-
데이터 변경이력
데이터 변경이력 버전 일자 변경내용 비고 1.1 2023-11-10 데이터 최종 개방 1.0 2023-07-31 데이터 개방(Beta Version) 데이터 히스토리
데이터 히스토리 일자 변경내용 비고 2023-12-22 산출물 전체 공개 소개
기초과학 30만 문장 이상의 원시데이터에 대한 인공지능 학습용 데이터 저작권 확보 후 중분류 5개 분야, 소분류 10개 분야로 분류하여 원시데이터를 수집하고 정제, 가공(특수라벨링/번역), 검수 작업을 실시하여 공공/산업전반에 빅데이터로 활용할 수 있는 기초과학 분야 다국어(영어, 중국어, 일본어) 번역 말뭉치 데이터
구축목적
● 기초과학 분야의 원시데이터에 대한 인공지능 학습용 데이터 저작권 확보 ● 활용도가 높은 영어, 중국어, 일본어 번역 말뭉치 구축 ● 인공지능 성능 향상을 위한 30만 문장 이상의 고품질 대규모 데이터 구축
-
메타데이터 구조표 데이터 영역 한국어 데이터 유형 텍스트 데이터 형식 JSON 데이터 출처 도서,논문,간행물 라벨링 유형 번역(자연어) 라벨링 형식 JSON 데이터 활용 서비스 다국어 기계번역 데이터 구축년도/
데이터 구축량2022년/308,064 건 -
데이터 통계
<데이터 구축 규모> 총 308,064 건
데이터 종류 데이터 형태 원문 규모 비율 도서 텍스트 217,305 70.50% 논문 텍스트 57,575 18.70% 간행물 텍스트 33,184 10.80% 합계 308064 <주제별 분포>
구분 원문 건수 비율 수학 57,998 18.80% 물리학 62,686 20.30% 화학 58,451 19% 지구과학 65,153 21.20% 생명과학 63,776 20.70% 합계 308064 <언어별 분포>
구분 원문 건수 비율 중국어 번역 90,051 29.20% 영어 번역 127,567 41.40% 일본어 번역 90,489 29.40% 합계 308064 -
-
AI 모델 상세 설명서 다운로드
AI 모델 상세 설명서 다운로드 AI 모델 다운로드학습 AI 모델
- 구축 데이터의 유효성을 검증하기 위하여 가공이 완료된 본 데이터를 인공지능 학습모델을 통해 검증
- 다국어로 번역하여 구축한 데이터의 유효성을 입증하게 위해 self-attention 기반의 Transformer 알고리즘을 통해 번역 모델 구성
- 학습된 번역 모델로 실제 구축한 데이터를 검증하기 위하여 범용적인 평가도구인 BLEU score 사용
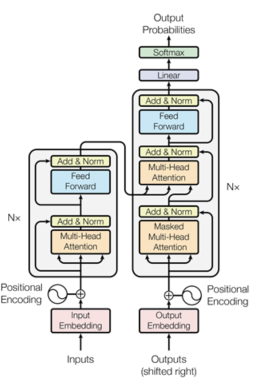
<기계번역 모델의 번역 품질 평가_BLEU score>
구분 항목명 측정 지표 측정 산식 유효성 기계 BLEU score 
번역 - 모델 구축은 언어별로 진행하였으며, 한영 말뭉치는 123,585 쌍, 한중 말뭉치는 91,602 쌍, 한일 말뭉치는 92,877 쌍임
- 언어별 학습을 통한 BLEU 평가 결과, 한영 번역 모델은 31.32가 나왔으며, 한중 번역 모델은 42.50이, 한일 번역 모델은 65.30이 나옴
- 이러한 결과는 사업 제안서에서 제시안 BLEU score 27.5 보다 월등히 높은 수치로 구축한 기초과학 분야 다국어 번역 말뭉치 데이터 품질의 우수성을 입증함
-
데이터 성능 점수
측정값 (%)기준값 (%)데이터 성능 지표
데이터 성능 지표 번호 측정항목 AI TASK 학습모델 지표명 기준값 점수 측정값 점수 1 인공신경망 기반 번역모델의 문장 번역 성능 (한-중) Machine Translation Attention 메커니즘을 기반으로 한 Transformer 모델 BLEU 0.275 점 0.5075 점 2 인공신경망 기반 번역모델의 문장 번역 성능 (한-일) Machine Translation Attention 메커니즘을 기반으로 한 Transformer 모델 BLEU 0.275 점 0.7639 점 3 인공신경망 기반 번역모델의 문장 번역 성능 (한-영) Machine Translation Attention 메커니즘을 기반으로 한 Transformer 모델 BLEU 0.275 점 0.3662 점 4 인공신경망 기반 번역모델의 문장 번역 성능 (한-중) Machine Translation Attention 메커니즘을 기반으로 한 Transformer 모델 BLEU 0.275 점 0.4608 점 5 인공신경망 기반 번역모델의 문장 번역 성능 (한-일) Machine Translation Attention 메커니즘을 기반으로 한 Transformer 모델 BLEU 0.275 점 0.7178 점
※ 데이터 성능 지표가 여러 개일 경우 각 항목을 클릭하면 해당 지표의 값이 그래프에 표기됩니다.
※ AI모델 평가 지표에 따라 측정값의 범위, 판단 기준이 달라질 수 있습니다. (ex. 오류율의 경우, 낮을수록 좋은 성능을 내는 것으로 평가됩니다)
-
설명서 및 활용가이드 다운로드
데이터 설명서 다운로드 구축활용가이드 다운로드<원문데이터 포맷 예시>
제목 물성의 원리 도서 유형 도서 저자 최낙언 지음 출간연도 2018 대분류 기초과학 중분류 화학 소분류 NC09 원문 결국 식품의 대부분은 탄수화물, 단백질, 지방, 물과 같이 맛도 향도 색도 없는 성분이며, 먹을 때 식감을 주는 성분이다. 전처리 후 결국 식품의 대부분은 탄수화물, 단백질, 지방, 물과 같이 맛도 향도 색도 없는 성분이며, 먹을 때 식감을 주는 성분이다. {
"chunk-number": ,
"paragraph": [
{
"info": {
"Index": "",
"Title": "",
"Publication_type": "",
"Author": "",
"ISBN": "",
"ISSN": null,
"Published_year": ,
"Date_created": "",
"Classify_1": "",
"Classify_2": "",
"Classify_3": ""
},
"sentences": [
{
"src_sentence": "",
"tgt_sentence": "",
"src_lang": "ko",
"tgt_lang": "ch",
"src_paragraphs_id": "",
"src_word_count": 17,
"spc_technical_label": "",
"spc_idiomatic_label": ,
"spc_proper_label": "",
"spc_double_label":
},데이터 구성
Key Description Type Child Type chunk-number 문장수 Number paragraph 도서정보 JsonArray JsonObject [ Index 데이터셋 식별자 String Title 제목 String Publication_type 출판물 종류 String Author 저자 String ISBN ISBN 도서 식별 넘버 String ISSN ISSN 논문 식별 넘버 String Published_year 도서 출간연도 Number Date_created 데이터 최초 생성일자 String Classify_1 주제 대분류 String Classify_2 주제 중분류 String Classify_3 주제 소분류 String ] sentences 문장정보 JsonArray JsonObject [ src_sentence 원문 텍스트 String tgt_sentence 번역문 텍스트 String src_lang 원문 언어 String tgt_lang 번역문 언어 String src_paragraphs_id 문장 식별코드 String src_word_count 원문 어절수 String spc_technical_label 특수라벨(전문용어) String spc_idiomatic_label 특수라벨 (관용표현) String spc_proper_label 특수라벨 (고유명사) String spc_double_label 특수라벨 (중의어) String ] No 항목 길이 타입 필수여부 비고 한글명 영문명 1 도서정보 JsonObject 1-1 데이터셋 식별자 Index String Y 1-2 제목 Title String Y 1-3 출판물 종류 Publication_type String Y 1-4 저자 Author String Y 1-5 ISBN 도서 식별 넘버 ISBN String 1-6 ISSN 논문 식별 넘버 ISSN String 1-7 도서 출간연도 Published_year Number Y yyyy 1-8 데이터 최초 생성 일자 Date_created String Y yyyy-mm-dd 1-9 주제 대분류 Classify_1 String Y 1-10 주제 중분류 Classify_2 String Y 1-11 주제 소분류 코드 Classify_3 String Y 2 문장정보 JsonObject 2-1 원문 텍스트 src_sentence String Y 2-2 번역문 텍스트 tgt_sentence String Y 2-3 원문 언어 src_lang String Y 2-4 번역문 언어 tgt_lang String Y 2-5 문장 식별코드 src_paragraphs_id String Y 2-6 원문 어절수 src_word_count String Y 2-7 특수라벨(전문용어) spc_technical_label String 2-8 특수라벨 (관용표현) spc_idiomatic_label String 2-9 특수라벨 (고유명사) spc_proper_label String 2-10 특수라벨 (중의어) spc_double_label String 실제예시
"chunk-number": 4990,
"paragraph": [
{
"info": {
"Index": "0176641247",
"Title": "물성의 원리",
"Publication_type": "도서",
"Author": "최낙언 지음",
"ISBN": "9788970016931",
"ISSN": null,
"Published_year": 2018,
"Date_created": "2023-01-31",
"Classify_1": "기초과학",
"Classify_2": "화학",
"Classify_3": "NC09"
},
"sentences": [
{
"src_sentence": "결국 식품의 대부분은 탄수화물, 단백질, 지방, 물과 같이 맛도 향도 색도 없는 성분이며, 먹을 때 식감을 주는 성분이다.",
"tgt_sentence": "After all, most foods consist of ingredients, such as carbohydrates, proteins, fats, and water, that give texture when we eat them but have no taste, smell, or color.",
"src_lang": "ko",
"tgt_lang": "en",
"src_paragraphs_id": "SI-2208241415P88476092R0100015",
"src_word_count": 18,
"spc_technical_label": "식품,탄수화물,단백질,지방,물,맛,향,색,성분,성분",
"spc_idiomatic_label": null,
"spc_proper_label": null,
"spc_double_label": null
},
... -
데이터셋 구축 담당자
수행기관(주관) : 미니게이트
수행기관(주관) 책임자명 전화번호 대표이메일 담당업무 황지영 070-4088-0143 hwang@minigate.net 데이터 라벨링, 검사 수행기관(참여)
수행기관(참여) 기관명 담당업무 (주)웅진북센 데이터 수집 와이즈닷 데이터 정제, 번역 데이터 관련 문의처
데이터 관련 문의처 담당자명 전화번호 이메일 황지영 070-4088-0143 hwang@minigate.net
-
인터넷과 물리적으로 분리된 온라인·오프라인 공간으로 의료 데이터를 포함하여 보안 조치가 요구되는 데이터를 다운로드 없이 접근하고 분석 가능
* 온라인 안심존 : 보안이 보장된 온라인 네트워크를 통해 집, 연구실, 사무실 등 어디서나 접속하여 데이터에 접근하고 분석
* 오프라인 안심존 : 추가적인 보안이 필요한 데이터를 대상으로 지정된 물리적 공간에서만 접속하여 데이터에 접근하고 분석 -
- AI 허브 접속
신청자 - 안심존
사용신청신청자신청서류 제출* - 심사구축기관
- 승인구축기관
- 데이터 분석 활용신청자
- 분석모델반출신청자
- AI 허브 접속
-
1. 기관생명윤리위원회(IRB) 심의 결과 통지서 [IRB 알아보기]
2. 기관생명윤리위원회(IRB) 승인된 연구계획서
3. 신청자 소속 증빙 서류 (재직증명서, 재학증명서, 근로계약서 등 택1)
4. 안심존 이용 신청서 [다운로드]
5. 보안서약서 [다운로드]
※ 상기 신청서 및 첨부 서류를 완비한 후 신청을 진행하셔야 정상적으로 절차가 이루어집니다. -
신청 및 이용관련 문의는 safezone1@aihub.kr 또는 02-525-7708, 7709로 문의
데이터셋 다운로드 승인이 완료 된 후 API 다운로드 서비스를 이용하실 수 있습니다.
API 다운로드 파일은 분할 압축되어 다운로드 됩니다. 분할 압축 해제를 위해서는 분할 압축 파일들의 병합이 필요하며 리눅스 명령어 사용이 필요합니다.
리눅스 OS 계열에서 다운로드 받으시길 권장하며 윈도우에서 파일 다운로드 시 wsl(리눅스용 윈도우 하위 시스템) 설치가 필요합니다.
※ 파일 병합 리눅스 명령어
find "폴더경로" -name "파일명.zip.part*" -print0 | sort -zt'.' -k2V | xargs -0 cat > "파일명.zip"
- 해당 명령어 실행 시, 실행 경로 위치에 병합 압축 파일이 생성됩니다.
- 병합된 파일 용량이 0일 경우, 제대로 병합이 되지 않은 상태이니 "폴더경로"가 제대로 입력되었는지 확인 부탁드립니다.
※ 데이터셋 소개 페이지에서 다운로드 버튼 클릭하여 승인이 필요합니다.