-
데이터 변경이력
데이터 변경이력 버전 일자 변경내용 비고 1.0 2022-07-14 데이터 최초 개방 데이터 히스토리
데이터 히스토리 일자 변경내용 비고 2025-06-26 구축업체정보 수정 2022-10-21 신규 샘플데이터 개방 2022-07-14 콘텐츠 최초 등록 소개
주거 및 공용공간 내 CCTV 또는 보안 카메라로부터 입력되는 동영상에서 이상행동을 탐지하는 지능형 영상 인식 인공지능 의 학습 개발에 활용하기 위한 데이터셋
구축목적
거주지역 내 이상행동 탐지를 통해 거주 지역 내 범죄를 사전에 예방, 능동적 치안서비스 제공
-
메타데이터 구조표 데이터 영역 재난안전환경 데이터 유형 비디오 데이터 형식 mp4 데이터 출처 자체 수집 라벨링 유형 바운딩박스, 키포인트, 세그멘테이션 라벨링 형식 JSON 데이터 활용 서비스 범죄 예측 알고리즘을 통한 실시간 사회 안전정보 제공 서비스 데이터 구축년도/
데이터 구축량2021년/300시간 -
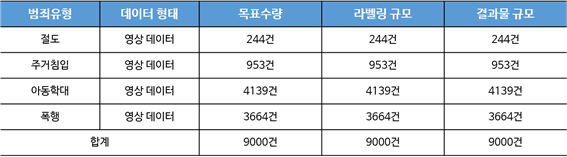
1. 데이터 구축 규모
- 영상 데이터 9000건 (절도 244건 ,주거침입 953건, 아동학대 4139건, 폭행 3664건)을 활용하여 총 9000건의 라벨링 데이터 도출
2. 데이터 분포
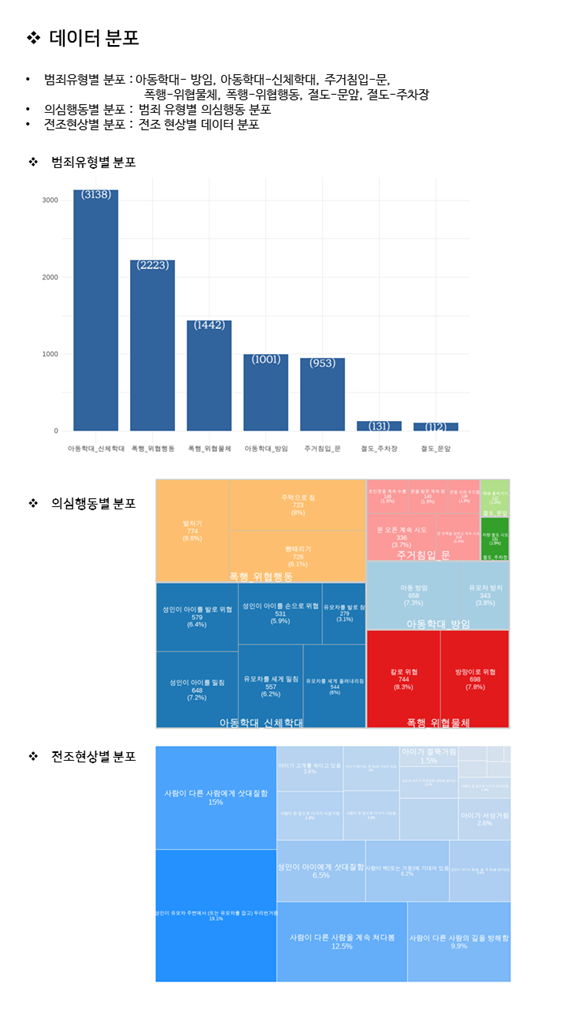
3. 행동의 분류3. 행동의 분류 행동 분류 설명 정상행동 의심행동 또는 전조현상이 아닌 일반적인 상황 또는 행동 전조현상 전조현상으로 정의된 SY1 ~ SY32에 해당하는 상황 또는 행동
단, 메인 전조현상이 있으면서 전조현상이 짧은(2초 이내) 경우, 라벨링을 생략하며,
동시에 두가지 이상의 전조현상이 뒤섞인 경우, 의심행동을 유발한 메인 전조현상을 전조현상으로 정의함.의심행동 이상행동으로 정의된 A1 ~ A31에 해당하는 상황 또는 행동 4. 행동간 구분 기준
- 구간 정보를 나누는 기준 : ‘전조 증상’과 ‘의심 행동’은 영상 파일 제목에 코드로 지정된 행동을 기준으로 하며, 해당 행동이 시작하려는 지점이 시작점
- 정상 행동은 전조 증상이 시작하기 전 혹은 사람이 화면 밖으로 벗어났을 때를 기준으로 전조 증상과 의심 행동으로 지정된 구간 외의 구간
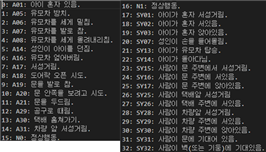
4. 행동간 구분 기준 symptom 전조 현상 action 의심 행동 SY01 아이가 서성거림 A01 아동 방임 SY02 아이가 고개를 숙이고 있음 A02 성인이 아이를 밀침 SY03 아이가 절뚝거림 A03 성인이 아이를 발로 위협 SY04 성인과 아이가 무관심한 상태로 걸어감 A04 성인이 아이를 손으로 위협 SY07 아이가 벽(기둥, 문 등)에 기대어 있음 A05 유모차 방치 SY08 성인의 무관심함과 아이가 성인의 몸(팔, 발, 옷 등)을 잡아당김 A06 유모차를 세게 밀침 SY09 성인이 아이에게 삿대질함 A07 유모차를 발로 참 SY10 성인이 아이의 몸(팔, 발, 옷 등)을 잡아당김 A08 유모차를 세게 올려내리침 SY13 성인이 유모차 주변에서
(또는 유모차를 잡고) 두리번거림A17 초인종을 계속 누름 SY15 사람이 문 앞으로 다가가 서성거림 A18 문 오픈 계속 시도 SY16 사람이 문 앞으로 다가가 서있음 A19 문을 발로 계속 참 SY17 사람이 문 앞으로 다가가 앉아있음 A20 문 안쪽을 보려고 계속 시도 SY21 사람이 다른 사람에게 삿대질함 A21 문을 오래 두드림 SY22 사람이 다른 사람을 계속 쳐다봄 A22 칼로 위협 SY23 사람이 다른 사람의 길을 방해함 A23 방망이로 위협 SY25 사람이 택배 앞으로 다가가 서성거림 A24 주먹으로 침 SY26 사람이 택배 앞으로 다가가 서있음 A25 뺨때리기 SY28 사람이 차량 앞으로 다가가 서성거림 A26 발차기 SY29 사람이 차량 주변으로 다가가 서있음 A30 택배 훔쳐가기 SY30 사람이 차량 주변으로 다가가 앉아있음 A31 차량 절도 시도 SY32 사람이 벽(또는 기둥)에 기대어 있음
5. 행동간 구분 예시
1) 정상행동 → 전조증상 → 의심행동- A03 [성인이 아이를 발로 참] SY08 [아이가 성인의 몸을 잡아당김]
![주거 및 공용 공간 내 이상행동 영상-행동간 구분 예시_1_A03 [성인이 아이를 발로 참] SY08 [아이가 성인의 몸을 잡아당김]](/web-nas/aihub21/files/editor/2022/06/5736158fcd1a4092b569748ce9e80b69.png)
- A24 [주먹으로 침] SY23 [사람이 다른 사람의 길을 방해함]
![주거 및 공용 공간 내 이상행동 영상-행동간 구분 예시_2_A24 [주먹으로 침] SY23 [사람이 다른 사람의 길을 방해함]](/web-nas/aihub21/files/editor/2022/06/c0fa5ae968354a68ba64a5eba84e1d1a.png)
2) 정상행동 → 전조증상 → 의심행동 → 정상행동
- A19 [문을 발로 참] SY16 [사람이 문 앞으로 다가가 서 있음]
![주거 및 공용 공간 내 이상행동 영상-행동간 구분 예시_3_A19 [문을 발로 참] SY16 [사람이 문 앞으로 다가가 서 있음]](/web-nas/aihub21/files/editor/2022/06/3318d945b62e457d84aecddf355aab4e.png)
3) 정상행동 → 의심행동
- A31 [차량 절도 시도] SY29 [사람이 차량 주변으로 다가가 서 있음]
![주거 및 공용 공간 내 이상행동 영상-행동간 구분 예시_4_A31 [차량 절도 시도] SY29 [사람이 차량 주변으로 다가가 서 있음]](/web-nas/aihub21/files/editor/2022/06/719a87053a7044d4a478bdd855b84872.png)
5. 전조현상과 의심행동 Mapping 기준
5. 전조현상과 의심행동 Mapping 기준 전조 현상 의심 행동 비고 SY01, SY02, SY03, SY07 A01 SY04, SY07, SY08, SY09, SY10 A02 SY02, SY07, SY08, SY09, SY10 A03 SY04, SY07, SY08, SY09, SY10 A04 SY13 A05 SY13 A06 SY13 A07 SY13 A08 SY15, SY16, SY17, SY32 A17 SY15, SY16, SY17, SY32 A18 SY15, SY16, SY17, SY32 A19 SY15, SY16, SY17, SY32 A20 SY15, SY16, SY17, SY32 A21 SY21, SY22, SY23 A22 SY21, SY22, SY23 A23 SY21, SY22, SY23, SY32 A24 SY21, SY22, SY23, SY32 A25 SY21, SY22, SY23, SY32 A26 SY25, SY26, SY32 A30 SY28, SY29, SY30, SY32 A31 - 영상 데이터 9000건 (절도 244건 ,주거침입 953건, 아동학대 4139건, 폭행 3664건)을 활용하여 총 9000건의 라벨링 데이터 도출
-
-
AI 모델 상세 설명서 다운로드
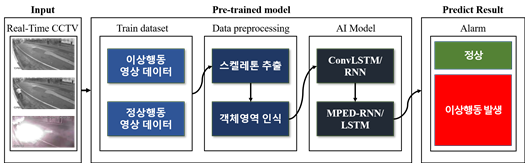
AI 모델 상세 설명서 다운로드 AI 모델 다운로드1. 개요
- 본 프로젝트에서는 각 9000개의 동영상 Dataset과 json Dataset을 사용
- 첫 번째 동영상 Dataset은 이상행동이 포함된 CCTV 영상
- 두 번째 Dataset은 JSON 형식의 데이터로 사람의 핵심 관절의 위치를 x, y 좌푯값으로 저장한 데이터
- 2가지의 Dataset을 효과적으로 사용하기 위해서 첫 번째 동영상 데이터를 사용하는 M1 Model과 JSON 형식의 데이터를 사용하는 M2 모델을 설계 및 개발하였으며, 추가로 M1 Model과 M2 Model의 결과값을 입력으로 받아 최종적으로 이상행동을 예측하는 M3 Model을 설계 및 개발
2. M1(영상 분석) Model
- M1 Model은 입력으로 들어온 동영상을 프레임단위로 이미지를 저장후, 저장된 이미지를 통해 해당 영상의 행동을 예측
- 예측은 한 클립 단위(Model의 한 클립의 길이는 16)
- 클립이 예측하는 방식: 0번 프레임부터 15번 프레임까지의 프레임들이 모아 첫 번째 Clip으로 통합, 통합된 첫 번째 Clip을 기반으로 전체 행동 중에서 가장 가능성이 큰 행동으로 유추
- 그 다음 첫 번째 clip에서 0번 Frame이 나가고 16번 Frame이 들어오게 되며 두번째 Clip됨. 첫 번째 Clip과 마찬가지로 1번 Frame 또한, 전체 행동 중 가장 유력한 행동을 예측하고, 이 과정을 클립에 마지막 Frame이 포함될 때까지 반복. 생성된 각 Clip별 행동 예측이 끝나면 전체 Clip 중 가장 많이 예측된 행동이 해당 영상에 대한 예측으로 선택
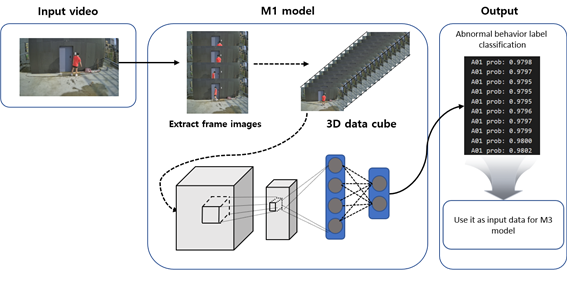
[M1모델 이상행동 분류 Process]
3. M2(스켈레톤 분석) Model
- M2모델의 경우 JSON데이터에서 인간의 관절좌표값(skeleton point)을 추출
- JSON데이터를 먼저 dictionary형태로 받아오고 조건문과 반복문을 통해 관절 좌표값을 추출
- 추출된 관절 좌표값은 bitmap 이미지로 바꾸기 위해서 검정색 이미지에 해당 관절좌표 위치를 하얀색으로 바꿈으로써 2차원 이미지를 추출
- 그리고 2차원 이미지가 M2모델에서 사용될 수 있도록 3차원의 이미지로 바꾸는 과정을 거쳐 전처리 과정이 완료
- M2모델의 특징은 동영상의 공간적 특징을 처리하기 위해 CNN구조(Convolutional Neural Network)를 사용
- CNN의 경우 이미지 분류(Image Classification)에서 강력한 성능을 보이기 때문에 위에서 전처리 된 이미지의 중요 feauture들을 추출하기 위해 사용
- 이렇게 CNN 구조에서 추출해낸 주요 feature들은 RNN 구조의 입력으로 들어가기 위해서 추가적인 전처리 과정을 거치게 되는데, Masking 방식을 사용
- Masking된 데이터를 GRU와 같은 반복 계층으로 구성된 Sequence 모델에 제공
- Sequence 모델을 사용하게 된다면 JSON데이터만으로 시간적 특성을 가질 수 있다는 장점이 존재
- 위와 같은 데이터 전처리 과정을 거쳐서 최종적으로 RNN구조로 들어가게 되고 RNN구조는 해당 JSON 데이터가 어떤 이상행동을 하는지 예측하며, 예측한 이상행동의 라벨값으로 결과값을 해당 이상행동의 라벨값이 반환
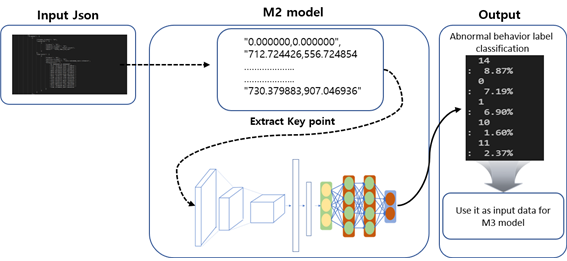
[M2모델 이상행동 분류 Process]
4. M3(영상+스켈레톤 통합 분석) Model
- M3의 모델의 경우 M1의 output과 M2의 output 그리고 실제 label값을 입력
- M3 모델에서 M1 , M2의 output 및 실제 label값을 입력으로 받음으로 최종적으로 해당 데이터(영상,JSON)의 이상행동의 예측 수행
- M3모델의 경우 직전 M1, M2모델의 경우와는 달리 validation data가 사용
- 우선적으로 전체데이터중 train data에 해당하는 M1의output, M2의 output, Label값을 표준화를 진행
- 표준화된 각각의 train data를 사용하여 GridCV방식으로 최고의 하이퍼 파라미터 값을 검색
- 이렇게 얻은 하이퍼 파라미터 값은 최종적으로 test data를 테스트 하는데 사용
- 테스트를 통해서 해당 데이터가 어떤 이상행동을 하는지 최종적으로 예측한 이상행동 라벨을 반환
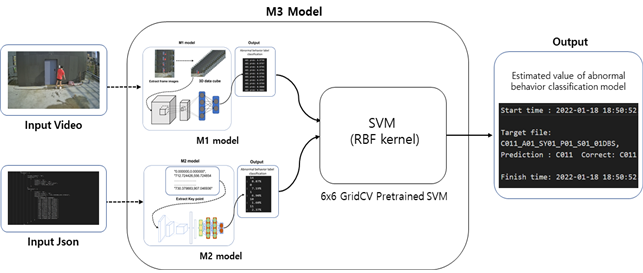
[M3모델 이상행동 분류 Process]
5. 영상 내 이상행동 탐지
- 학습
- AI 영상감시 분야의 이상행동 탐지(Anomaly Detecion) 과정 중 시공간적 특징을 잃지 않게 되는 3D Convolution Network를 포함하는 C3D 모델을 사용하여 이상행동의 전조부터 발생을 탐지한다. 탐지과정 중 영상을 16프레임의 조각으로 나누어 이상행동의 세부 분야를 구분하며 영상의 구간을 분석한다.
-
[검출을 위한 분류 카테고리]5. 영상 내 이상행동 탐지 검출을 위한 분류 카테고리 메인 분야 인덱스 세부 분야 인덱스 
-
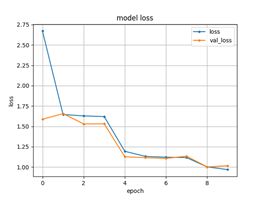
[메인 분야를 학습시킬 때 Epoch를 10으로 맞춘 모델 학습의 결과]5. 영상 내 이상행동 탐지 메인 분야를 학습시킬 때 Epoch를 10으로 맞춘 모델 학습의 결과 메인 분야 accuracy 세부 분야 loss 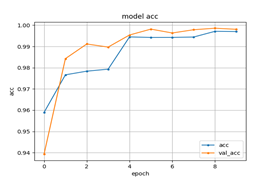
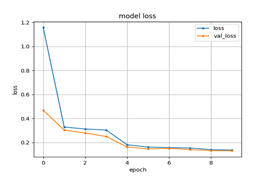
- Epoch가 10일 때, 정확도와 손실이 준수하게 나온다는 것을 확인할 수 있다.
-
[세부 분야 학습시킬 때에 Epoch를 10으로 맞춘 모델 학습의 결과]5. 영상 내 이상행동 탐지 세부 분야 학습시킬 때에 Epoch를 10으로 맞춘 모델 학습의 결과 메인 분야 accuracy 세부 분야 loss 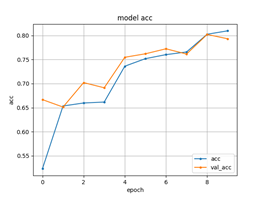
- 세부 분야 또한 Epoch가 10일 때 정확도와 손실이 준수하게 나온다는 것을 검증 결과를 통해서 확인할 수 있었다.
- 본 프로젝트에서는 각 9000개의 동영상 Dataset과 json Dataset을 사용
-
데이터 성능 점수
측정값 (%)기준값 (%)데이터 성능 지표
데이터 성능 지표 번호 측정항목 AI TASK 학습모델 지표명 기준값 점수 측정값 점수 1 Video Anomaly Detection 모델 Object Detection C3D, CNN_RNN, SVM Accuracy 80 % 88.51 %
※ 데이터 성능 지표가 여러 개일 경우 각 항목을 클릭하면 해당 지표의 값이 그래프에 표기됩니다.
※ AI모델 평가 지표에 따라 측정값의 범위, 판단 기준이 달라질 수 있습니다. (ex. 오류율의 경우, 낮을수록 좋은 성능을 내는 것으로 평가됩니다)
-
설명서 및 활용가이드 다운로드
데이터 설명서 다운로드 구축활용가이드 다운로드1. 소개
- 주거 및 공용공간 내 CCTV 또는 보안 카메라로부터 입력되는 동영상에서 이상행동을 탐지하는 지능형 영상 인식 인공지능 의 학습 개발에 활용하기 위한 데이터셋을 구축하고, 이를 활용하는 모델의 시범 개발
2. 원천데이터 예시

- 2분 길이의 영상데이터(.mp4)
3. 라벨링데이터 구성
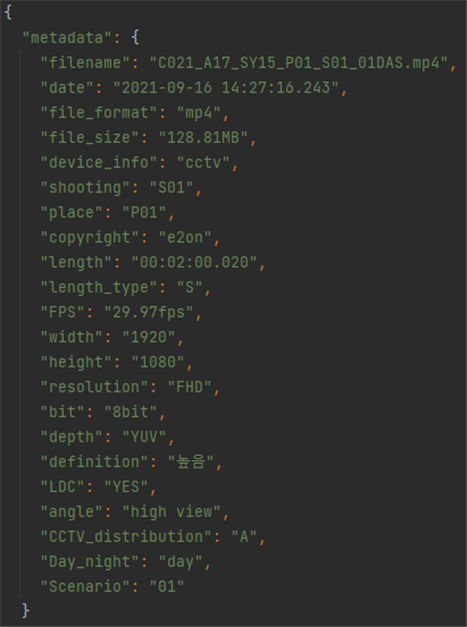
3. 라벨링데이터 구성 No 항목명 타입 필수
여부설명 범위 비고 1 metadata Object 데이터셋정보 2 filename String Y 파일명 3 date String Y 촬영날짜 4 file_format String Y 파일 형식 mp4 5 file_size String Y 파일 크기 6 device_info String Y 장비 정보 cctv 7 shooting String Y 촬영 번호 8 place String Y 촬영 장소 [P01~P10] P01:건물 출입구, P02:경비실,P03:엘리베이터 앞, P04:엘리베이터 안, P05:계단, P06:복도, P07:문 앞, P08:옥상, P09:주차장, P10:놀이터 9 copyright String Y 저작권 정보 e2on 10 length String Y 영상 길이 11 length_type String Y 길이 유형 S 12 FPS String Y 1초당 프레임 재생 속도 29.97fps, 30.00fps 13 width String Y 동영상 너비 1920 14 height String Y 동영상 높이 1080 15 resolution String Y 해상도 FHD 16 bit String Y 비트값 8bit 17 depth String Y 색공간 YUV 18 definition String Y 선명도 높음 19 LDC String Y 광각 보정 YES 20 angle String Y 촬영 각도 high view 21 CCTV_distribution String Y CCTV 배치 A, B 22 Day_night String Y 밤/낮 day, night 23 Scenario String Y 시나리오 번호 24 categories Object 유형정보 25 crime Object Y 범죄유형 정보 26 action Object Y 의심행동 정보 [A01~A31] 27 symptom Object Y 전조현상 정보 [SY01~SY32] 28 object Object Y 객체 정보 29 keypoints Object Y 키포인트 정보 30 file Object 라벨링정보 31 videos Object 구간 라벨링 정보 32 block_information Object 정보 블록 정보 33 block_index String Y 정보블럭 번호 [0~N] 34 block_type String Y 정보블럭 종류 [normal, symptom, action] 35 block_detail String Y 정보블럭 세부정보 [N1, A01~A31, SY01~SY32] normal은“N1”으로표기되며세부지침 없음 36 start_time String Y 시작시간 37 end_time String Y 끝 시간 38 start_frame_index String Y 시작 프레임 번호 39 end_frame_index String Y 끝 프레임 번호 40 num_persons String Y 사람 수 [0~N] 41 main_object String 메인 객체 종류 [Ob0~Ob5] 42 frames Object frame별 라벨링 정보 43 frame_index String Y 프레임 번호 [0~N] 44 objects Object 객체 라벨링 정보 45 index String 배열인덱스 [0~N] 46 object_index String 물체 구분 [0~5] 0:도어락, 1:택배, 2:유모차(아이 탑승), 3:야구배트, 4:칼, 5:자동차 47 object_name String 객체 이름 48 bbox String x, y, width, height 49 persons Object 사람 라벨링 정보 50 index String 배열인덱스 [0~N] 51 person_index String 사람 구분 [0~N] 52 person_center String keypoint 중심점 53 keypoints Array
(String)Keypoints 좌표
4. 라벨링데이터 실제예시
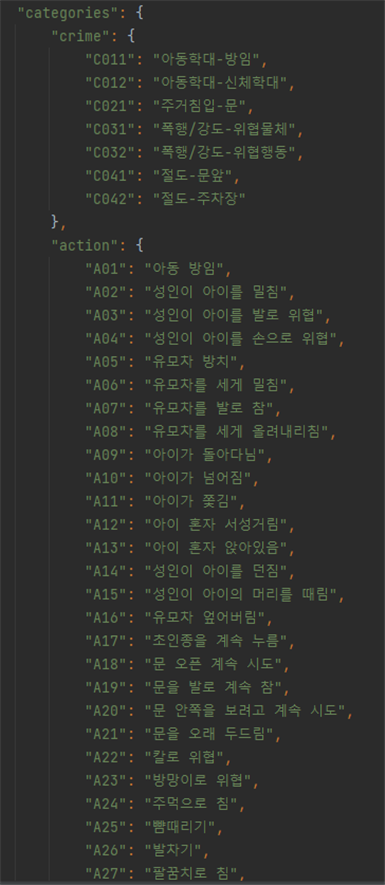
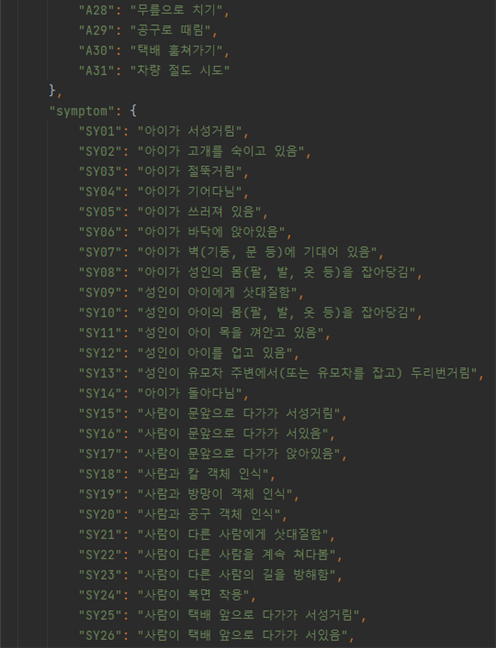
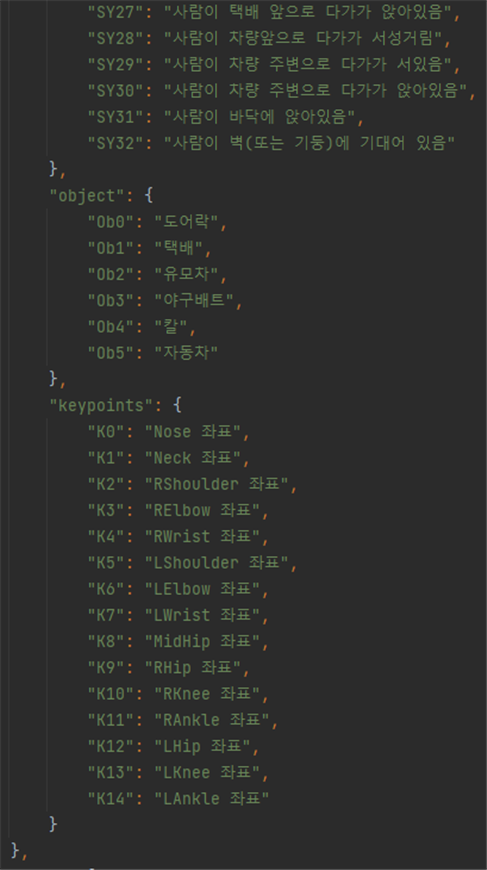
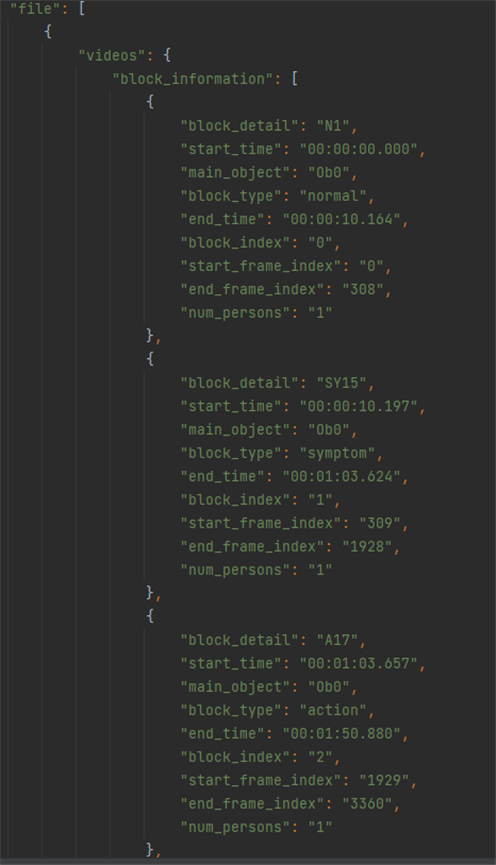
- 주거 및 공용공간 내 CCTV 또는 보안 카메라로부터 입력되는 동영상에서 이상행동을 탐지하는 지능형 영상 인식 인공지능 의 학습 개발에 활용하기 위한 데이터셋을 구축하고, 이를 활용하는 모델의 시범 개발
-
데이터셋 구축 담당자
수행기관(주관) : ㈜이투온
수행기관(주관) 책임자명 전화번호 대표이메일 담당업무 경일구 02-516-1371 edteson@e2on.com · 총괄 수행기관(참여)
수행기관(참여) 기관명 담당업무 동국대 산학협력단 · 업무정의
· AI모델㈜맥스테드 · 제작도구 푸른나무재단 · 클라우드 소싱
-
인터넷과 물리적으로 분리된 온라인·오프라인 공간으로 의료 데이터를 포함하여 보안 조치가 요구되는 데이터를 다운로드 없이 접근하고 분석 가능
* 온라인 안심존 : 보안이 보장된 온라인 네트워크를 통해 집, 연구실, 사무실 등 어디서나 접속하여 데이터에 접근하고 분석
* 오프라인 안심존 : 추가적인 보안이 필요한 데이터를 대상으로 지정된 물리적 공간에서만 접속하여 데이터에 접근하고 분석 -
- AI 허브 접속
신청자 - 안심존
사용신청신청자신청서류 제출* - 심사구축기관
- 승인구축기관
- 데이터 분석 활용신청자
- 분석모델반출신청자
- AI 허브 접속
-
1. 기관생명윤리위원회(IRB) 심의 결과 통지서 [IRB 알아보기] [공용IRB 심의신청 가이드라인]
2. 기관생명윤리위원회(IRB) 승인된 연구계획서
3. 신청자 소속 증빙 서류 (재직증명서, 재학증명서, 근로계약서 등 택1)
4. 안심존 이용 신청서 [다운로드]
5. 보안서약서 [다운로드]
※ 상기 신청서 및 첨부 서류를 완비한 후 신청을 진행하셔야 정상적으로 절차가 이루어집니다. -
신청 및 이용관련 문의는 safezone1@aihub.kr 또는 02-525-7708, 7709로 문의
데이터셋 다운로드 승인이 완료 된 후 API 다운로드 서비스를 이용하실 수 있습니다.
API 다운로드 파일은 분할 압축되어 다운로드 됩니다. 분할 압축 해제를 위해서는 분할 압축 파일들의 병합이 필요하며 리눅스 명령어 사용이 필요합니다.
리눅스 OS 계열에서 다운로드 받으시길 권장하며 윈도우에서 파일 다운로드 시 wsl(리눅스용 윈도우 하위 시스템) 설치가 필요합니다.
※ 파일 병합 리눅스 명령어
find "폴더경로" -name "파일명.zip.part*" -print0 | sort -zt'.' -k2V | xargs -0 cat > "파일명.zip"
- 해당 명령어 실행 시, 실행 경로 위치에 병합 압축 파일이 생성됩니다.
- 병합된 파일 용량이 0일 경우, 제대로 병합이 되지 않은 상태이니 "폴더경로"가 제대로 입력되었는지 확인 부탁드립니다.
※ 데이터셋 소개 페이지에서 다운로드 버튼 클릭하여 승인이 필요합니다.
오프라인 데이터 이용 안내
본 데이터는 K-ICT 빅데이터센터에서도 이용하실 수 있습니다.
다양한 데이터(미개방 데이터 포함)를 분석할 수 있는 오프라인 분석공간을 제공하고 있습니다.
데이터 안심구역 이용절차 및 신청은 K-ICT빅데이터센터 홈페이지를 참고하시기 바랍니다.

국방데이터 개방 안내
본 데이터는 국방데이터로 군사 보안에 따라 AI허브에서 데이터를 제공하지 않으며,
군 담당자를 통한 별도의 사용 신청이 필요합니다.