10% 사과 4,348 0.10% 기타 인사 5,662 0.13% 부름 7,825 0.19% 끝인사 18,222 0.43% 칭찬 19,305 0.46% 감탄 20,034 0.48% 비난/불평 22,872 0.54% 거절/부정 24,872 0.59% 감사 43,116 1.02% 선언 45,547 1.08% 첫인사 46,857 1.11% 기타 표출 52,729 1.25% 제안/요청 121,932 2.90% 수용/긍정 186,126 4.42% 확인 질문 196,527 4.67% 주장 278,711 6.62% 단순 질문 298,110 7.08% 단순 진술 2,803,894 66.59% 합계 4,210,482 100% 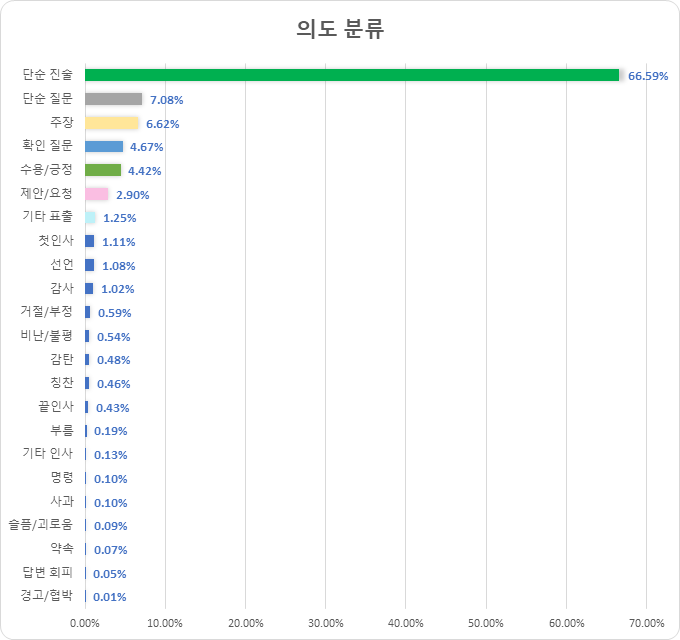
다양성(통계) :요약문 어절수
요약문 어절 수 (단위: 건수) 환경 건수 비율 1~10 1608 5.50% 11~20 4229 14.60% 21~30 10419 35.90% 31~40 6803 23.40% 41~50 2251 7.70% 51~60 886 3.10% 61~70 561 1.90% 71~80 398 1.40% 81~90 262 0.90% 91~100 205 0.70% 100이상 1,427 5% 합계 29,049 100% 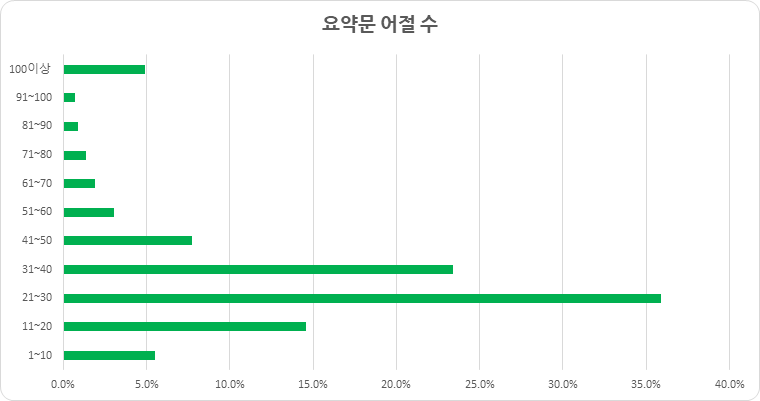
-
-
AI 모델 상세 설명서 다운로드
AI 모델 상세 설명서 다운로드 AI 모델 다운로드활용모델
모델학습
모델은 음성인식(conformer), 의도분류(ELECTRA), 요약문장(BART)을 사용하여 검증* 음성인식
학습 (90%) 검증 (5%) 시험 (5%) 개요 • Transformer Encoder에 CNN을 결합한 구조 • 학습 결과와 수작업 결과 대조 • 오디오 입력 → 전사 text 출력 → WER, CER 평가 • CTC를 사용하여 정답과 신호의 alignment를 일치시키는 과정으로 학습 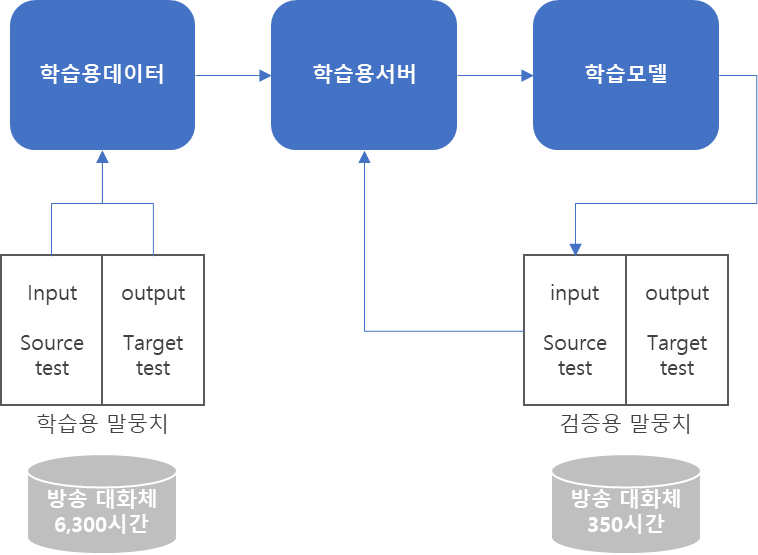
서비스 활용 예시
■ 자유주제, 자연스러운 대화체 음성인식 연구
■ 방송, 화상회의의 자막 생성에 활용* 의도분류
학습 (80%) 검증 (10%) 시험 (10%) 개요 • Transformer 기반 모델인 ELECTRA의 공개된 KoELECTRA 사용 • 학습 결과와 수작업 결과 대조 • text 입력 → 분류된 의도 출력 → Accuracy 평가 • 실제 입력의 일부를 의도된 토큰으로 바꾸어 원시자료와 변경을 분류 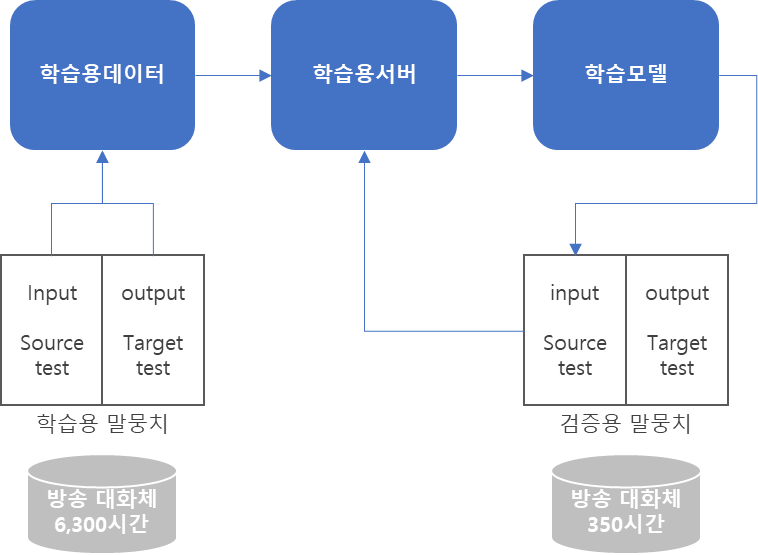
서비스 활용 예시
■ 발화자의 진짜 의도 파악이 필요한 음성인식 연구
■ 챗봇, 콜센터 상담에 활용* 요약생성
학습 (80%) 검증 (10%) 시험 (10%) 개요 • BART Sequence to Sequence 모델 사용 • 학습 결과와 수작업 결과 대조 • text 입력 → 요약문 생성 출력 → ROUGTE-1, 2, L 평가 • 텍스트에 임의 noise 추가 후 seq2seq 모델이 복원하는 방법 • 512토큰 이내 문장 사용 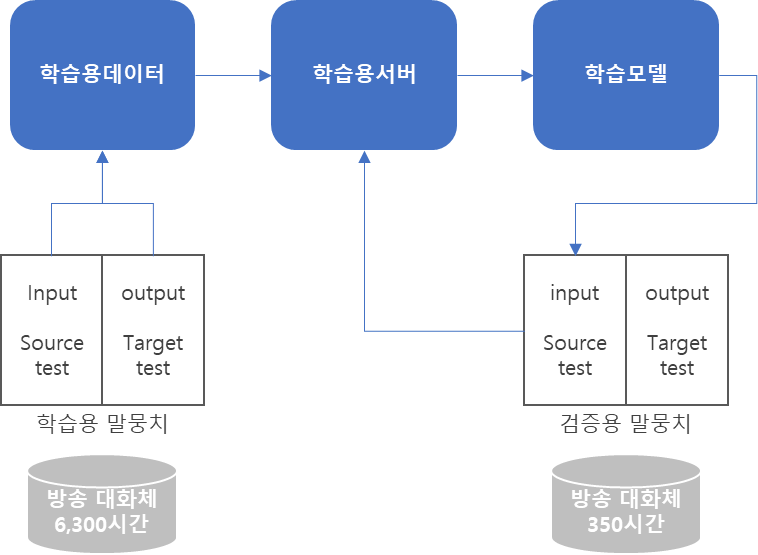
서비스 활용 예시
■ 발화자의 진짜 의도 파악이 필요한 음성인식 연구
■ 챗봇, 콜센터 상담에 활용 -
데이터 성능 점수
측정값 (%)기준값 (%)데이터 성능 지표
데이터 성능 지표 번호 측정항목 AI TASK 학습모델 지표명 기준값 점수 측정값 점수 1 의도분류 Text Classification ELECTRA Accuracy 85 % 86.51 % 2 음성인식 Speech Recognition Conformer CER 15 % 11.14 % 3 요약문장 Text Summary BART ROUGE-1 40 % 47.59 % 4 요약문장 Text Summary BART ROUGE-2 19 % 28.48 % 5 요약문장 Text Summary BART ROUGE-L 38 % 38.9 % 6 음성인식 Speech Recognition Conformer WER 30 % 25.14 %
※ 데이터 성능 지표가 여러 개일 경우 각 항목을 클릭하면 해당 지표의 값이 그래프에 표기됩니다.
※ AI모델 평가 지표에 따라 측정값의 범위, 판단 기준이 달라질 수 있습니다. (ex. 오류율의 경우, 낮을수록 좋은 성능을 내는 것으로 평가됩니다)
-
설명서 및 활용가이드 다운로드
데이터 설명서 다운로드 구축활용가이드 다운로드데이터 포맷
원문데이터 포맷 예시 제목 파일명 A220002 녹음일자 2021.10.08 원자료 유형 라디오 방송사 TBS 카테고리 교양 방송 제목 경제발전소 박연미입니다 화자 규모 5 원문 - {11.70049} 매일 아침 쏟아지는 경제뉴스 십분만 투자하면 충분히 따라잡을 수 있습니다. - {16.43513} 한국경제신문 홀길동 기자가 정리했습니다. - {19.16923} 안녕하세요. - {20.36159} 네 안녕하세요. - {21.80111} 네 고길동 청장이 십일월 둘째 주부터는 위드 코로나 시작할 수 있다 처음으로 얘기를 했군요. 라벨링후 **0001** - {11.70049} 매일 아침 쏟아지는 경제뉴스 (십 분만)/(10분만) 투자하면 충분히 따라잡을 수 있습니다. | [약속] - {16.43513} 한국경제신문 @이름1 기자가 정리했습니다. | [단순 진술] - {19.16923} 안녕하세요. | [첫인사] **0002** - {20.36159} 네 안녕하세요. | [첫인사] **0001** - {21.80111} 네 @이름2 청장이 (십일월)/(11월) 둘째 주부터는 위드 코로나 시작할 수 있다 처음으로 얘기를 했군요. | [단순 진술] JSON 형식 "id": "A220002.1.1.4", "speaker_id": "0001", "start": 11.700, "end": 16.435, "form": "매일 아침 쏟아지는 경제뉴스 (십 분만)/(10분만) 투자하면 충분히 따라잡을 수 있습니다.", "original_form": "매일 아침 쏟아지는 경제뉴스 십 분만 투자하면 충분히 따라잡을 수 있습니다.", "hangeulToEnglish": null, "hangeulToNumber": [ { "id": 1, "hangeul": "십 분만", "number": "10분만", "begin": 17, "end": 20 } ], "term": null, "intent": ["약속"], "endpoint": null, "summary": null }, { "id": "A220002.1.1.5", "speaker_id": "0001", "start": 16.435, "end": 19.169, "form": "한국경제신문 @이름1 기자가 정리했습니다.", "original_form": "한국경제신문 &name1& 기자가 정리했습니다.", "hangeulToEnglish": null, "hangeulToNumber": null, "term": null, "intent": ["단순 진술"], "endpoint": null, "summary": null }, 데이터 구성구분 No 속성명 속성 및 내용 필수 1 metadata.title AI 학습데이터 파일 제목 필수 2 metadata.creator 구축자 필수 3 metadata.distributor 배포자 필수 4 metadata.year 구축년도 필수 5 metadata.group 분류 필수 6 metadata.date 녹음일자 필수 7 metadata.media 원자료 유형 필수 8 metadata.publisher 방송사 필수 9 metadata.category 방송사 지정 카테고리 필수 10 metadata.program 방송 제목 필수 11 metadata.speaker_num 화자 규모 필수 12 metadata.annotation_level 분석 층위 필수 13 metadata.sampling 샘플링 방식 필수 14 speaker.id 화자 아이디 필수 15 speaker.sex 성별 필수 16 speaker.age 연령 선택 17 speaker.role 화자의 역할 필수 18 environment 잡음의 종류, 빈도 필수 19 utterance.id 발화 아이디 필수 20 utterance.speaker_id 화자 아이디 필수 21 utterance.start 발화 시작 시간 필수 22 utterance.end 발화 종료 시간 필수 23 utterance.form 전사, 라벨링 결과 필수 24 utterance.original_form 철자 전사 필수 25 utterance.hangeulToEnglish.id 영어 전사 번호 필수 26 utterance.hangeulToEnglish.hangeul 사전에 없는 외래어, 외국어의 한글 표기 필수 27 utterance.hangeulToEnglish.english 영문 전사 필수 28 utterance.hangeulToEnglish.begin 외래어, 외국어의 시작 위치 필수 29 utterance.hangeulToEnglish.end 외래어, 외국어의 끝 위치 필수 30 utterance.hangeulToNumber.id 숫자 전사(ITN) 번호 필수 31 utterance.hangeulToNumber.hangeul 한글 전사된 숫자/수사: 이십, 일 점 오… 필수 32 utterance.hangeulToNumber.number 숫자 전사 필수 33 utterance.hangeulToNumber.begin 한글 전사된 숫자/수사의 시작 위치 필수 34 utterance.hangeulToNumber.end 한글 전사된 숫자/수사의 끝 위치 필수 35 utterance.term.id 전문용어 번호 필수 36 utterance.term.hangeul 전문용어 필수 37 utterance.term.begin 전문용어의 시작 위치 필수 38 utterance.term.end 전문용어의 끝 위치 선택 39 utterance.intent 문장 의도 필수 40 utterance.endpoint.id 대화의 종단점 아이디 필수 41 utterance.endpoint.topic 프로그램별 대화 주제 키워드 필수 42 utterance.endpoint.turn 대화턴 필수 43 utterance.summary 대화 요약 어노테이션 포맷
구분 항목 타입 필수여부 설명 범위 1 metadata object Y 메타정보 1-1 title string Y AI 학습데이터 파일 제목 *category는 방송사 지정 카테고리 표에서 “코드”값 으로 유효값 지정 1-2 creator string Y 구축자 솔트룩스 1-3 distributor string Y 배포자 솔트룩스 1-4 year string Y 구축년도 2022 1-5 group string Y 분류 구어 > 공적 > 방송 1-6 date string Y 녹음일자 1-7 media string Y 원자료 유형 공중파방송,라디오 1-8 publisher string Y 방송사 KBS,KBSN, EBS,TBS,OBS 1-9 category string Y 방송사 지정 카테고리 *방송사 지정 카테고리 표에서 “카테고리” 값으로 유효값 지정 1-10 program string Y 방송 제목 1-11 speaker_num number Y 화자 규모 1,2,3,4,5... 1-12 annotation_level string Y 분석 층위 원시 1-13 sampling string Y 샘플링 방식 본문 전체 2 speaker array(object) Y 화자 2-1 id string Y 화자 아이디 2-2 sex string Y 성별 남,여 2-3 age string Y 연령 10대, 20대, 30대, 40대, 50대, 60대 이상 2-4 role string 화자의 역할 진행자,게스트,청중,“” 3 environment string Y 잡음의 종류, 빈도 배경음악, 많음 배경음악, 보통 배경음악, 적음 배경음악/잡음, 많음 배경음악/잡음, 보통 배경음악/잡음, 적음 잡음, 많음 잡음, 보통 잡음, 적음 4 utterance array(object) Y 발화 4-1 id string Y 발화 아이디 4-2 speaker_id string Y 화자 아이디 4-3 start number Y 발화 시작 시간 소수점 3자리까지 4-4 end number Y 발화 종료 시간 소수점 3자리까지 4-5 form string Y 전사, 라벨링 결과 4-6 original_form string Y 철자 전사 4-7 hangeulToEnglish array(object) 영어 전사 정보 4-7-1 id number Y 영어 전사 번호 4-7-2 hangeul string Y 사전에 없는 외래어, 외국어의 한글 표기 4-7-3 english string Y 영문 전사 4-7-4 begin number Y 외래어, 외국어의 시작 위치 4-7-5 end number Y 외래어, 외국어의 끝 위치 4-8 hangeulToNumber array(object) 한글 전사된 숫자/수사의 ITN 정보 4-8-1 id number Y 숫자 전사(ITN) 번호 4-8-2 hangeul string Y 한글 전사된 숫자/수사: 이십, 일 점 오… 4-8-3 number string Y 숫자 전사 4-8-4 begin number Y 한글 전사된 숫자/수사의 시작 위치 4-8-5 end number Y 한글 전사된 숫자/수사의 끝 위치 4-9 term array(object) 전문용어 4-9-1 id number Y 전문용어 번호 4-9-2 hangeul string Y 전문용어 4-9-3 begin number Y 전문용어의 시작 위치 4-9-4 end number Y 전문용어의 끝 위치 4-10 intent array
(string)문장 의도 *문장의도 유효값 4-11 endpoint array(object) 대화의 종단점 4-11-1 id number Y 대화의 종단점 아이디 4-11-2 topic string Y 프로그램별 대화 주제 키워드 *대화주제 키워드 유효값 4-11-3 turn number Y 대화턴 4-12 summary string Y 대화 요약 요약문 또는 “요약 없음” 실제 예시 { "metadata": { "title": "A220002", "creator": "솔트룩스", "distributor": "솔트룩스", "year": "2022", "group": "구어 > 공적 > 방송", "date": "20211008", "media": "라디오", "publisher": "TBS", "category": "교양", "program": "경제발전소 박연미입니다", "speaker_num": 5, "annotation_level": "원시", "sampling": "본문 전체" }, "speaker": [ { "id": "0001", "sex": "여", "age": "40대", "role": "진행자" }, { "id": "0002", "sex": "남", "age": "30대", "role": "게스트" }, { "id": "0003", "sex": "여", "age": "30대", "role": "게스트" }, { "id": "0004", "sex": "남", "age": "40대", "role": "게스트" }, { "id": "0005", "sex": "남", "age": "50대", "role": "게스트" } ], "environment": "배경음악, 적음", "utterance": [ { "id": "A220002.1.1.1", "speaker_id": "0001", "start": 0.000, "end": 2.914, "form": "오늘은 일단 부동산으로 시작을 해보죠.", "original_form": "오늘은 일단 부동산으로 시작을 해보죠.", "hangeulToEnglish": null, "hangeulToNumber": null, "term": null, "intent": ["선언"], "endpoint": null, "summary": null }, { "id": "A220002.1.1.2", "speaker_id": "0001", "start": 2.914, "end": 5.932, "form": "빠숑이라고 하면 더 잘 아실 것 같은데요.", "original_form": "빠숑이라고 하면 더 잘 아실 것 같은데요.", "hangeulToEnglish": null, "hangeulToNumber": null, "term": null, "intent": ["단순 진술"], "endpoint": null, "summary": null }, { "id": "A220002.1.1.3", "speaker_id": "0001", "start": 5.932, "end": 11.700, "form": "(()) 오랫동안 함께 해오신 빠숑님 모셔서 인사이트 한번 들어볼게요.", "original_form": "(()) 오랫동안 함께 해오신 빠숑님 모셔서 인사이트 한번 들어볼게요.", "hangeulToEnglish": null, "hangeulToNumber": null, "term": null, "intent": ["선언"], "endpoint": null, "summary": null }, -
데이터셋 구축 담당자
수행기관(주관) : ㈜솔트룩스
수행기관(주관) 책임자명 전화번호 대표이메일 담당업무 김영혁 02-2193-1682 alex.kim@saltlux.com 실무책임 수행기관(참여)
수행기관(참여) 기관명 담당업무 경북대학교 산학협력단 설계, 지침, 자문, 품질(비식별화, 혐오 및 차별 발언) ㈜디그랩 정제 ㈜소리자바 가공 ㈜비투엔 전담 품질검수 데이터 관련 문의처
데이터 관련 문의처 담당자명 전화번호 이메일 김영혁 02-2193-1682 alex.kim@saltlux.com
-
인터넷과 물리적으로 분리된 온라인·오프라인 공간으로 의료 데이터를 포함하여 보안 조치가 요구되는 데이터를 다운로드 없이 접근하고 분석 가능
* 온라인 안심존 : 보안이 보장된 온라인 네트워크를 통해 집, 연구실, 사무실 등 어디서나 접속하여 데이터에 접근하고 분석
* 오프라인 안심존 : 추가적인 보안이 필요한 데이터를 대상으로 지정된 물리적 공간에서만 접속하여 데이터에 접근하고 분석 -
- AI 허브 접속
신청자 - 안심존
사용신청신청자신청서류 제출* - 심사구축기관
- 승인구축기관
- 데이터 분석 활용신청자
- 분석모델반출신청자
- AI 허브 접속
-
1. 기관생명윤리위원회(IRB) 심의 결과 통지서 [IRB 알아보기]
2. 기관생명윤리위원회(IRB) 승인된 연구계획서
3. 신청자 소속 증빙 서류 (재직증명서, 재학증명서, 근로계약서 등 택1)
4. 안심존 이용 신청서 [다운로드]
5. 보안서약서 [다운로드]
※ 상기 신청서 및 첨부 서류를 완비한 후 신청을 진행하셔야 정상적으로 절차가 이루어집니다. -
신청 및 이용관련 문의는 safezone1@aihub.kr 또는 02-525-7708, 7709로 문의
데이터셋 다운로드 승인이 완료 된 후 API 다운로드 서비스를 이용하실 수 있습니다.
API 다운로드 파일은 분할 압축되어 다운로드 됩니다. 분할 압축 해제를 위해서는 분할 압축 파일들의 병합이 필요하며 리눅스 명령어 사용이 필요합니다.
리눅스 OS 계열에서 다운로드 받으시길 권장하며 윈도우에서 파일 다운로드 시 wsl(리눅스용 윈도우 하위 시스템) 설치가 필요합니다.
※ 파일 병합 리눅스 명령어
find "폴더경로" -name "파일명.zip.part*" -print0 | sort -zt'.' -k2V | xargs -0 cat > "파일명.zip"
- 해당 명령어 실행 시, 실행 경로 위치에 병합 압축 파일이 생성됩니다.
- 병합된 파일 용량이 0일 경우, 제대로 병합이 되지 않은 상태이니 "폴더경로"가 제대로 입력되었는지 확인 부탁드립니다.
※ 데이터셋 소개 페이지에서 다운로드 버튼 클릭하여 승인이 필요합니다.