※온라인 안심존 : 보안이 보장된 온라인 네트워크를 통해 집, 연구실, 사무실 등 어디서나 접속하여 데이터에 접근하고 분석
NEW 뇌질환 융합데이터
- 분야헬스케어
- 구분 안심존(온라인)
- 유형 텍스트 , 이미지 , 비디오
-
데이터 변경이력
데이터 변경이력 버전 일자 변경내용 비고 1.1 2023-11-30 데이터 최종 개방 1.0 2023-05-04 데이터 개방(Beta Version) 데이터 히스토리
데이터 히스토리 일자 변경내용 비고 2024-01-29 데이터설명서, 구축업체정보 수정 담당자 정보 수정 2024-01-26 산출물 전체 공개 2023-07-28 담당자 ,연락처 변경 소개
뇌질환 융합데이터를 이용하여 정상, 경도인지장애, 치매 환자 예측 AI 모델 제시
구축목적
임상 및 인지평가의 완전한 데이터셋(complete data set)을 근거로 한 경도인지장애와 치매 진단을 AI로 학습을 시켜서, 불완전한 데이터셋(incomplete data set)을 가진 환자의 진단을 AI 알고리듬을 통해 추정하는 진단법을 수립하는 것이 궁극적인 목적임.
-
메타데이터 구조표 데이터 영역 헬스케어 데이터 유형 텍스트 , 이미지 , 비디오 데이터 형식 JPG, CSV, MP4 데이터 출처 자체 수집 라벨링 유형 바운딩 박스, 키포인트, 내용요약 라벨링 형식 JSON 데이터 활용 서비스 의료서비스 데이터 구축년도/
데이터 구축량2022년/939 Case -
데이터 구축 규모
구분 최종인원/ 뇌파 CDT 데이터 메타 데이터 목표인원(명) 데이터 정상 333/300 333 333 333 경도인지장애 400/400 400 400 400 치매 206/200 206 206 206 합계 939/900 939 939 939 데이터 분포
다양성 연령대별 분포 구성비 구성비 중첩률 50% 치매환자 비율은 50대 이상부터 주로 발생하므로, 50대 이상을 모집하여 환자의 경우 60, 70대가 많음. 최대한 연령별 균등분포를 얻을 예정임 (요건) 중첩률 목표 구성비 50 대 10.60% 60 대 24.60% 70 대 39.60% 80 대 24.10% 남녀 성비 구성비 구성비 중첩률 50% 여성의 병원 방문과 인지장애 유병율이 높지만, 성별은 가능한 5:5 비율로 가깝게 구축할 예정임 중첩률 목표 구성비 남성 31.10% 여성 68.90% 질환별 분포 구성비 구성비 중첩률 50% 질환명 분포를 다양성(통계) 목표치에 따라 최대한 가깝게 구축할 예정임 중첩률 목표 구성비 정상인 35.50% 경도인지장애 42.60% 치매 21.90% -
-
AI 모델 상세 설명서 다운로드
AI 모델 상세 설명서 다운로드 AI 모델 다운로드모델 학습 프로세스
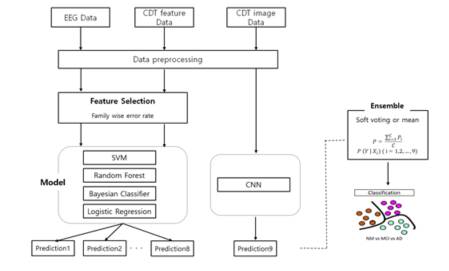
qEEG 데이터와 CDT feature(score) 데이터, CDT image 데이터의 퇴행성 뇌질환 분류모델 적용을 위한 학습 프레임워크
본 사업의 AI모델 적용시에는 정상 300명, 경도인지장애 400명, 치매 200명의 데이터를 사용하였으며 Train Set : Validation Set : Test Set 비율은 80%, 10%, 10%로 분석진행데이터 전처리

데이터의 merging과 matching, 데이터 scaling의 전처리 과정을 거쳐, 각 변수의 독립적인 특징을 평가하기 위해 Family Wise Error Rate(FWER)이 보정된 p-values에서 p-values cut off (유의수준)에 따라 유의한 변수만 가져오기 위한 mask를 생성함
p-values cut off을 유의수준으로 수행한 다중 검정으로 증가한 FWER 위하여 adjust method로 p-value 보정
CDT score의 경우 순위 기반의 범주형 데이터이므로 scaling 과정은 생략한다.
CDT image의 경우 시계 이미지의 크기에 맞게 bounding box 구현 후, 시계 그림만 cropping, resizing작업을 진행하여 모델에 적용하였다.
*resize image shape = (128,128)학습모델
단일 모달리티를 위한 머신러닝 모델로는 Support Vector Machine(Linear, Radial Basis Function), Logistic Regression, Random Forest를 사용함.
CDT image 데이터 분석을 위한 Convolution Neural Network 모델을 사용하였고, 컨볼루션 신경망 모델 주요 학습 파라미터는 다음과 같이 사용함.
*optimizer = Adam, Loss = categorical cross entropy, Total Params = 741,827
멀티모달 기반의 앙상블기법에 soft voting 방법을 사용하여 F1score로 평가함 -
데이터 성능 점수
측정값 (%)기준값 (%)데이터 성능 지표
데이터 성능 지표 번호 측정항목 AI TASK 학습모델 지표명 기준값 점수 측정값 점수 1 정상/경도인지장애/치매 분류 성능 Image Classification Support Vector Machine, Random Forest, Linear SVC, Logistic Regression, CNN F1-Score 0.8 점 0.8111 점
※ 데이터 성능 지표가 여러 개일 경우 각 항목을 클릭하면 해당 지표의 값이 그래프에 표기됩니다.
※ AI모델 평가 지표에 따라 측정값의 범위, 판단 기준이 달라질 수 있습니다. (ex. 오류율의 경우, 낮을수록 좋은 성능을 내는 것으로 평가됩니다)
-
설명서 및 활용가이드 다운로드
데이터 설명서 다운로드 구축활용가이드 다운로드 데이터 포멧
원시 데이터 종류 CDT 데이터 뇌파 데이터 메타 데이터 원시 데이터 포맷 jpg edf txt 데이터 구성
- 기관코드기관명 파일명 구조 동아대학교 병원 DMC 부산대학교 병원 PMC 동아대학교 산학협력단 DAU ㈜ 아이메디신 IMS ㈜ 에스씨티 SCT - 데이터 코드(질병 구분별)
데이터 종류 데이터 코드 NC 정상 MCI 경도인지장애 AD 치매 어노테이션 포맷
(1) CDT 데이터 (임상정보)구분 속성명 타입 필수여부 설명 범위 비고 1 id string Y 식별자(파일명) 2 file_format string Y 스코어 파일확장자 3 organ string Y 측정기관 DAU, DMC,SCT, PMC, CAU, IMS 4 sequence string Y 순번 5 length number 측정 시간 (초) 6 data_captured string 생성일자 7 time string 수집 시간 8 sex strimg 성별 M,W 9 age number 나이 10 height number 키 11 weight number 몸무게 12 diagnostic string 진단정보 0G0, 0G1, 0G2 13 drug_use string 약물복용여부 M1 ~ M9 14 score1 number Y CDT질적 total score 15 score2 number Y CDT양적 total score (2) CDT 데이터 (시계판 완결성)
구분 속성명 타입 필수여부 설명 범위 비고 1 id string Y 식별자(파일명) 2 file_format string Y 스코어 파일확장자 3 organ string Y 측정기관 DAU, DMC,SCT, PMC, CAU, IMS 4 sequence string Y 순번 5 clock_x number 시계판 X 위치 6 clock_y number 시계판 Y 위치 7 width number 시계판 넓이 8 height number 시계판 높이 9 intersec_rate number 시계판 정사각형비율 10 score number Y 시계판 완결성 (3) CDT 데이터 (숫자의 표기여부 및 순서)
구분 속성명 타입 필수여부 설명 범위 비고 1 id string Y 식별자(파일명) 2 file_format string Y 스코어 파일확장자 3 organ string Y 측정기관 4 sequence string Y 순번 5 num_direct string 시계숫자 방향 6 num_1_x number 1시의 X 위치 7 num_1_y number 1시의 Y 위치 8 num_1_loc number 1시 위치의 시계값 9 num_1_dup string 1시의 위치정확도 10 num_2_x number 2시의 X 위치 11 num_2_y number 2시의 Y 위치 12 num_2_loc number 2시 위치의 시계값 13 num_2_dup string 2시의 위치정확도 14 num_3_x number 3시의 X 위치 15 num_3_y number 3시의 Y 위치 16 num_3_loc number 3시 위치의 시계값 17 num_3_dup string 3시의 위치정확도 18 num_4_x number 4시의 X 위치 19 num_4_y number 4시의 Y 위치 20 num_4_loc number 4시 위치의 시계값 21 num_4_dup string 4시의 위치정확도 22 num_5_x number 5시의 X 위치 23 num_5_y number 5시의 Y 위치 24 num_5_loc number 5시 위치의 시계값 25 num_5_dup string 5시의 위치정확도 26 num_6_x number 6시의 X 위치 27 num_6_y number 6시의 Y 위치 28 num_6_loc number 6시 위치의 시계값 29 num_6_dup string 6시의 위치정확도 30 num_7_x number 7시의 X 위치 31 num_7_y number 7시의 Y 위치 32 num_7_loc number 7시 위치의 시계값 33 num_7_dup string 7시의 위치정확도 34 num_8_x number 8시의 X 위치 35 num_8_y number 8시의 Y 위치 36 num_8_loc number 8시 위치의 시계값 37 num_8_dup string 8시의 위치정확도 38 num_9_x number 9시의 X 위치 39 num_9_y number 9시의 Y 위치 40 num_9_loc number 9시 위치의 시계값 41 num_9_dup string 9시의 위치정확도 42 num_10_x number 10시의 X 위치 43 num_10_y number 10시의 Y 위치 44 num_10_loc number 10시 위치의 시계값 45 num_10_dup string 10시의 위치정확도 46 num_11_x number 11시의 X 위치 47 num_11_y number 11시의 Y 위치 48 num_11_loc number 11시 위치의 시계값 49 num_11_dup string 11시의 위치정확도 50 num_12_x number 12시의 X 위치 51 num_12_y number 12시의 Y 위치 52 num_12_loc number 12시 위치의 시계값 53 num_12_dup string 12시의 위치정확도 54 score number Y 숫자표기및순서 (4) CDT 데이터 (바늘의 표기 여부 및 배치)
구분 속성명 타입 필수여부 설명 범위 비고 1 id string Y 식별자(파일명) 2 file_format string Y 스코어 파일확장자 3 organ string Y 측정기관 DAU, DMC,SCT, PMC, CAU, IMS 4 sequence string Y 순번 5 hour_exist string 시침의 존재여부 6 hour_x number 시침의 X 위치 7 hour_y number 시침의 Y 위치 8 hour_width number 시침의 넓이 9 hour_height number 시침의 높이 10 hour_length number 시침의 길이 11 hour_angle number 시침의 각도 12 hour_dist number 시침의 중심점의 거리 13 min_exist string 분침의 존재여부 14 min_x number 시침의 X 위치 15 min_y number 시침의 Y 위치 16 mon_width number 시침의 넓이 17 min_height number 시침의 높이 18 min_length number 시침의 길이 19 min_angle number 분침의 각도 20 min_dist number 분침의 중심점의 거리 21 score number 숫자표기및순서 (5) CDT 데이터 (시계의 크기)
구분 속성명 타입 필수여부 설명 범위 비고 1 id string Y 식별자(파일명) 2 file_format string Y 스코어 파일확장자 3 organ string Y 측정기관 DAU, DMC,SCT, PMC, CAU, IMS 4 sequence string Y 순번 5 width number 시계 넓이 6 height number 시계 높이 7 clock_size number 시계크기 8 score number Y 시계 크기 (6) CDT 데이터 (그리기 어려움)
구분 속성명 타입 필수여부 설명 범위 비고 1 id string Y 식별자(파일명) 2 file_format string Y 스코어 파일확장자 3 organ string Y 측정기관 DAU, DMC,SCT, PMC, CAU, IMS 4 sequence string Y 순번 5 clock_accuracy number 시계판의 정확도 6 hands_accuracy number 시계바늘의 정확도 7 number_accuracy number 숫자의 정확도 8 score number Y 그리기어려움 (7) CDT 데이터 (자극속박반응)
구분 속성명 타입 필수여부 설명 범위 비고 1 id string Y 식별자(파일명) 2 file_format string Y 스코어 파일확장자 3 organ string Y 측정기관 DAU, DMC,SCT, PMC, CAU, IMS 4 sequence string Y 순번 5 hour_angle number 시침의 각도 6 hour_number number 시침의 가르키는 숫자 7 hour_draw string 시간을 숫자로 표기여부 8 min_angle number 분침의 각도 9 min_number number 분침의 가르키는 숫자 10 min_draw number 분을 숫자로 표기여부 11 score number Y 자극속박반응 (8) CDT 데이터 (개념적 결함)
구분 속성명 타입 필수여부 설명 범위 비고 1 id string Y 식별자(파일명) 2 file_format string Y 스코어 파일확장자 3 organ string Y 측정기관 DAU, DMC,SCT, PMC, CAU, IMS 4 sequence string Y 순번 5 clock_accuracy number 시계판에 정확도 6 number_accuracy number 숫자의 정확도 7 hands_accuracy number 시계바늘의 정확도 8 score number Y 개념적 결함 (9) CDT 데이터 (공간과계획 결함)
구분 속성명 타입 필수여부 설명 범위 비고 1 id string Y 식별자(파일명) 2 file_format string Y 스코어 파일확장자 3 organ string Y 측정기관 DAU, DMC,SCT, PMC, CAU, IMS 4 sequence string Y 순번 5 ignore_left number 숫자의 좌측무시 6 form_error number 특정형태오류 7 pattern_error number 패턴오류 8 number_outside number 시계판 밖에 숫자 9 number_reverse number 반시계 방향으로 숫자기입 10 score number Y 공간과계획결함 (10) CDT 데이터 (보속)
구분 속성명 타입 필수여부 설명 범위 비고 1 id string Y 식별자(파일명) 2 file_format string Y 스코어 파일확장자 3 organ string Y 측정기관 DAU, DMC,SCT, PMC, CAU, IMS 4 sequence string Y 순번 5 hands_count number 바늘의 숫자 6 num_1_count number 숫자1의 개수 7 num_2_count number 숫자2의 개수 8 num_3_count number 숫자3의 개수 9 num_4_count number 숫자4의 개수 10 num_5_count number 숫자5의 개수 11 num_6_count number 숫자6의 개수 12 num_7_count number 숫자7의 개수 13 num_8_count number 숫자8의 개수 14 num_9_count number 숫자9의 개수 15 num_10_count number 숫자10의 개수 16 num_11_count number 숫자11의 개수 17 num_12_count number 숫자12의 개수 18 score number Y 보속 -
데이터셋 구축 담당자
수행기관(주관) : 가천대학교 산학협력단
수행기관(주관) 책임자명 전화번호 대표이메일 담당업무 데이터 총괄 수행기관(참여)
수행기관(참여) 기관명 담당업무 ㈜아이메디신 뇌질환 융합데이터 총괄 및 데이터 셋 구축 전 과정 동아대학교 병원 데이터 수집, 검수 부산대학교 병원 데이터 수집, 검수 ㈜에스엔씨 데이터 정제, 가공 동아대학교 산학협력단 데이터 수집, 검수 ㈜에스씨티 데이터 수집 ㈜어니컴 데이터 검수 데이터 관련 문의처
데이터 관련 문의처 담당자명 전화번호 이메일 이지원 02-747-7422 jwlee@imedisync.com
-
인터넷과 물리적으로 분리된 온라인·오프라인 공간으로 의료 데이터를 포함하여 보안 조치가 요구되는 데이터를 다운로드 없이 접근하고 분석 가능
* 온라인 안심존 : 보안이 보장된 온라인 네트워크를 통해 집, 연구실, 사무실 등 어디서나 접속하여 데이터에 접근하고 분석
* 오프라인 안심존 : 추가적인 보안이 필요한 데이터를 대상으로 지정된 물리적 공간에서만 접속하여 데이터에 접근하고 분석 -
- AI 허브 접속
신청자 - 안심존
사용신청신청자신청서류 제출* - 심사구축기관
- 승인구축기관
- 데이터 분석 활용신청자
- 분석모델반출신청자
- AI 허브 접속
-
1. 기관생명윤리위원회(IRB) 심의 결과 통지서 [IRB 알아보기]
2. 기관생명윤리위원회(IRB) 승인된 연구계획서
3. 신청자 소속 증빙 서류 (재직증명서, 재학증명서, 근로계약서 등 택1)
4. 안심존 이용 신청서 [다운로드]
5. 보안서약서 [다운로드]
※ 상기 신청서 및 첨부 서류를 완비한 후 신청을 진행하셔야 정상적으로 절차가 이루어집니다. -
신청 및 이용관련 문의는 safezone1@aihub.kr 또는 02-525-7708, 7709로 문의
데이터셋 다운로드 승인이 완료 된 후 API 다운로드 서비스를 이용하실 수 있습니다.
API 다운로드 파일은 분할 압축되어 다운로드 됩니다. 분할 압축 해제를 위해서는 분할 압축 파일들의 병합이 필요하며 리눅스 명령어 사용이 필요합니다.
리눅스 OS 계열에서 다운로드 받으시길 권장하며 윈도우에서 파일 다운로드 시 wsl(리눅스용 윈도우 하위 시스템) 설치가 필요합니다.
※ 파일 병합 리눅스 명령어
find "폴더경로" -name "파일명.zip.part*" -print0 | sort -zt'.' -k2V | xargs -0 cat > "파일명.zip"
- 해당 명령어 실행 시, 실행 경로 위치에 병합 압축 파일이 생성됩니다.
- 병합된 파일 용량이 0일 경우, 제대로 병합이 되지 않은 상태이니 "폴더경로"가 제대로 입력되었는지 확인 부탁드립니다.
※ 데이터셋 소개 페이지에서 다운로드 버튼 클릭하여 승인이 필요합니다.