-
데이터 변경이력
데이터 변경이력 버전 일자 변경내용 비고 1.2 2024-12-04 서브라벨링 추가 개방 1.1 2024-10-30 데이터 최종 개방 1.0 2024-08-09 데이터 개방 Beta Version 데이터 히스토리
데이터 히스토리 일자 변경내용 비고 2025-06-16 구축업체 정보수정 2024-08-09 산출물 공개 Beta Version 2024-07-15 구축업체정보 수정 이메일 주소 변경 소개
- 한국 콘텐츠 산업의 해외성장세에 발맞춰, 자연어를 기반으로 하는, 상황별 신조어, 약어, 은어, 관용적 의미와 어투까지 효과적으로 전달 가능한 인공지능 학습데이터 구축 및 모델 개발
구축목적
- 연구분야 및 산업분야에 부합하는 인공지능 기술 및 서비스가 실현 가능한 라이브 스트리밍 영상 영어 통번역의 성능 향상을 위한 인공지능 학습용 통번역 데이터 구축
-
메타데이터 구조표 데이터 영역 한국어 데이터 유형 오디오 , 텍스트 데이터 형식 PCM 형식의 WAV 데이터 출처 자체수집 라벨링 유형 번역(자연어), 전사(음성) 라벨링 형식 json(UTF-8) 데이터 활용 서비스 영상 요약 및 번역 서비스, 한국어 음성 연구 및 대화체 음성 인식 서비스, 다국어 통번역 서비스, 영어 영상 자막 자동 생성 서비스 데이터 구축년도/
데이터 구축량2023년/총 파일수: 4,701,948 / 서브라벨링: 2,157 -
- 데이터 구축 규모
데이터 구축 규모 데이터명 원천데이터 구분 원천데이터 라벨링데이터 서브 구축량 구축량 라벨링 001-001
라이브
스트리밍 영상 영어 통번역
데이터한국어-영어 일상,소통 343,025 343,025 946 여행 144,339 144,339 게임 85,343 85,343 경제 23,162 23,162 교육 95,838 95,838 스포츠 25,376 25,376 라이브커머스 229,679 229,679 음식,요리 115,280 115,28 영어-한국어 일상,소통 327,604 327,604 1,211 여행 304,228 304,228 게임 178,339 178,339 음식,요리 277,789 277,789 건강,운동 200,972 200,972 표 4. 데이터 구축 규모
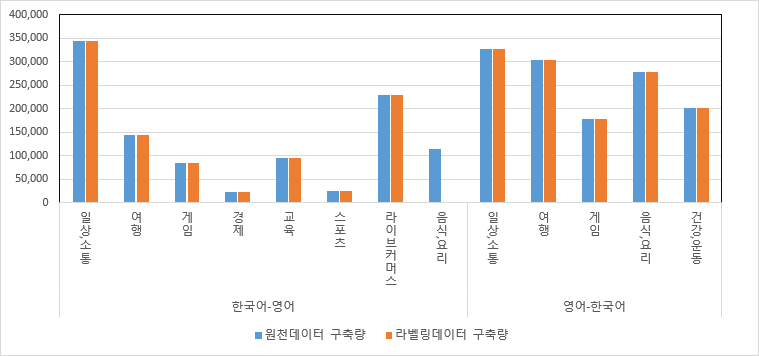
그래프 1. 데이터 구축 규모
- 데이터 분포
데이터 분포 성별 분포 speaker_gender COUNT 비율 남성 1,645,263 69.98% 여성 705,711 30.02% 합계 2,350,974 100.00% 표 5. 데이터 분포
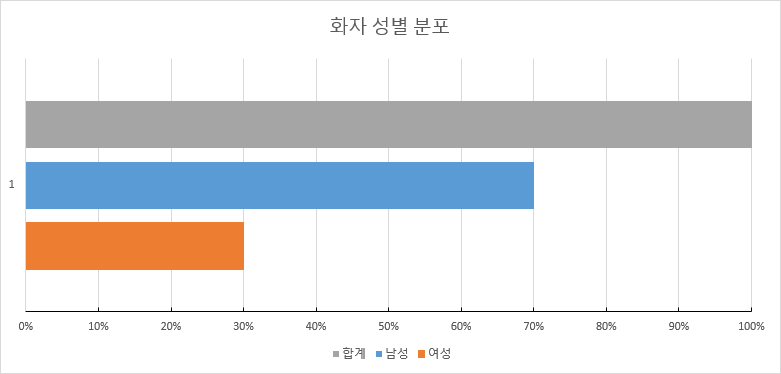
그래프 2. 데이터 분포
- 데이터 클래스 분포 명세
데이터 클래스 분포 명세 데이터명 원천데이터 구분 구축 비율 001-001 라이브 스트리밍 영상 영어 통번역 데이터 한국어 일상,소통 20% 여행 15% 게임 15% 경제 5% 교육 5% 스포츠 5% 라이브커머스 15% 음식,요리 20% 영어 일상,소통 20% 여행 20% 게임 20% 음식,요리 20% 건강,운동 20% 표 6. 데이터 클래스 분포 명세
-
-
AI 모델 상세 설명서 다운로드
AI 모델 상세 설명서 다운로드 AI 모델 다운로드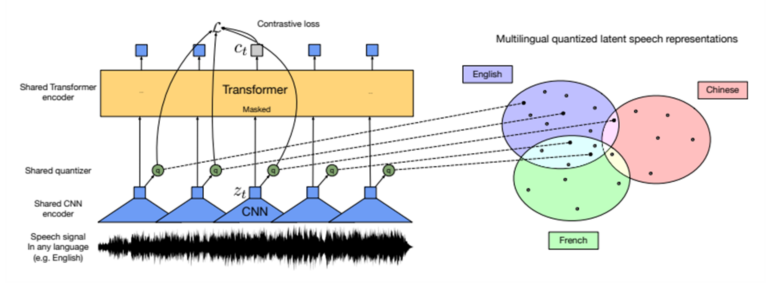
이미지 1. Transfomer model
- Wav2Vec2.0-XLSR
○ 개요
- 여러 언어의 음성 파일로 단일 모델을 pre training
- XLSR은 wav2vec2.0를 기반으로 하며, 숨겨진 음성 표현(latent speech representation)의 대비 작업(contrastive task)을 해결하여 학습하며 다국어 간에 공유되는 숨겨진 부분(latent shared)의 양자화(quantization)를 공통으로 학습
- 모델은 레이블이 지정된 데이터로 세밀하게 조정○ Fine tuning
- model의 output layer 바로 위에 downstream task의 representing vocab을 이용해 결과값을 생성해 낼 수 있게 linear classifier layer를 결합해 CTC(Connectionist Temporal Classification) loss를 이용하여 파인 튜닝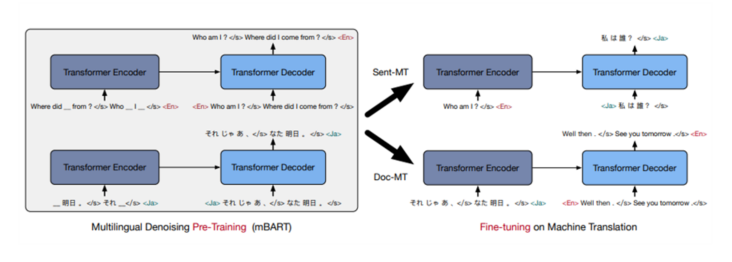
이미지 2. Fine tuning
- MBART
○ 개요
- 다국어 데이터들을 denoising 방식으로 pretrained 된 모델이 번역 task에서 높은 성능을 보임을 입증함.
- mBART는 encoder, decoder 혹은 reconstructing 부분에만 집중하던 이전의 연구들과는 다르게 다국어로 전체 텍스트를 denoising 하는 방법론을 제시함.
- 번역 task를 위한 fine tuning을 하기 위해 모델에 추가적인 작업 없이도 지도학습이던 비지도 학습이던 바로 fine tuning이 가능함. -
설명서 및 활용가이드 다운로드
데이터 설명서 다운로드 구축활용가이드 다운로드- 데이터 구성
데이터 구성 메타 데이터 ID 필수
여부형식 콘텐츠 정보
(contents)콘텐츠 아이디 contentsidx ○ string 라이브 스트리밍 출처 source ○ string 라이브 스트리밍 카테고리 category ○ string 저작권 solved_copyright ○ string 라이브 스트리밍 콘텐츠 언어 origin_lang ○ string 파일 정보
(file)라이브 스트리밍 콘텐츠 원본 데이터 파일명 source_filename ○ string 라이브 스트리밍 콘텐츠 원본 데이터 파일주소 source_filepath ○ string 라이브 스트리밍 콘텐츠의 음성 추출 데이터 파일명 sound_filename ○ string 라이브 스트리밍 콘텐츠의 음성 추출 데이터 파일주소 sound_filepath ○ string 목소리 추출 데이터의 시작 시간 start_voice_time ○ string 목소리 추출 데이터의 종료 시간 end_voice_time ○ string 총 목소리 데이터 시간 duration_time ○ string 라이브 스트리밍 정보
(live streaming)라이브 스트리밍 플랫폼 정보 platform_info ○ string 라이브 스트리밍 주제 subject string 총 발화자 명수 total_speaker_num ○ string 발화자 이름 speaker_name ○ string 발화자 성별 speaker_gender ○ string 발화자 나이 그룹 speaker_age_group ○ string 라이브 스트리밍 장소 정보 location ○ string 총 영상 길이 total_video_time ○ string 총 발화 길이 total_voice_time ○ string 전사 (transcription) 전사 텍스트 text ○ string 번역 (translation) 번역 언어 trans_lang ○ string 번역 텍스트 trans_text ○ string 역번역 언어 back_trans_lang ○ string 역번역 텍스트 back_trans_text ○ string 특수 언어 표현
(special language expression)신조어 new_word string 축약어 abbreviation_word string 비속어 slang string 말실수 mistake string 재발화 again string 간투사 interjection string 환경 요소
(enviroment)실외 outside ○ string 실내 inside ○ string 오전 day ○ string 오후 night ○ string 표 1. 데이터 구성
- 어노테이션 명세
어노테이션 명세 주요 어노테이션 속성 속성 설명 비고 콘텐츠 정보
(contents)contentsidx 콘텐츠 아이디 source 라이브 스트리밍 출처 category 라이브 스트리밍 카테고리 solved_copyright 저작권 origin_lang 라이브 스트리밍 콘텐츠 언어 파일 정보
(file)source_filename 라이브 스트리밍 콘텐츠 원본 데이터 파일명 source_filepath 라이브 스트리밍 콘텐츠 원본 데이터 파일주소 sound_filename 라이브 스트리밍 콘텐츠의 음성 추출 데이터 파일명 sound_filepath 라이브 스트리밍 콘텐츠의 음성 추출 데이터 파일주소 start_voice_time 목소리 추출 데이터의 시작 시간 end_voice_time 목소리 추출 데이터의 종료 시간 duration_time 총 목소리 데이터 시간 라이브 스트리밍 정보
(live streaming)platform_info 라이브 스트리밍 플랫폼 정보 subject 라이브 스트리밍 주제 total_speaker_num 총 발화자 명수 speaker_name 발화자 이름 speaker_gender 발화자 성별 speaker_age_group 발화자 나이 그룹 location 라이브 스트리밍 장소 정보 total_video_time 총 영상 길이 total_voice_time 총 발화 길이 전사 (transcription) text 전사 텍스트 번역 (translation) trans_lang 번역 언어 trans_text 번역 텍스트 back_trans_lang 역번역 언어 back_trans_text 역번역 텍스트 특수 언어 표현
(special language expression)new_word 신조어 abbreviation_word 축약어 slang 비속어 mistake 말실수 again 재발화 interjection 간투사 환경 요소
(enviroment)outside 실외 inside 실내 day 오전 night 오후 표 2. 어노테이션 명세
- 원문데이터 포맷 예시
원문데이터 포맷 예시 제목 en_일상소통 155 화자 Jarrod Tocci 연령대 10-30대 미만 성별 남성 장소 실외 태그 원문 Okay. Popping these in the fridge. 전처리 후 좋아요. 이것들을 냉장고에 넣어두세요. 표 3. 원문데이터 포맷 예시
- 실제 예시
{
"contentsIdx":"4895",
"source":"유튜브",
"category":"여행_ko_ca2",
"solved_copyright":"플레이타운",
"origin_lang_type":"KO_TO_EN",
"origin_lang":"한국어",
"contentsName":"말라카 길거리 먹방 중 길잃고 날은 어두워지고",
"fi_source_filename":"말라카 길거리 먹방 중 길잃고 날은 어두워지고.mp4",
"fi_source_filepath":"/data/ai_contents/한국어_영어/말라카 길거리 먹방 중 길잃고 날은 어두워지고",
"li_platform_info":"플레이타운",
"li_subject":"한국",
"li_location":"말레이시아",
"fi_sound_filename":"4895_10279_28.76_30.59.wav",
"fi_sound_filepath":"https://objectstorage.ap-seoul-1.oraclecloud.com/n/cnb97trxvnun/b/clive-resource/o/output/한국어_영어/원천데이터/여행/4895/4895_10279_28.76_30.59.wav",
"li_total_video_time":"3077.85",
"li_total_voice_time":"2217.27",
"li_total_speaker_num":"2",
"fi_start_voice_time":"28.764995863576136",
"fi_end_voice_time":"30.585002876",
"fi_duration_time":"1.820007012423865",
"tc_text":"지금 늦었어요 말라카라 빨리 가야 돼.",
"tl_trans_lang":"영어",
"tl_trans_text":"It's late now, need to hurry to Malacca.",
"tl_back_trans_lang":"한국어",
"tl_back_trans_text":"이제 시간이 늦었으니 서둘러 말라카로 가세요.",
"speaker_tone":"[]",
"sl_new_word":[
],
"sl_abbreviation_word":[ ],
"sl_slang":[ ],
"sl_mistake":[ ],
"sl_again":[ ],
"sl_interjection":[ ],
"place":"INDOOR",
"en_outside":"X",
"en_insdie":"O",
"day_night":"NIGHT",
"en_day":"X",
"en_night":"O",
"speaker_name":"이경옥",
"speaker_gender_type":"WOMAN",
"speaker_gender":"여성",
"speaker_age_group_type":"THIRTIES_TO_FIFTIES",
"speaker_age_group":"30대-50대 미만“
}
-
데이터셋 구축 담당자
수행기관(주관) : 아키아카
수행기관(주관) 책임자명 전화번호 대표이메일 담당업무 정민혁 02-859-0884 mona@akiaka.com 사업관리총괄, 데이터 정제, AI모델 개발 수행기관(참여)
수행기관(참여) 기관명 담당업무 부산외국어대학교 산학협력단 품질관리 및 데이터 검사 이고에듀 데이터 정제 및 비식별화 이창용어학원 데이터 가공(라벨링) 및 역번역 인트리 원시데이터 수집 및 저작권 관리 데이터 관련 문의처
데이터 관련 문의처 담당자명 전화번호 이메일 정민혁 02-859-0884 mona@akiaka.com 이창규 070-5226-1346 lcg@akiaka.co.kr AI모델 관련 문의처
AI모델 관련 문의처 담당자명 전화번호 이메일 현화수 070-5226-1346 reina@akiaka.co.kr 양승준 070-5226-1346 black@akiaka.co.kr 저작도구 관련 문의처
저작도구 관련 문의처 담당자명 전화번호 이메일 이창규 070-5226-1346 lcg@akiaka.co.kr 김대니 070-5226-1346 kdn@akiaka.co.kr
-
인터넷과 물리적으로 분리된 온라인·오프라인 공간으로 의료 데이터를 포함하여 보안 조치가 요구되는 데이터를 다운로드 없이 접근하고 분석 가능
* 온라인 안심존 : 보안이 보장된 온라인 네트워크를 통해 집, 연구실, 사무실 등 어디서나 접속하여 데이터에 접근하고 분석
* 오프라인 안심존 : 추가적인 보안이 필요한 데이터를 대상으로 지정된 물리적 공간에서만 접속하여 데이터에 접근하고 분석 -
- AI 허브 접속
신청자 - 안심존
사용신청신청자신청서류 제출* - 심사구축기관
- 승인구축기관
- 데이터 분석 활용신청자
- 분석모델반출신청자
- AI 허브 접속
-
1. 기관생명윤리위원회(IRB) 심의 결과 통지서 [IRB 알아보기] [공용IRB 심의신청 가이드라인]
2. 기관생명윤리위원회(IRB) 승인된 연구계획서
3. 신청자 소속 증빙 서류 (재직증명서, 재학증명서, 근로계약서 등 택1)
4. 안심존 이용 신청서 [다운로드]
5. 보안서약서 [다운로드]
※ 상기 신청서 및 첨부 서류를 완비한 후 신청을 진행하셔야 정상적으로 절차가 이루어집니다. -
신청 및 이용관련 문의는 safezone1@aihub.kr 또는 02-525-7708, 7709로 문의
데이터셋 다운로드 승인이 완료 된 후 API 다운로드 서비스를 이용하실 수 있습니다.
API 다운로드 파일은 분할 압축되어 다운로드 됩니다. 분할 압축 해제를 위해서는 분할 압축 파일들의 병합이 필요하며 리눅스 명령어 사용이 필요합니다.
리눅스 OS 계열에서 다운로드 받으시길 권장하며 윈도우에서 파일 다운로드 시 wsl(리눅스용 윈도우 하위 시스템) 설치가 필요합니다.
※ 파일 병합 리눅스 명령어
find "폴더경로" -name "파일명.zip.part*" -print0 | sort -zt'.' -k2V | xargs -0 cat > "파일명.zip"
- 해당 명령어 실행 시, 실행 경로 위치에 병합 압축 파일이 생성됩니다.
- 병합된 파일 용량이 0일 경우, 제대로 병합이 되지 않은 상태이니 "폴더경로"가 제대로 입력되었는지 확인 부탁드립니다.
※ 데이터셋 소개 페이지에서 다운로드 버튼 클릭하여 승인이 필요합니다.
오프라인 데이터 이용 안내
본 데이터는 K-ICT 빅데이터센터에서도 이용하실 수 있습니다.
다양한 데이터(미개방 데이터 포함)를 분석할 수 있는 오프라인 분석공간을 제공하고 있습니다.
데이터 안심구역 이용절차 및 신청은 K-ICT빅데이터센터 홈페이지를 참고하시기 바랍니다.

국방데이터 개방 안내
본 데이터는 국방데이터로 군사 보안에 따라 AI허브에서 데이터를 제공하지 않으며,
군 담당자를 통한 별도의 사용 신청이 필요합니다.