한국인 얼굴 합성을 위한 발화 모습 이미지
- 분야영상이미지
- 유형 이미지
-
데이터 변경이력
데이터 변경이력 버전 일자 변경내용 비고 1.1 2023-12-27 데이터 최종 개방 1.0 2023-07-31 데이터 개방(Beta Version) 데이터 히스토리
데이터 히스토리 일자 변경내용 비고 2025-05-09 구축업체정보 수정 2024-02-27 산출물 전체 공개 소개
한국인 발화 모습 이미지와 다양한 표정, 포즈 등 관련 레이블 정보를 포함하여 자연스러운 한국인 얼굴 합성 모델을 학습하기 위한 데이터셋 구축 한국인 2,000명을 대상으로 수집되는 7종의 감정표정과 발화연기를 수행한 이미지 총 1,000,000장
구축목적
대규모 데이터셋임에도 불구하고 Auto labeling이 아닌 사람의 manual labeling방식을 활용한 모양의 통일성, 세부정보의 다양성, 데이터의 정확성을 만족시키는 데이터셋을 구축하고자 함
-
메타데이터 구조표 데이터 영역 영상이미지 데이터 유형 이미지 데이터 형식 영상 이미지 (.jpg) 데이터 출처 온/오프라인 크라우드 소싱 촬영 라벨링 유형 표정(이미지), 바운딩박스(좌표), 각도(이미지) 라벨링 형식 JSON 데이터 활용 서비스 가상인간 얼굴 생성 서비스, 3D 메타휴먼 및 아바타 합성 서비스 데이터 구축년도/
데이터 구축량2022년/1,000,000장 -
1. 데이터 구축 규모
데이터 구축 규모 Celeb-K 총 데이터셋 수량 1,011,675 장 ID 수 2,001 명 ID 당 라벨 수 14 종 ( 7종 표정 x 2종 얼굴각도) ID 당 평균 이미지 504 장 (36장 x 14종) 2. 데이터 분포
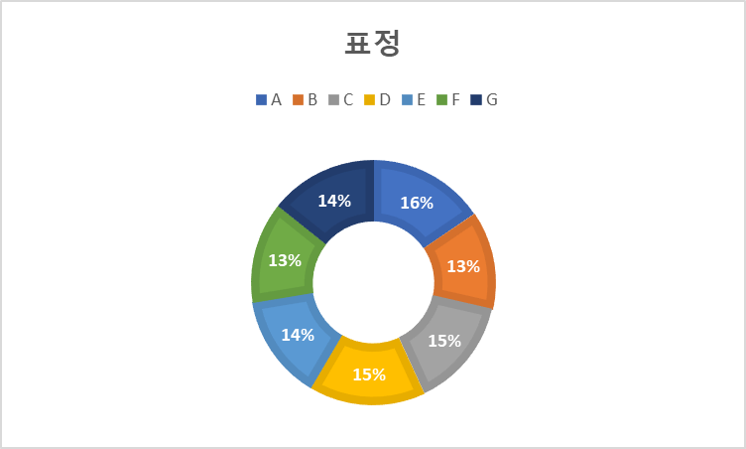
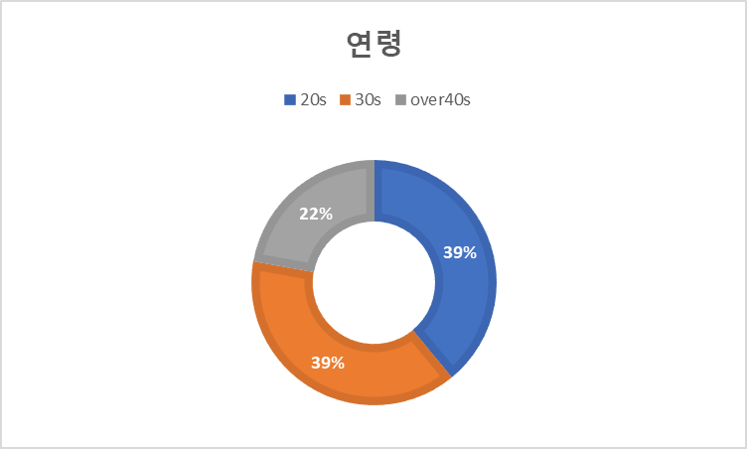
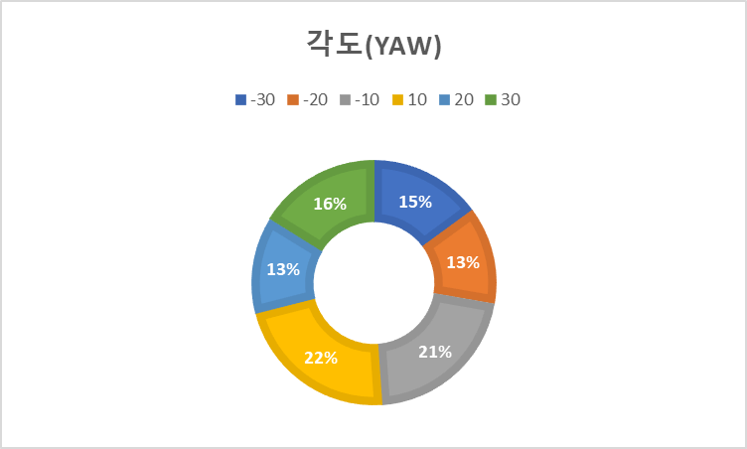
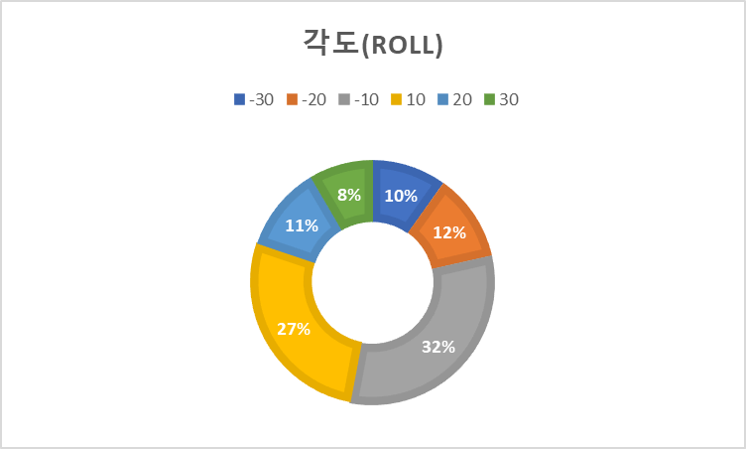
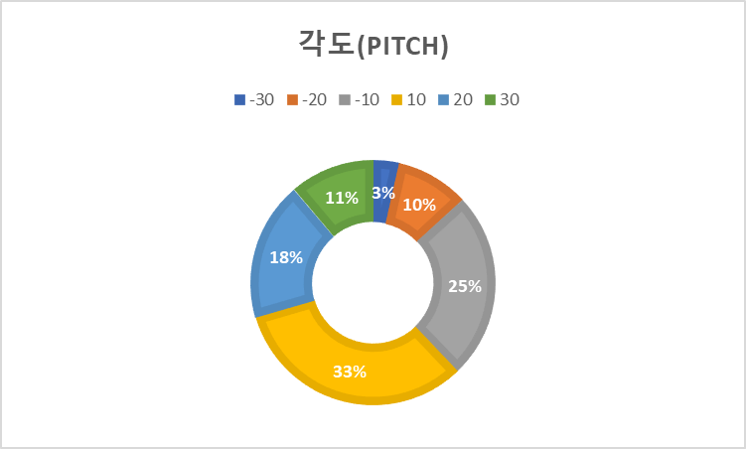
2. 데이터 분포 구분 여성 남성 성별 568,583 443,092 비중(%) 56.202 43.798 A B C D E F G 표정 157,048 132,056 147,295 155,872 140,830 135,280 144,266 비중(%) 15.705 13.206 14.73 15.587 14.083 13.528 14.426 20s 30s over40s 연령 394,928 392,163 224,584 비중(%) 37.759 38.764 22.199 -30 -20 -10 0 10 20 30 각도(yaw) 84,524 73,178 120,138 443,435 125,661 72,883 91,856 비중(%) 8.355 7.233 11.875 43.832 12.421 7.204 9.08 각도(roll) 40,327 47,341 128,638 603,270 111,150 46,381 34,568 비중(%) 3.986 4.679 12.715 59.631 10.987 4.585 3.417 각도(pitch) 22,675 61,640 159,584 367,773 210,094 117,803 72,106 비중(%) 2.241 6.093 15.774 36.353 20.767 11.644 7.127 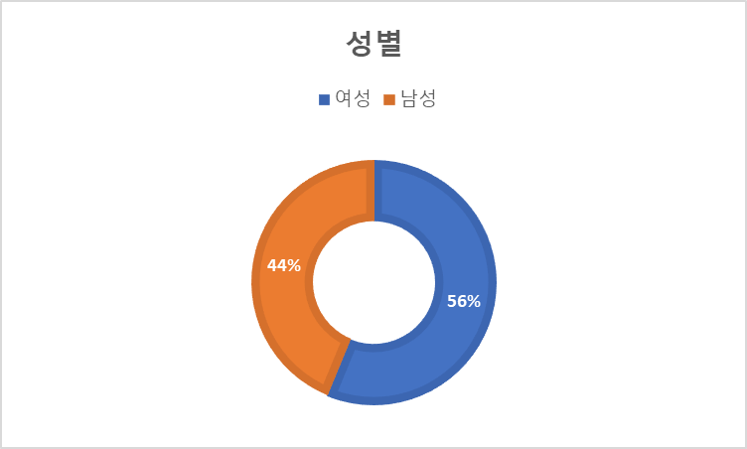
-
-
AI 모델 상세 설명서 다운로드
AI 모델 상세 설명서 다운로드 AI 모델 다운로드⦁일반적으로 다루는 분류모델, 검출모델, 검증모델의 경우 Train, Validation, Test data set으로 데이터를 구성하여 인공지능 모델을 학습, 검증, 실험을 수행함
⦁본 과제에서 다루는 모델은 생성모델로써, 별도의 validation, test date set을 필요로 하지않으며, 생성 이미지에 대한 절대적인 정답값이 없기 때문에 학습한 데이터와 유사분포를 가졌는지에 대한 상대적인 유효성만 확인할 수 있음.
⦁따라서, 생성모델을 학습하고 검증하기위한 데이터셋으로 Train data (80%), Test data (20%)로 구성함.데이터 명 한국인 얼굴 이미지 학습 모델 후보 알고리즘 성능지표 선정 사유 유효성 모델 StyleGAN 1 유효성 FID 14이하 유효성 모델 StyleGAN 2 유효성 FID 14이하 유효성 모델 DeceiveD 유효성 FID 14이하 학습데이터 규모 요구사항 및 학습 효율성 고려 조건부 유효성 모델 Conditional DeceiveD 유효성 FID 18이하 상동 ⦁Deceive-D 모델
- 합성 모델을 학습 시키기 위해서는 분포를 충분히 학습할 수 있는 많은 데이터를 요구함
- 현실적으로 막대한 양의 데이터들을 수집하기는 어렵고 제한적인 한계가 있음
- 데이터의 양이 너무 적어 과적합 상태에 도달하는 문제를 해결하기 위해서 Discriminator가 과적합 되지 않도록 가짜 데이터를 진짜 데이터라고 속이면서 학습 시키는 방식을 취하는 모델을 선택함
- StyleGAN2 모델에 대하여 제한된 양의 데이터로도 훌륭한 품질의 이미지를 생산이 가능함⦁총 데이터 1,012,647장 (100%)
- 학습데이터 (80%, 809,340장), 실험데이터 (20%, 202,335장)
- 학습모델 : DeceiveD, Conditional DeceiveD -
데이터 성능 점수
측정값 (%)기준값 (%)데이터 성능 지표
데이터 성능 지표 번호 측정항목 AI TASK 학습모델 지표명 기준값 점수 측정값 점수 1 얼굴 합성 유효성능 Image Synthesis Deceive-D FID 14 점 9.35 점 2 얼굴 조건부 표정 합성 유효성능 Image Synthesis Deceive-D FID 18 점 10.33 점 3 얼굴 조건부 성별 합성 유효성능 Image Synthesis Deceive-D FID 18 점 11.12 점 4 얼굴 조건부 각도 합성 유효성능 Image Synthesis Deceive-D FID 18 점 9.77 점
※ 데이터 성능 지표가 여러 개일 경우 각 항목을 클릭하면 해당 지표의 값이 그래프에 표기됩니다.
※ AI모델 평가 지표에 따라 측정값의 범위, 판단 기준이 달라질 수 있습니다. (ex. 오류율의 경우, 낮을수록 좋은 성능을 내는 것으로 평가됩니다)
-
설명서 및 활용가이드 다운로드
데이터 설명서 다운로드 구축활용가이드 다운로드데이터 설명 데이터 설명
데이터 명 한국인 얼굴 이미지 데이터 (Celeb-K) 활용 분야 얼굴 합성, 얼굴 생성 데이터 요약 얼굴 생성 모델 학습에 특화된 한국인 안면 데이터 한국인 2,000명을 대상으로 수집되는 7종의 감정표정과 발화연기를 수행한 이미지 총 1,000,000장 데이터 출처 서양인 얼굴 이미지 공개데이터셋 (Celeb-HQ) 참고 데이터 통계 데이터 구축 규모 이미지데이터 1,000,000 장, 메타데이터 1,000,000개 (1:1) 데이터 분포
(충분성, 균등성, 편향성 여부 확인)총 이미지 수 : 1,000,000 장 성별 : 여자 (56%), 남자 (44%) 표정 : 행복 (15.5%), 놀람 (13.0%), 무표정 (14.6%), 혐오 (15.4%), 분노 (13.9%), 두려움 (13.4%), 슬픔 (14.2%) 데이터 포맷 데이터 포맷 구분 No 속성명 속성 및 내용 필수 1 rawfile 원천데이터 필수 2 name 파일명 필수 3 date 수집날짜 필수 4 inst 촬영장비 필수 5 format 확장자 필수 6 size 해상도 필수 7 id 영상번호 필수 8 scr 스크립트 코드 필수 9 label_gt 정답라벨 필수 10 metadata 메타데이터 필수 11 gender 성별 필수 12 age 연령 필수 13 glasses 안경착용 필수 14 haircolor 머리색 필수 15 hairstyle 머리스타일 필수 16 exp 표정 필수 17 pose 각도 필수 18 box bounding box 선택 19 label_auto 유효성 라벨 선택 20 metadata 메타데이터 선택 21 gender 성별 선택 22 age 연령 선택 23 glasses 안경착용 선택 24 haircolor 머리색 선택 25 hairstyle 머리스타일 선택 26 exp 표정 선택 27 pose 각도 선택 28 box bounding box 데이터 포맷 및 예시 데이터 포맷 및 예시 구분 데이터 항목 항목 설명 Json형식 예시 rawfile name 파일명 

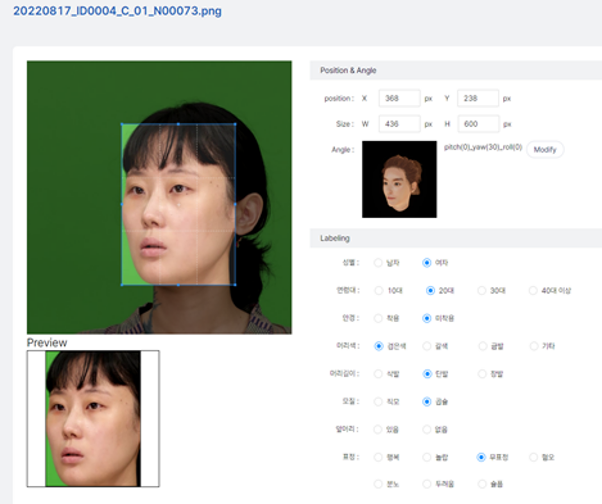
date 수집날짜 inst 촬영장비 format 확장자 size 해상도 w 가로너비 h 세로높이 id 영상번호 scr 스크립트 코드 metadata exp 행복(A), 놀람(B), 무표정(C), 혐오(D), 분노(E), 두려움(F), 슬품(G) pose 복합 (01). pitch(02), roll(03), yaw(04) metadata gender 남자(male). 여자(female) age 20대 이하 (20s), 30대(30s),40대 이상(over40s) glasses 착용(on), 미착용(off) haircolor 검정(black), 갈색(brown), 탈색(yellow), 그 외(others) hairstyle(length) 긴머리 (long), 짧은머리 (short), 대머리(bald) hairstyle(curl) 생머리(straight), 펌(curly) hairstyle(forehead) 유(true), 무(false) box(x,y,w,h) 좌측상단좌표(x,y), 너비높이(w,h) 0-1023 어노테이션 포맷 어노테이션 포맷 구분 속성명 타입 필수여부 설명 범위 비고 1 rawfile object Y 원천데이터 1-1 name string Y 파일명 1-2 date number Y 수집날짜 yyyymmdd 1-3 inst string Y 촬영장비 1-4 format string Y 확장자 png 1-5 size object Y 해상도 1-5-1 w number Y 가로너비 1-5-2 h number Y 세로높이 1-6 id number Y 영상번호 1-7 scr string Y 스크립트 코드 2 label_gt object Y 정답라벨 2-1 metadata object Y 메타데이터 2-1-1 gender string Y 성별 female, male 2-1-2 age string Y 연령 10s, 20s, 30s, over40s 2-1-3 glasses string Y 안경착용 on, off on: 착용 off: 미착용 2-1-4 haircolor string Y 머리색 black, brown, yellow, others 2-1-5 hairstyle object Y 머리스타일 2-1-5-1 length string Y 길이 bald, short, long 2-1-5-2 curl string Y 모질 curly, straight 2-1-5-3 forehead boolean Y 앞머리 true, false 2-2 exp string Y 표정 A~G 행복(A), 놀람(B), 무표정(C), 혐오(D), 분노(E), 두려움(F), 슬품(G) 2-3 pose object Y 각도 01~04 복함움직임(01), pitch(02), roll(03), yaw(04) 2-3-1 yaw number Y yaw축 기울기 -30 ~ +30 2-3-2 pitch number Y pitch축 기울기 -30 ~ +30 2-3-3 roll number Y roll축 기울기 -30 ~ +30 2-4 box object Y bounding box 2-4-1 x number Y 좌측상단 x좌표 0-1023 2-4-2 y number Y 좌측상단 y좌표 0-1023 2-4-3 w number Y 너비 0-1023 2-4-4 h number Y 높이 0-1023 3 label_auto object Y 자동라벨 3-1 metadata object Y 메타데이터 3-1-1 gender string Y 성별 female, male 3-1-2 age string Y 연령 10s, 20s, 30s, over40s 3-1-3 glasses string Y 안경착용 on, off on: 착용 off: 미착용 3-1-4 haircolor string Y 머리색 black, brown, yellow, others 3-1-5 hairstyle object Y 머리스타일 3-1-5-1 length string Y 길이 bald, short, long 3-1-5-2 curl string Y 모질 curly, straight 3-1-5-3 forehead boolean Y 앞머리 true, false 3-2 exp string Y 표정 A~G 행복(A), 놀람(B), 무표정(C), 혐오(D), 분노(E), 두려움(F), 슬품(G) 3-3 pose object Y 각도 01~04 복함움직임(01), pitch(02), roll(03), yaw(04) 3-3-1 yaw number Y yaw축 기울기 -30 ~ +30 3-3-2 pitch number Y pitch축 기울기 -30 ~ +30 3-3-3 roll number Y roll축 기울기 -30 ~ +30 3-4 box object Y bounding box 3-4-1 x number Y 좌측상단 x좌표 0-1023 3-4-2 y number Y 좌측상단 y좌표 0-1023 3-4-3 w number Y 너비 0-1023 3-4-4 h number Y 높이 0-1023 -
데이터셋 구축 담당자
수행기관(주관) : ㈜딥브레인 에이아이
수행기관(주관) 책임자명 전화번호 대표이메일 담당업무 서정현 02-858-5683 jared@deepbrain.io 사업 실무책임자/ 데이터 관리 총괄 / 데이터 전처리 및 학습 수행기관(참여)
수행기관(참여) 기관명 담당업무 테스트웍스 데이터 수집 데이터 관련 문의처
데이터 관련 문의처 담당자명 전화번호 이메일 서정현 02-858-5683 jared@deepbrain.io
-
인터넷과 물리적으로 분리된 온라인·오프라인 공간으로 의료 데이터를 포함하여 보안 조치가 요구되는 데이터를 다운로드 없이 접근하고 분석 가능
* 온라인 안심존 : 보안이 보장된 온라인 네트워크를 통해 집, 연구실, 사무실 등 어디서나 접속하여 데이터에 접근하고 분석
* 오프라인 안심존 : 추가적인 보안이 필요한 데이터를 대상으로 지정된 물리적 공간에서만 접속하여 데이터에 접근하고 분석 -
- AI 허브 접속
신청자 - 안심존
사용신청신청자신청서류 제출* - 심사구축기관
- 승인구축기관
- 데이터 분석 활용신청자
- 분석모델반출신청자
- AI 허브 접속
-
1. 기관생명윤리위원회(IRB) 심의 결과 통지서 [IRB 알아보기] [공용IRB 심의신청 가이드라인]
2. 기관생명윤리위원회(IRB) 승인된 연구계획서
3. 신청자 소속 증빙 서류 (재직증명서, 재학증명서, 근로계약서 등 택1)
4. 안심존 이용 신청서 [다운로드]
5. 보안서약서 [다운로드]
※ 상기 신청서 및 첨부 서류를 완비한 후 신청을 진행하셔야 정상적으로 절차가 이루어집니다. -
신청 및 이용관련 문의는 safezone1@aihub.kr 또는 02-525-7708, 7709로 문의
데이터셋 다운로드 승인이 완료 된 후 API 다운로드 서비스를 이용하실 수 있습니다.
API 다운로드 파일은 분할 압축되어 다운로드 됩니다. 분할 압축 해제를 위해서는 분할 압축 파일들의 병합이 필요하며 리눅스 명령어 사용이 필요합니다.
리눅스 OS 계열에서 다운로드 받으시길 권장하며 윈도우에서 파일 다운로드 시 wsl(리눅스용 윈도우 하위 시스템) 설치가 필요합니다.
※ 파일 병합 리눅스 명령어
find "폴더경로" -name "파일명.zip.part*" -print0 | sort -zt'.' -k2V | xargs -0 cat > "파일명.zip"
- 해당 명령어 실행 시, 실행 경로 위치에 병합 압축 파일이 생성됩니다.
- 병합된 파일 용량이 0일 경우, 제대로 병합이 되지 않은 상태이니 "폴더경로"가 제대로 입력되었는지 확인 부탁드립니다.
※ 데이터셋 소개 페이지에서 다운로드 버튼 클릭하여 승인이 필요합니다.
오프라인 데이터 이용 안내
본 데이터는 K-ICT 빅데이터센터에서도 이용하실 수 있습니다.
다양한 데이터(미개방 데이터 포함)를 분석할 수 있는 오프라인 분석공간을 제공하고 있습니다.
데이터 안심구역 이용절차 및 신청은 K-ICT빅데이터센터 홈페이지를 참고하시기 바랍니다.

국방데이터 개방 안내
본 데이터는 국방데이터로 군사 보안에 따라 AI허브에서 데이터를 제공하지 않으며,
군 담당자를 통한 별도의 사용 신청이 필요합니다.