※ 23년 신규 개방되는 데이터로 샘플데이터는 추후 업로드 예정입니다.
-
데이터 변경이력
데이터 변경이력 버전 일자 변경내용 비고 1.1 2023-11-10 데이터 최종 개방 1.0 2023-06-28 데이터 개방(Beta Version) 데이터 히스토리
데이터 히스토리 일자 변경내용 비고 2023-11-27 산출물 전체 공개 소개
ㅇ인공지능 요약 서비스와 오탈자 교정 서비스 위한 전문분야 심층인터뷰 음성인식 데이터 확보 ㅇ데이터 기반 지능화 혁신서비스 확산, AI서비스 창출을 위한 유효성, 활용성 검증된 학습 데이터 모델 구축 ㅇ전문분야 심층인터뷰 데이터, 15개 이상 분류의 2,000시간 구축
구축목적
전문분야 심층인터뷰 데이터를 바탕으로 전문용어의 자동스크립트, 인터뷰 내용의 요약문장 서비스, 포커스 그룹 인터뷰(FGL)의 감정 분석 서비스 확장 ㅇ데이터 셋 구축 및 활용 서비스 공개를 통한 좌담회 또는 청문회 해설 플랫폼, 인공지능 스크립트 플랫폼 등 관련 분야 산업 발전
-
메타데이터 구조표 데이터 영역 한국어 데이터 유형 오디오 데이터 형식 wav 데이터 출처 직접 녹음, 유튜브, 방송사 라벨링 유형 전사, 질의-응답 및 요약 (음성) 라벨링 형식 json 데이터 활용 서비스 자동 스크립트 작성 및 요약 서비스 데이터 구축년도/
데이터 구축량2022년/2,080시간 -
데이터 구축 규모
데이터 통계 데이터 구축 규모 2,080시간 데이터 분포 역사/고고학(7.27%), 언어/문학(5.05%), 경제/경영(8.07%), 사회/인류/복지/여성(7.08%), 교육(9.81%), 자연과학(9.46%), 생물학(4.85%), 환경(9%), 정보/통신(4.26%), 컴퓨터학(4.72%), 예방의학/직업환경의학(6.42%), 보건의료기타(6.40%), 문화/예술/체육(9.51%), 농림수산식품(2.6%), 물리학(5.5%)
데이터 분포▪ 도메인 분포 : 역사/고고학, 언어/문학, 경제/경영, 사회/인류/복지/여성, 교육, 자연과학, 생물학, 환경, 정보/통신, 컴퓨터학, 예방의학/직업환경의학, 보건의료기타, 문화/예술/체육, 농림수산식품, 물리학 총 15종
▪ 화자 규모 : 최소 2인 이상
▪ 남녀 성비 : 남, 여
▪ 연령대 : 10대, 20대, 30대, 40대, 50대, 60대 이상
▪ 방영 시기 : 2018, 2019, 2020, 2021, 2022
▪ 방송 매체 분포 : 인터뷰, 유튜브, 방송
▪ 어절 수 : 5어절 단위
▪ 요약문 어절 수 : 5어절 단위▪다양성(요건) : 도메인 분포
도메인 분포 (단위: 시간) 카테고리 시간 비율 역사/고고학 151.32 7.27% 언어/문학 105.07 5.05% 경제/경영 167.93 8.07% 사회/인류/복지/여성 147.29 7.08% 교육 204.23 9.81% 자연과학 196.83 9.46% 생물학 100.93 4.85% 환경 187.33 9% 정보/통신 88.65 4.26% 컴퓨터학 98.17 4.72% 예방의학/직업환경의학 133.54 6.42% 보건의료기타 133.25 6.40% 문화/예술/체육 198 9.51% 농림수산식품 54.1 2.60% 물리학 114.48 5.50% 합계 2,081.18 100% 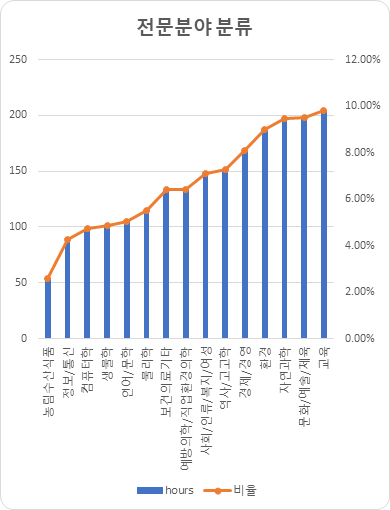
화자 규모 (단위: 건수) 화자 수 건수 비율 2 1397 46.94% 3~5 1026 34.47% 6~8 265 8.90% 9~11 172 5.78% 12 이상 116 3.88% 합계 2976 100% 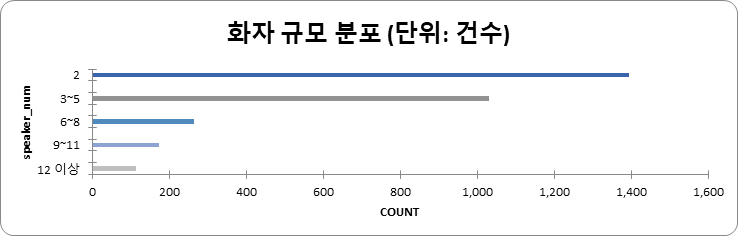
남녀 성비 (단위: 건수) 성별 건수 비율 남 7828 66.46% 여 3950 33.54% 합계 11778 100% 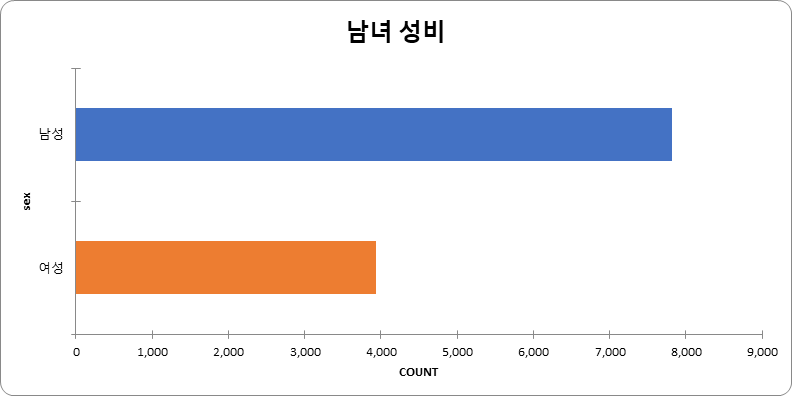
연령대 (단위: 건수) 연령대 건수 비율 10대 352 2.99% 20대 453 3.85% 30대 2806 23.82% 40대 3484 29.58% 50대 3158 26.81% 60대 이상 1525 12.95% 합계 11,778 100% 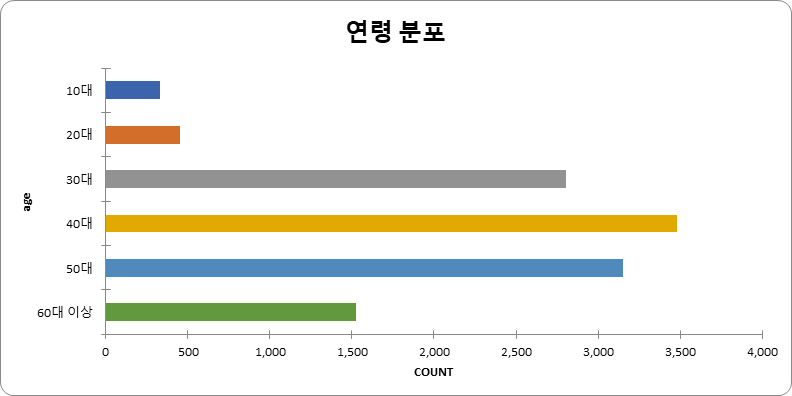
방영 시기 (단위: 건수) 방영 시기 건수 비율 2018 157 5.28% 2019 314 10.55% 2020 476 15.99% 2021 629 21.14% 2022 1,400 47.04% 합계 2,976 100% 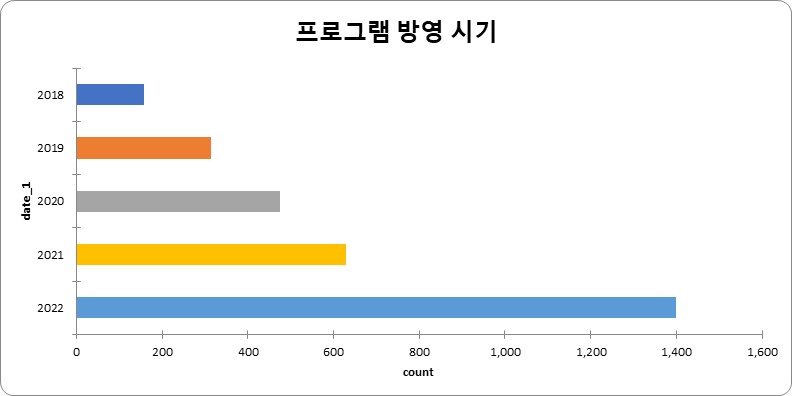
방송 매체 (단위: 건수) 매체 건수 비율 인터뷰 714 23.99% 유튜브 754 25.34% 방송 1,508 50.67% 합계 2,976 100% 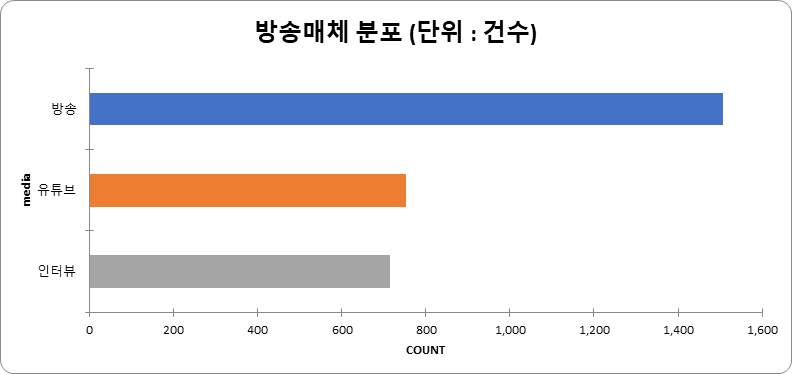
어절 수 (단위: 건수) 어절 수 건수 비율 1~5 291,298 29.46% 6~10 197,345 19.96% 11~15 152,514 15.43% 16~20 107,891 10.91% 21~25 72,972 7.38% 26~30 49,105 4.97% 31~35 34,310 3.47% 36~40 24,841 2.50% 41~45 18,495 1.87% 46~50 13,787 1.39% 51~55 9,520 0.96% 56~60 6,277 0.64% 61~65 3,740 0.37% 66~70 2,170 0.21% 71~75 1,300 0.13% 76~80 842 0.09% 81~85 525 0.05% 86~90 392 0.05% 90 이상 1,377 0.05% 합계 988,701 100% 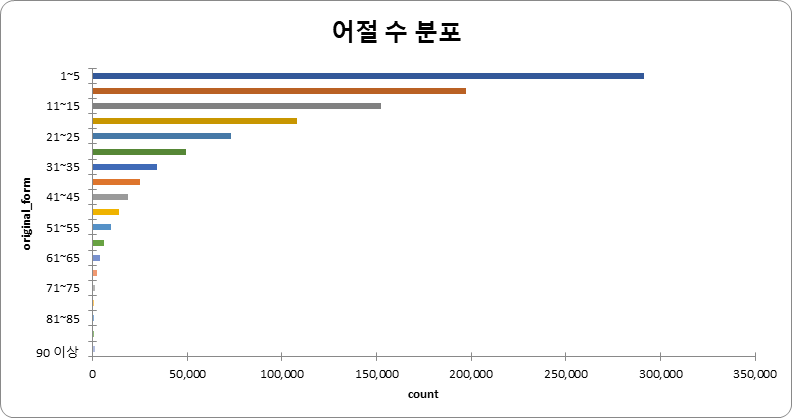
요약문 어절 수 (단위: 건수) 어절 수 건수 비율 10~15 17 0.34% 16~20 648 12.85% 21~25 893 17.70% 26~30 743 14.72% 31~35 553 10.96% 36~40 423 8.39% 41~45 312 6.18% 46~50 255 5.05% 51~55 210 4.15% 56~60 170 3.36% 61~65 121 2.40% 66~70 114 2.27% 71~75 78 1.56% 76~80 61 1.22% 81~85 66 1.32% 86~90 54 1.08% 91~95 38 0.76% 96~100 48 0.96% 100 이상 242 4.84% 합계 5,046 100% 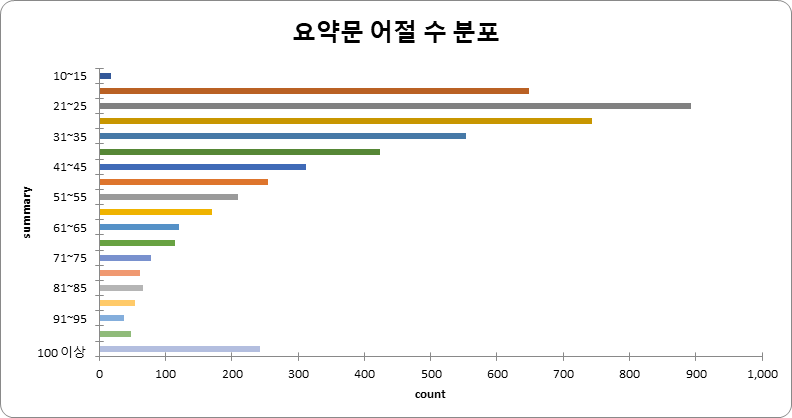
-
-
AI 모델 상세 설명서 다운로드
AI 모델 상세 설명서 다운로드 AI 모델 다운로드모델학습
본 사업에서 구축한 데이터가 음성 인식과 오탈자 교정, 요약 생성 모델에 활용할 수 있기에 각 모델별 적절한 학습, 검증, 시험 데이터셋을 준비하는 것을 제안함모델 분류 구분 학습(Training) 검증(Validation) 시험(Test) 음성 인식 개요 - 기학습된 Conformer 모델에 증분학습 - 학습 도중 모델 성과 평가 및 비교 - 모델 학습 완료 후 - GPU 학습 사용 - CER, WER 점수 - 모델 테스트 데이터 비율 90% 5% 5% 오탈자 교정 개요 - 기학습된 BART 모델에 증분학습 - 학습 도중 모델 성과 평가 및 비교 - 모델 학습 완료 후 - GPU 학습 사용 - BULE, F0.5score 점수 - 모델 테스트 데이터 비율 80% 10% 10% 요약 생성 개요 - 기학습된 BART 모델에 증분학습 - 학습 도중 모델 성과 평가 및 비교 - 모델 학습 완료 후 - GPU 학습 사용 - ROUGE 점수 - 모델 테스트 데이터 비율 80% 10% 10% 서비스 활용 시나리오
구축한 모델은 영상 자막이나 회의 요약 및 번역 등에 활용할 수 있으며, 코퍼스 연구에 활용할 수 있음
● 영상 자막 서비스 활용
● 회의 요약 및 번역 서비스 활용
● 코퍼스 연구 활용
▷ 음성 연구의 경우 음성 인식 및 합성 등에 활용할 수 있음
▷ 언어 연구의 경우 오탈자 탐지 및 교정, 요약문 생성 등 자연어 처리, 언어 지능 연구에 활용할 수 있음
-
데이터 성능 점수
측정값 (%)기준값 (%)데이터 성능 지표
데이터 성능 지표 번호 측정항목 AI TASK 학습모델 지표명 기준값 점수 측정값 점수 1 음성인식 Speech Recognition Conformer CER 20 % 16.09 % 2 오탈자 교정 Speech Synthesis BART F0.5-Score 0.77 점 0.96 점 3 오탈자 교정 Speech Synthesis BART GLEU 58 단위없음 93 단위없음 4 요약 Text Summary BART ROUGE-1 40 % 47.98 % 5 요약 Text Summary BART ROUGE-2 19 % 27.16 % 6 요약 Text Summary BART ROUGE-L 38 % 38.24 % 7 음성인식 Speech Recognition Conformer WER 40 % 31.41 %
※ 데이터 성능 지표가 여러 개일 경우 각 항목을 클릭하면 해당 지표의 값이 그래프에 표기됩니다.
※ AI모델 평가 지표에 따라 측정값의 범위, 판단 기준이 달라질 수 있습니다. (ex. 오류율의 경우, 낮을수록 좋은 성능을 내는 것으로 평가됩니다)
-
설명서 및 활용가이드 다운로드
데이터 설명서 다운로드 구축활용가이드 다운로드1. 데이터 설명
과제명 주요 내용 데이터 구축량 데이터 형식 전문 분야 심층 인터뷰 데이터 실제 녹음 인터뷰, 방송, 유튜브에서 최소 2인 이상의 화자가 인터뷰 형식의 데이터 수집 및 가공 전문분야 15개의 카테고리를 대상으로 인터뷰 형식의 2,000시간 음성 데이터셋 질의-응답 쌍으로 구축된 인터뷰 음성 데이터와 가공 데이터가 매핑된 데이터셋 질의-응답 쌍으로 구축 및 실제 녹음 인터뷰에 한해 요약문 작성한 데이터셋 데이터 종류 내용 제공 형태 원천 데이터 정제 기준에 맞게 정제된 총 2,000시간의 음성 데이터 WAV 파일 라벨링 데이터 문장별 TN/ITN 병기, 전문용어 라벨링, 질의-응답 태깅 및 실제 녹음 인터뷰 500시간에 대해 요약문을 작성한 데이터 JSON 파일 2. json 형식
{
"metadata": {
"title": "REKM220009",
"creator": "솔트룩스",
"distributor": "솔트룩스",
"year": "2022",
"date": "20221027",
"media": "인터뷰",
"program_name": null,
"category": "예방의학/직업환경의학",
"sub_category": "예방의학/직업환경의학",
"speaker_num": 2
},
"speaker": [
{
"id": "1",
"sex": "여성",
"age": "30대",
"role": "질문자",
"occupation": null,
"degree": null
},
{
"id": "2",
"sex": "여성",
"age": "30대",
"role": "응답자",
"occupation": "연구교수",
"degree": "박사"
}
],
"utterance": [
{
"id": "REKM220009.1",
"speaker_id": "1",
"start": 0.0,
"end": 6.733,
"form": "어~ 전반부 인터뷰에 이어서 질문을 드리려고 하는데요.",
"original_form": "어~ 전반부 인터뷰에 이어서 질문을 드리려고 하는데요.",
"hangeulToEnglish": null,
"hangeulToNumber": null,
"term": null,
"QA": null
},3. 데이터 구성
key Description type metadata 메타데이터 object title 파일명 string creator 구축자 string distributor 배포자 string year 구축년도 string date 방송일자, 녹음일자 string media 원자료유형 string program_name 유튜브,프로그램명 string category 대분류 카테고리 string sub_category 중분류 카테고리 string speaker_num 화자 규모 number speaker 화자 array(object) id 화자 ID string sex 성별 string age 연령 string role 역할 string occupation 직업 string degree 최종 학위 string 4. 어노테이션 포맷
구분 항목명 타입 필수 설명 범위 1 metadata object Y 메타데이터 1-1 title string Y 파일명 *데이터 및 카테고리 유형 코드표 참조 1-2 creator string Y 구축자 솔트룩스 1-3 distributor string Y 배포자 솔트룩스 1-4 year string Y 구축년도 2022 1-5 date string Y 방송일자, 녹음일자 yyyymmdd 1-6 media string Y 원자료유형 유튜브,인터뷰,EBS,KBS 1-7 program_name string 유튜브,프로그램명 1-8 category string Y 대분류 카테고리 *데이터 및 카테고리 유형 코드표의 대분류 카테고리 구분에 한정함. 1-9 sub_category string Y 중분류 카테고리 데이터 및 카테고리 유형 코드표의 중분류 카테고리 구분에 한정함. 1-10 speaker_num number Y 화자 규모 2, 3, 4, 5 … 2 speaker array(object) Y 화자 규모 2-1 id string Y 화자 ID 1,2,3.. 2-2 sex string Y 성별 남성,여성 2-3 age string Y 연령 10대, 20대, 30대, 40대, 50대, 60대 이상 2-4 role string Y 역할 질문자,응답자, 진행자,패널 2-5 occupation string 직업 2-6 degree string 최종 학위 3 utterance array(object) Y 3-1 id string Y 발화 ID 파일명.발화순서 3-2 speaker_id string Y 화자 ID 3-3 start number Y 시작시간 소수점 3자리까지 3-4 end number Y 종료시간 소수점 3자리까지 3-5 form string Y 전사,라벨링 결과 3-6 original_form string Y 철자 전사 3-6-1 hangeulToEnglish array(object) 영어 전사 정보 3-6-1-1 id number Y 영어 전사 번호 1,2,3.. 3-6-1-2 hangeul string Y 사전에 없는 외래어 3-6-1-3 english string Y 영문 전사 3-6-2 hangeulToNumber array(object) 한글 전사된 숫자/수사 ITN 3-6-2-1 id number Y 한글 전사된 숫자 번호 1,2,3.. 3-6-2-2 hangeul string Y 한글 전사된 숫자 3-6-2-3 number string Y 숫자 전사 3-6-3 term array(object) 전문용어 3-6-3-1 id number Y 전문용어 번호 1,2,3.. 3-6-3-2 word string Y 전문용어 3-6-3-3 originalLanguage string Y 원어 3-6-3-4 etymology string 어원 3-6-3-5 allomorph string 이형태 3-6-4 QA object 질문-답변 쌍 정보 3-6-4-1 question_id string 질문 번호 3-6-4-2 answer_id string 답변 번호 4 summary array(object) 요약문(실 인터뷰 한정) 실 인터뷰(녹음) 총 500시간 4-1 id string Y 답변 번호 1,2,3.. 4-2 form string Y 답변 요약 내용 5. 실제 json 예시
{
"id": "REOV220045.41",
"speaker_id": "1",
"start": 221.972,
"end": 241.664,
"form": "그니까 이제 올리는 방식도 다르고 여행을 (@우주여행)/(#宇宙旅行)을 (@우주)/(#宇宙)를 뭘로 규정하고 여행을 뭘로 규정하는지에 따라서 조금씩 다른 게 있는데 지금 이제 회사 같은 경우에는 @상호명2 같은 경우에는 아 우리는 이런 정도의 전략으로 가면 좋겠다라고 대략 생각하시는 그림이나 그런 게 있을까요?",
"original_form": "그니까 이제 올리는 방식도 다르고 여행을 우주여행을 우주를 뭘로 규정하고 여행을 뭘로 규정하는지에 따라서 조금씩 다른 게 있는데 지금 이제 회사 같은 경우에는 &company-name2& 같은 경우에는 아 우리는 이런 정도의 전략으로 가면 좋겠다라고 대략 생각하시는 그림이나 그런 게 있을까요?",
"hangeulToEnglish": null,
"hangeulToNumber": null,
"term": [
{
"id": 1,
"word": "우주여행",
"originalLanguage": "宇宙旅行",
"etymology": null,
"allomorph": null
},
{
"id": 2,
"word": "우주",
"originalLanguage": "宇宙",
"etymology": null,
"allomorph": null
}
],
"QA": {
"question_id": "6",
"answer_id": null
}
},
{
"id": "REOV220045.42",
"speaker_id": "2",
"start": 241.664,
"end": 245.923,
"form": "아~ 저 여행 자체에 대해서는 생각 안 해봤네요.",
"original_form": "아~ 저 여행 자체에 대해서는 생각 안 해봤네요.",
"hangeulToEnglish": null,
"hangeulToNumber": null,
"term": null,
"QA": {
"question_id": null,
"answer_id": "6"
}
},
{
"id": "REOV220045.43",
"speaker_id": "2",
"start": 245.923,
"end": 254.852,
"form": "다만 그~ 아 일단 저는 이제 풍선 타고 올라가는 게 음~ 술 마시긴 좋을 것 같애요.",
"original_form": "다만 그~ 아 일단 저는 이제 풍선 타고 올라가는 게 음~ 술 마시긴 좋을 것 같애요.",
"hangeulToEnglish": null,
"hangeulToNumber": null,
"term": null,
"QA": {
"question_id": null,
"answer_id": "6"
}
-
데이터셋 구축 담당자
수행기관(주관) : ㈜솔트룩스
수행기관(주관) 책임자명 전화번호 대표이메일 담당업무 방재준 02-2193-1600 jjbang@saltlux.com □ 2-7.전문분야 심층인터뷰 총괄 책임자 - 인터뷰 적합 프로그램 협의 - 컨텐츠 사용 협약 및 수집 수행기관(참여)
수행기관(참여) 기관명 담당업무 ㈜알체라 □ 가공
- 정제 데이터 검토
- 전사 및 라벨링
- 오류 수정㈜소리자바 □ 정제
- 데이터 정제 크라우드워커 모집 및 관리
- 데이터 정제 수행 등비플라이소프트(주) □ 가공
- 정제 데이터 검토
- 전사 및 라벨링
- 오류 수정㈜비투엔 □ 검수
- 가공데이터 정확성 검수
- 통계 추출
- 차별화, 혐오발언 검토, 판단경북대학교 □ 설계
- 가공, 전사 지침 수립
- 파일구조 검토
- 프로그램 적합성 확인
- 혐오표현, 민감이슈 검토
- 가공데이터 정확성 검수데이터 관련 문의처
데이터 관련 문의처 담당자명 전화번호 이메일 방재준 02-2193-1600 jjbang@saltlux.com
-
인터넷과 물리적으로 분리된 온라인·오프라인 공간으로 의료 데이터를 포함하여 보안 조치가 요구되는 데이터를 다운로드 없이 접근하고 분석 가능
* 온라인 안심존 : 보안이 보장된 온라인 네트워크를 통해 집, 연구실, 사무실 등 어디서나 접속하여 데이터에 접근하고 분석
* 오프라인 안심존 : 추가적인 보안이 필요한 데이터를 대상으로 지정된 물리적 공간에서만 접속하여 데이터에 접근하고 분석 -
- AI 허브 접속
신청자 - 안심존
사용신청신청자신청서류 제출* - 심사구축기관
- 승인구축기관
- 데이터 분석 활용신청자
- 분석모델반출신청자
- AI 허브 접속
-
1. 기관생명윤리위원회(IRB) 심의 결과 통지서 [IRB 알아보기]
2. 기관생명윤리위원회(IRB) 승인된 연구계획서
3. 신청자 소속 증빙 서류 (재직증명서, 재학증명서, 근로계약서 등 택1)
4. 안심존 이용 신청서 [다운로드]
5. 보안서약서 [다운로드]
※ 상기 신청서 및 첨부 서류를 완비한 후 신청을 진행하셔야 정상적으로 절차가 이루어집니다. -
신청 및 이용관련 문의는 safezone1@aihub.kr 또는 02-525-7708, 7709로 문의
데이터셋 다운로드 승인이 완료 된 후 API 다운로드 서비스를 이용하실 수 있습니다.
API 다운로드 파일은 분할 압축되어 다운로드 됩니다. 분할 압축 해제를 위해서는 분할 압축 파일들의 병합이 필요하며 리눅스 명령어 사용이 필요합니다.
리눅스 OS 계열에서 다운로드 받으시길 권장하며 윈도우에서 파일 다운로드 시 wsl(리눅스용 윈도우 하위 시스템) 설치가 필요합니다.
※ 파일 병합 리눅스 명령어
find "폴더경로" -name "파일명.zip.part*" -print0 | sort -zt'.' -k2V | xargs -0 cat > "파일명.zip"
- 해당 명령어 실행 시, 실행 경로 위치에 병합 압축 파일이 생성됩니다.
- 병합된 파일 용량이 0일 경우, 제대로 병합이 되지 않은 상태이니 "폴더경로"가 제대로 입력되었는지 확인 부탁드립니다.
※ 데이터셋 소개 페이지에서 다운로드 버튼 클릭하여 승인이 필요합니다.