-
데이터 변경이력
데이터 변경이력 버전 일자 변경내용 비고 1.2 2024-12-04 서브라벨링 추가 개방 1.1 2024-10-30 데이터 최종 개방 1.0 2024-08-06 데이터 개방 Beta Version 데이터 히스토리
데이터 히스토리 일자 변경내용 비고 2024-08-06 산출물 공개 Beta Version 소개
- 다국어 언어쌍에 대한 양방향 병렬 번역 말뭉치 데이터 - 기계 번역 품질 예측 활용을 위한 번역 품질 평가 라벨링 데이터
구축목적
- 기계 번역 품질 고도화를 위한 번역 말뭉치 구축 - 기계 번역 품질 예측 활용을 위한 다국어 번역 품질 평가 데이터 구축
-
메타데이터 구조표 데이터 영역 한국어 데이터 유형 텍스트 데이터 형식 json 데이터 출처 신문기사, 학술논문, 뉴스레터 라벨링 유형 번역(자연어) 라벨링 형식 json 데이터 활용 서비스 기계번역 품질 평가 데이터 구축년도/
데이터 구축량2023년/• 원천데이터 : 300,000문장 • 라벨링데이터 - 번역데이터(HT) : 307,175문장 - 평가데이터(MTPE) : 122,808문장 -
- 데이터 구축 규모
데이터 구축 규모 항목명 지표 규모 구축량 문장수 원천데이터 307,175문장 번역말뭉치(HT) 307,175문장 평가데이터(MTPE) 122,808문장 언어쌍 분포 수량 각 언어쌍별 목표 수량(번여 데이터 각 50,000문장, 평가 데이터 각 20,000문장) 이상 주제 분포 비율 14개 세부 분야별 데이터 분포 확인 문장 길이 분포 어절 수 평균 10어절 이상 - 데이터 분포
데이터 분포 데이터 분류 언어 중분류 수량 원천데이터 한국어 공학 24,814 구어체 31,632 농수해양학 18,187 복합학 5,018 사회과학 32,628 예술체육 7,930 의약학 12,141 인문학 5,027 자연과학 15,199 영어 공학 9,100 농수해양학 6,776 복합학 1,770 사회과학 16,663 예술체육 1,509 의약학 5,550 인문학 1,690 자연과학 7,253 일본어 경제 12,600 과학 5,705 문화 7,875 사회 16,800 정치 9,450 중국어 경제 12,028 과학 5,705 문화 7,875 사회 16,800 정치 9,450 번역말뭉치(HT) 영-한 공학 9,100 농수해양학 6,776 복합학 1,770 사회과학 16,663 예술체육 1,509 의약학 5,550 인문학 1,690 자연과학 7,253 일-한 경제 12,600 과학 5,705 문화 7,875 사회 16,800 정치 9,450 중-한 경제 12,028 과학 5,705 문화 7,875 사회 16,800 정치 9,450 한-영 공학 5,558 구어체 10,112 농수해양학 6,709 복합학 1,743 사회과학 11,571 예술체육 2,956 의약학 4,227 인문학 2,581 자연과학 5,945 한-일 공학 9,331 구어체 9,711 농수해양학 6,253 복합학 2,058 사회과학 11,879 예술체육 1,987 의약학 3,699 인문학 1,219 자연과학 4,625 한-중 공학 9,925 구어체 11,809 농수해양학 5,225 복합학 1,216 사회과학 9,179 예술체육 2,987 의약학 4,215 인문학 1,227 자연과학 4,629 평가데이터(MTPE) 영-한 공학 3,640 농수해양학 2,928 복합학 708 사회과학 5,997 예술체육 1,097 의약학 2,220 인문학 671 자연과학 3,488 일-한 경제 5,040 과학 2,282 문화 3,150 사회 6,720 정치 3,780 중-한 경제 5,040 과학 2,282 문화 3,150 사회 6,704 정치 3,780 한-영 공학 2,223 구어체 4,999 농수해양학 1,607 복합학 370 사회과학 5,712 예술체육 1,266 의약학 1,477 인문학 493 자연과학 1,853 한-일 공학 4,523 구어체 5,498 농수해양학 1,597 복합학 368 사회과학 3,691 예술체육 618 의약학 1,479 인문학 491 자연과학 1,853 한-중 공학 3,106 구어체 5,000 농수해양학 2,673 복합학 370 사회과학 4,427 예술체육 618 의약학 1,473 인문학 493 자연과학 1,853 -
-
AI 모델 상세 설명서 다운로드
AI 모델 상세 설명서 다운로드 AI 모델 다운로드- 다국어 트랜스포머 기반 Predictor-Estimator 구조 모델을 활용한 품질 예측 모델
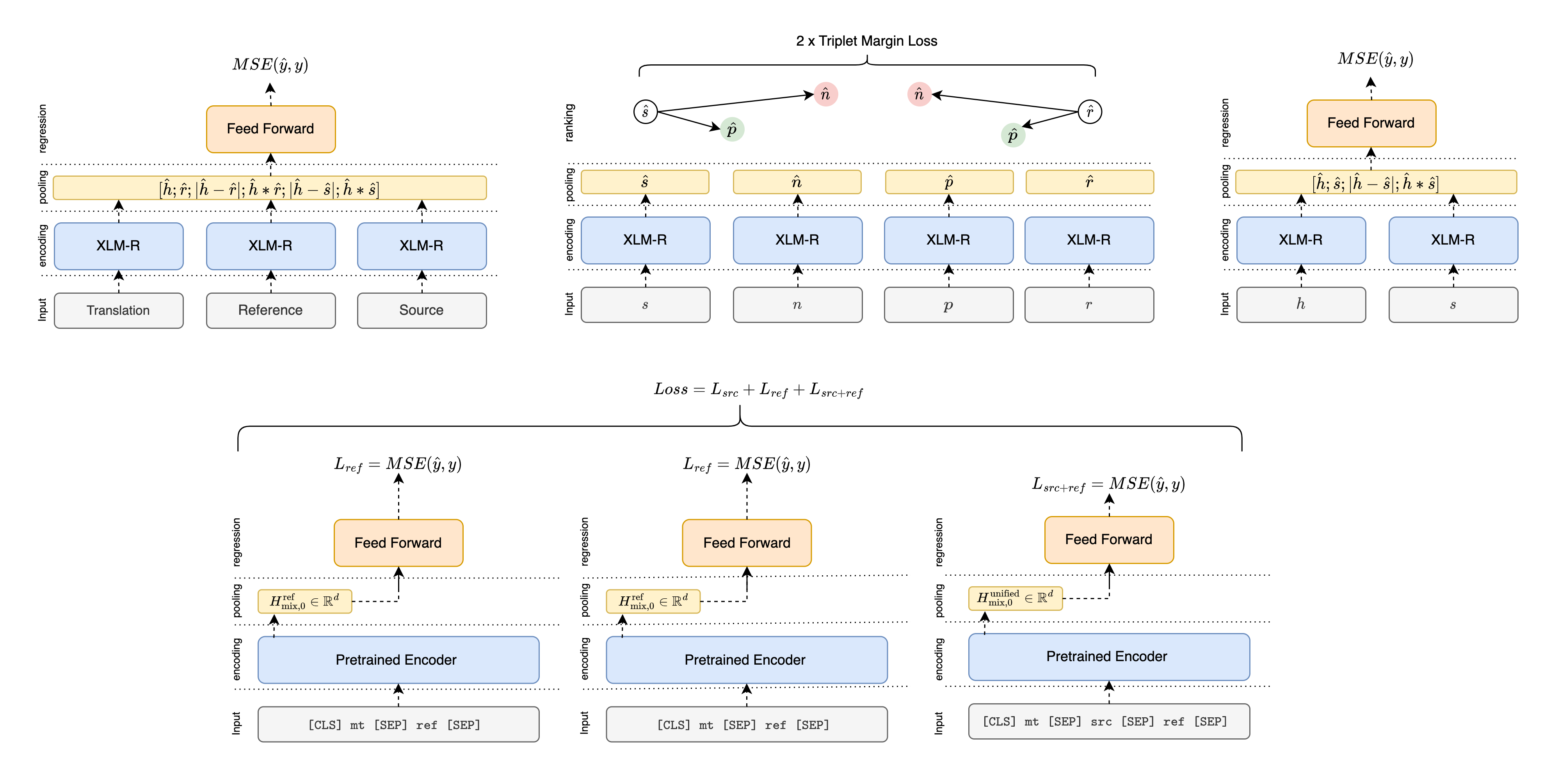
[COMET DA 예측]
- 기학습된 인코더 모델을 Predictor로 사용
- 인코더 모델로 BERT, XLM-RoBERTa, MiniLM, XLM-RoBERTa-XL, RemBERT 등 활용 가능
- Estimator로서 설정된 크기의 Layer를 생성하여 학습 및 추론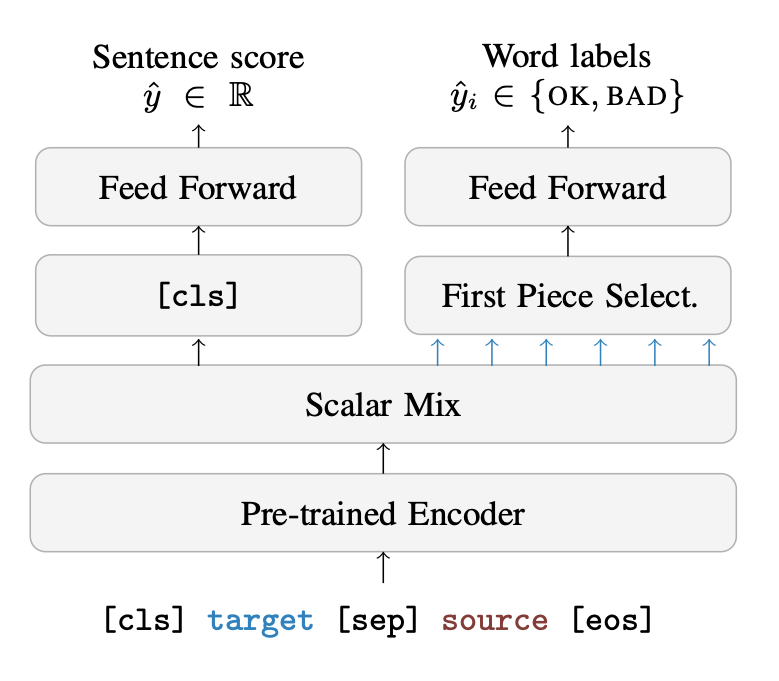
[OpenKiwi HTER, OK/BAD 예측]
- 문장을 어절 단위로 나누고, 이를 벡터화하여 Transformer의 인코더에 입력
- 어텐션 메커니즘을 통해 문장의 전역적인 정보와 문맥을 학습
- 이를 통해 사용자들은 번역 결과 중 선택적으로 옳은 부분을 채택 혹은 틀린 부분을 수정할 수 있으며, 여러 변역 결과 중 가장 좋은 번역 결과를 선택할 수 있음 -
설명서 및 활용가이드 다운로드
데이터 설명서 다운로드 구축활용가이드 다운로드- 데이터 구성 및 어노테이션 포맷
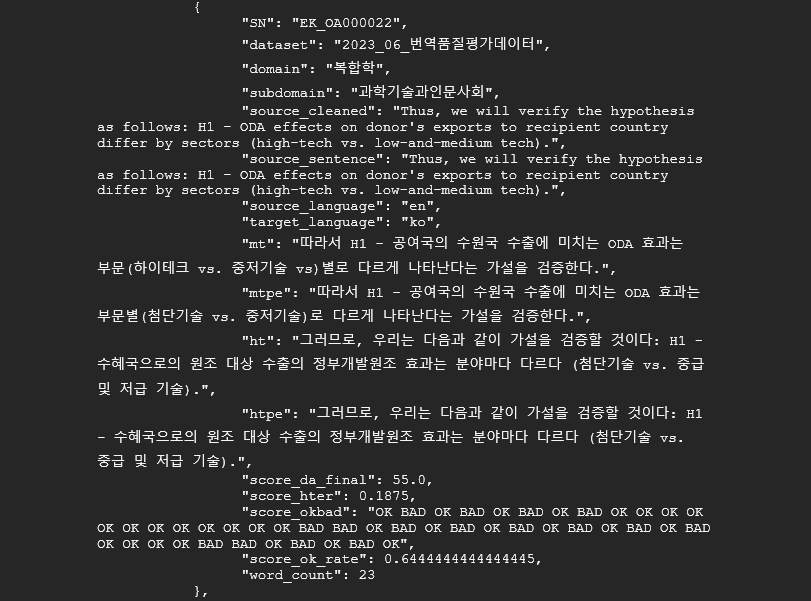
데이터 구성 및 어노테이션 포맷 항목 설정 1 2 3 타입 필수여부 설명 비고 data array {} object SN string Y 일련번호 KJ_HM189640 dataset string Y 파일명 2023_06_번역품질평가데이터 domain string Y 대분류 자연과학 subdomain string Y 중분류 화학 source_cleaned string Y 원천데이터 source_sentence string Y 정제된 원문 source_language string Y 원문 언어 target_language string Y 번역문 언어 mt string N 기계번역문 평가 데이터(2만 건)는 필수 프로퍼티 mtpe string N 기계번역 사후교정문 평가 데이터(2만 건)는 필수 프로퍼티 ht string Y 휴먼 번역문 htpe string Y 휴먼 번역 검수문 score_da_final number N DA점수 평가 데이터(2만 건)는 필수 프로퍼티 score_hter number N HTER 점수 평가 데이터(2만 건)는 필수 프로퍼티 score_okbad string N OK/BAD 측정 평가 데이터(2만 건)는 필수 프로퍼티 score_ok_rate number N OK 비율 평가 데이터(2만 건)는 필수 프로퍼티 word_count number Y 한국어 기준 어절수 - 데이터 포맷
데이터 포맷 구분 내용 데이터명 다국어 번역 품질 평가 데이터 모델 임무 유형 번역 (한-영, 영-한, 한-일, 일-한, 한-중, 중-한) 및 평가(DA점수, HTER, OK/BAD) 어노테이션 유형 1) 번역 2) 기준에 따른 DA점수 라벨링, 산식 적용에 따른 HTER 및 OK/BAD 기계적 태깅 데이터 구성 원천데이터(JSON)-라벨 데이터(JSON) 데이터 예시 <라벨링 데이터 예시>
{
"data": [
{
"SN": "NC18964058",
"dataset": "2023_06_번역품질평가데이터",
"domain": "자연과학",
"subdomain": "화학",
"source_cleaned": "수돗물에서 탄소강 시편에 대한 잔류염소에 따른 부식속도결과는 Fig. 3과 같다.",
"source_sentence": "수돗물에서 탄소강 시편에 대한 잔류염소에 따른 부식속도결과는 Fig. 3과 같다.",
"source_language": "ko",
"target_language": "en",
"mt": "Corrosion rate results according to residual chlorine for carbon steel specimens in tap water are the same as in Fig. 3.",
"mtpe": null,
"ht": "Fig. 3 shows corrosion rates for tap water by residual chlorine in carbon steel specimen.",
"htpe": "Fig. 3 shows corrosion rates for tap water by residual chlorine in carbon steel specimen.",
"score_da_final": 70,
"score_hter": 0.19047619,
"score_okbad": "OK OK OK OK OK OK OK OK OK OK OK OK OK OK OK OK OK OK OK OK OK OK OK OK OK OK OK OK OK OK OK BAD OK BAD OK BAD OK BAD OK BAD OK BAD OK",
"score_ok_rate": 0.860465116
"word_count": 10
}
]
}
※ 전체 번역 문장 쌍 중 무작위 2만 쌍에 대해 번역 평가를 위한 기계번역문, 기계번역 사후교정문 및 평가 점수 추가 라벨링(추후 변경될 수 있음)- JSON 포맷 예시
-
데이터셋 구축 담당자
수행기관(주관) : 트위그팜
수행기관(주관) 책임자명 전화번호 대표이메일 담당업무 최규동 02-1833-5926 ken.choi@twigfarm.net 사업 총괄 수행기관(참여)
수행기관(참여) 기관명 담당업무 글나무 HT 번역 및 검수 시스트란 MTPE 번역 및 검수 에퀴코리아 HT 번역 및 검수 푸르모디티 MTPE 번역 및 검수 플리토 HT 번역 및 검수 데이터 관련 문의처
데이터 관련 문의처 담당자명 전화번호 이메일 최규동 02-1833-5926 ken.choi@twigfarm.net AI모델 관련 문의처
AI모델 관련 문의처 담당자명 전화번호 이메일 최규동 02-1833-5926 ken.choi@twigfarm.net 저작도구 관련 문의처
저작도구 관련 문의처 담당자명 전화번호 이메일 최규동 02-1833-5926 ken.choi@twigfarm.net
-
인터넷과 물리적으로 분리된 온라인·오프라인 공간으로 의료 데이터를 포함하여 보안 조치가 요구되는 데이터를 다운로드 없이 접근하고 분석 가능
* 온라인 안심존 : 보안이 보장된 온라인 네트워크를 통해 집, 연구실, 사무실 등 어디서나 접속하여 데이터에 접근하고 분석
* 오프라인 안심존 : 추가적인 보안이 필요한 데이터를 대상으로 지정된 물리적 공간에서만 접속하여 데이터에 접근하고 분석 -
- AI 허브 접속
신청자 - 안심존
사용신청신청자신청서류 제출* - 심사구축기관
- 승인구축기관
- 데이터 분석 활용신청자
- 분석모델반출신청자
- AI 허브 접속
-
1. 기관생명윤리위원회(IRB) 심의 결과 통지서 [IRB 알아보기] [공용IRB 심의신청 가이드라인]
2. 기관생명윤리위원회(IRB) 승인된 연구계획서
3. 신청자 소속 증빙 서류 (재직증명서, 재학증명서, 근로계약서 등 택1)
4. 안심존 이용 신청서 [다운로드]
5. 보안서약서 [다운로드]
※ 상기 신청서 및 첨부 서류를 완비한 후 신청을 진행하셔야 정상적으로 절차가 이루어집니다. -
신청 및 이용관련 문의는 safezone1@aihub.kr 또는 02-525-7708, 7709로 문의
데이터셋 다운로드 승인이 완료 된 후 API 다운로드 서비스를 이용하실 수 있습니다.
API 다운로드 파일은 분할 압축되어 다운로드 됩니다. 분할 압축 해제를 위해서는 분할 압축 파일들의 병합이 필요하며 리눅스 명령어 사용이 필요합니다.
리눅스 OS 계열에서 다운로드 받으시길 권장하며 윈도우에서 파일 다운로드 시 wsl(리눅스용 윈도우 하위 시스템) 설치가 필요합니다.
※ 파일 병합 리눅스 명령어
find "폴더경로" -name "파일명.zip.part*" -print0 | sort -zt'.' -k2V | xargs -0 cat > "파일명.zip"
- 해당 명령어 실행 시, 실행 경로 위치에 병합 압축 파일이 생성됩니다.
- 병합된 파일 용량이 0일 경우, 제대로 병합이 되지 않은 상태이니 "폴더경로"가 제대로 입력되었는지 확인 부탁드립니다.
※ 데이터셋 소개 페이지에서 다운로드 버튼 클릭하여 승인이 필요합니다.
오프라인 데이터 이용 안내
본 데이터는 K-ICT 빅데이터센터에서도 이용하실 수 있습니다.
다양한 데이터(미개방 데이터 포함)를 분석할 수 있는 오프라인 분석공간을 제공하고 있습니다.
데이터 안심구역 이용절차 및 신청은 K-ICT빅데이터센터 홈페이지를 참고하시기 바랍니다.

국방데이터 개방 안내
본 데이터는 국방데이터로 군사 보안에 따라 AI허브에서 데이터를 제공하지 않으며,
군 담당자를 통한 별도의 사용 신청이 필요합니다.