-
데이터 변경이력
데이터 변경이력 버전 일자 변경내용 비고 1.1 2023-11-10 데이터 최종 개방 1.0 2023-07-26 데이터 개방(Beta Version) 데이터 히스토리
데이터 히스토리 일자 변경내용 비고 2024-01-17 산출물 전체 공개 소개
ㅇ 문장 유형(추론, 예측 등) 판단 데이터 16만 5천 문장 이상 구축 ㅇ 역사, 사회, 금융, 문화, IT·과학, 생활·건강 카테고리에 해당하는 원시데이터를 수집·정제, 라벨링하여 인공지능 기술 개발에 필요한 학습용 문장 유형 데이터셋 구축 ⋅ 문장 유형 판단 라벨링으로 확실성, 시간성, 긍정/부정 극성 별로 스타일 태그 라벨링 ⋅ 최고의 전문기업들과의 협업을 통해 문장 유형 판단 학습용 데이터를 안정적으로 구축
구축목적
- 유형을 인공지능이 학습하여 모형화하고 자동화를 통한 판단을 통해 학습 데이터 구축 문장을 유형별로 라벨링을 하고 이를 통해 인공지능이 자연스러운 문장을 구사할 수 있도록 지원하는 것이 구축 목적 인공지능 학습용 데이터 구축에 따라 자연어 정보 문장 데이터 스트리밍, - - 다운로드 관련 부가서비스 개발, 문장 데이터를 활용한 새로운 뉴스 합성 엔진 개발 등에 활용 기대
-
메타데이터 구조표 데이터 영역 한국어 데이터 유형 텍스트 데이터 형식 json, csv, txt 데이터 출처 뉴스, 매거진, 도서, 블로그, 방송대본 라벨링 유형 내용요약(자연어) 라벨링 형식 JSON 데이터 활용 서비스 문장이해, 문장판단, 문장분류, 예측 및 추론 그리고 사실성 확실성 검증 데이터 구축년도/
데이터 구축량2022년/165,000개 문장 -
라벨링 데이터 정보
● 매체별 분포라벨링 데이터 정보● 매체별 분포 매체 문서 수 비율 뉴스 4,641 46.31% 매거진 1,628 16.24% 블로그 1,601 15.97% 방송대본 1,427 14.24% 도서 724 7.22% 합계 10,021 100% ● 카테고리별 분포
라벨링 데이터 정보● 카테고리별 분포 카테고리 문서 수 비율 사회 3,313 33.06% 생활건강 2,424 24.18% IT과학 1,605 16.01% 금융 1,215 12.12% 역사 834 8.32% 문화 630 6.28% 합계 10,021 100% ● 생성 기간 분포(항목 1,000개 이상으로 파일 별도 첨부)
라벨링 데이터 정보● 생성 기간 분포 생성 연도 문서 수 비율 51 0.51 2007 67 0.67 2008 421 4.2 2009 301 3 2010 899 8.97 2011 420 4.19 2012 248 2.47 2013 360 3.59 2015 55 0.55 2016 325 3.24 2017 547 5.46 2018 386 3.85 2019 956 9.54 2020 1,588 15.85 2021 867 8.65 2022 2530 25.26 합계 10021 100 ● 문장 길이 분포(어절수)
라벨링 데이터 정보● 문장 길이 분포(어절수) 어절수 구간 문장 수 1어절 이상 1,419 3어절 미만 3어절 이상 8,859 5어절 미만 5어절 이상 51,229 10어절 미만 10어절 이상 99,772 30어절 미만 30어절 이상 4,748 50어절 미만 50어절 이상 309 100어절 미만 100어절 이상 3 계 166,339 ● 문장 유형별 극성 분포
라벨링 데이터 정보● 문장 유형별 극성 분포 라벨 극성 수량 비율 핵심동사 긍정 133,045 79.99% 미정 16660 10.00% 부정 16634 10.01% 합계 ● 문장 유형별 확실성 분포
라벨링 데이터 정보● 문장 유형별 확실성 분포 라벨 확실성 수량 비율 핵심동사 확실 144,817 87.06% 불확실 21,522 12.93% 합계 166,339 100% ● 문장 유형별 시제 분포
라벨링 데이터 정보● 문장 유형별 시제 분포 라벨 시제 수량 비율 핵심동사 현재 93,375 56.13% 과거 46,199 27.77% 미래 26,765 16.09% 합계 166,339 100% ● 극성 구성별 분류 분포
라벨링 데이터 정보● 극성 구성별 분류 분포 극성 수량 비율 긍정 133,045 79.98% 미정 16,660 10.02% 부정 16,634 10.00% 합계 166,339 100% ● 문장 유형별 분포
라벨링 데이터 정보● 문장 유형별 분포 구분 문장 수 비율 사실형 66,382 39.90% 추론형 44,188 26.56% 대화형 43,945 26.41% 예측형 11,824 7.10% 합계 166,339 100% 데이터 통계
1)데이터 구축 규모
ㅇ 뉴스(5만4천 건), 매거진(5만4천 건), 도서(3만6천 건), 블로그(1만8천 건), 방송 대본(1만8천 건) 등 대표적인 5개 매체에서 역사, 사회, 금융, 문화, IT·과학, 생활·건강 등 다양한 카테고리별로 기승전결 흐름으로 문서의 완결성을 갖춘 1만건 이상 문서가 포함된 문장 유형(추론, 예측 등) 판단 데이터 16만 5천 문장 구축
ㅇ 역사(16.7%), 사회(16.7%), 금융(16.7%), 문화(16.7%), IT·과학(16.7%), 생활·건강(16.7%) 카테고리에 해당하는 원시데이터를 수집·정제, 라벨링하여 인공지능 기술 개발에 필요한 학습용 문장 유형 데이터셋 구축
- 문장 유형 판단 라벨링으로 확실성, 시간성, 긍정/부정 극성 별로 스타일 태그 라벨링
- 최고의 전문기업들과의 협업을 통해 문장 유형 판단 학습용 데이터를 안정적으로 구축1) 문장 유형
데이터 통계 1) 문장 유형 구분 내용 사실형 한 개인으로서 학설이나 생각, 신문/잡지 등에서 글쓴이의 주장을 펼치는 문장 어떤 사안에 대해 한 개인 혹은 조직의 주관적 의견이 반영된 문장 추론형 이미 알고 있는 혹은 확인된 정보로부터 논리적 결론을 도출하는 문장 어떠한 판단을 근거로 삼아 다른 판단을 이끌어 내는 내용이 있는 문장 예측형 과거의 데이터를 기반으로 미래에 대해 설명하거나 결과에 대한 평가된 예상치가 포함된 문장 대화형 둘 이상의 개인 혹은 조직 간의 상호적인 의사소통의 문장 2) 문장 속성
ㅇ 확실성
- 확실 (출처 확실, 문맥상 사건 발생, 화자 확실 단언)
- 불확실 (출처 불명, 예측, 문맥상 사건 미발생, 가능성만 있고 불확실, 조건절 상정)
ㅇ 시제
- 과거 (사건이 과거에 일어났음)
- 현재 (사건이 현재 일어남)
- 미래 (사건이 미래에 일어날 것임)
ㅇ 극성
- 긍정 (문맥상 사건 발생, 사실로 밝혀짐, 사건성립, 예측 성립 후 사건 발생, 사태 성립, 조건부 사건 성립)
- 부정 (문맥상 사건 미발생, 문장 문맥상 거짓으로 밝혀짐, 예측 성립 후 사건 미발생, 의미상 사건 미발생)
- 미정 (진행 중 조사 중, 문맥상 미정, 문맥상 참 / 거짓 불명확)
2) 데이터 분포데이터 통계 2) 데이터 분포 특성 항목명 측정 지표 정량 목표 지표 및 목표 설정 근거 다양성
(통계)매체별 분포 구성비 분포 확인 - 기승전결이 포함된 완결한 문서를 기준으로 수집하고, 각 매체/카테고리별 구성비를 기준으로 원시 데이터 획득 - 다양성 요건 항목의 조건 충족을 위해 가공 과정에서 나타나는 매체/카테고리별 유형 구성 비율에 따라 수집 세부 비율 조정 - 문서 수집 매체별 수집 목표를 맞추기 위한 분포 확인(블로그, 뉴스, 도서 등) 카테고리 분포 구성비 분포 확인 - 문서 카테고리별 수집 목표를 맞추기 위한 분포 확인 (IT/과학, 문화, 금융 등) 생성 기간 분포 구성비 분포 확인 - 라벨링 데이터의 pubdate 항목을 기준으로 한 기간 분포 문장 길이 분포 구성비 분포 확인 - 데이터의 문장 길이(length) 문장 유형별 구성비 분포 확인 - 각 문장 유형별 해당 문장의 극성 통계 분포 확인 극성 분포 문장 유형별 확실성 분포 구성비 분포 확인 - 각 문장 유형별 해당 문장의 확실성 통계 분포 확인 문장 유형별 구성비 분포 확인 - 각 문장 유형별 해당 문장의 시제 통계 분포 확인 시제 분포 다양성
(요건)문장 유형별 분류 구성비 구성비 중첩률 TBD - 데이터 구축 목적에 맞게 연구 및 산업 분야의 실질적인 원천을 제공하기 위해 카테고리 구성 목표 구성비(단위:문장) 구분 비율 수량 사실형 40% 66,000 추론형 15-25% 24,750 -41,250 예측형 5-15% 8,250 -24,750 대화형 10-30% 16,500 -49,500 계 100% 165,000 * 5~50개의 문장을 포함한 1만개 이상의 문서 극성 구성별
분류 분포구성비
중첩률구성비 중첩률 TBD 목표 구성비 긍정 80% 부정 10% 미정 10% -
-
AI 모델 상세 설명서 다운로드
AI 모델 상세 설명서 다운로드 AI 모델 다운로드→ 활용 분야 및 향후 계획
① 활용 분야
ㅇ 언어를 활용한 새로운 사업창출
ㅇ 산업지능화 경진대회 및 인공지능 테스트베드 진행
- 전국의 (전통)산업에 인공지능 도입을 위한 수요를 발굴하고, 인공지능 기술회사에는 첨단 기술을 접목시킬 수 있는 시장수요를 제공하는 사업을 추진하여 산업지능화 창출 플랫폼 안착 (기업 수요발굴 → 경진대회 진행 → 워크숍 → 인공지능 테스트베드 진행 → 사업화)
- 산업지능화 경진대회와 인공지능 테스트베드를 활용하여 빅데이터 및 인공지능 분야 창업플랫폼 실현가능성, 수요공급 균형성, 홍보성, 효과성, 협업 프로세스 정립, 민간 수요에 대한 검증을 위한 대회 시행
- 인공지능 기술회사(공급기업)간 협업을 통해 수요기업이 필요로 하는 문제들에 대해서 솔루션을 제공하고 나아가 새로운 비즈니스 모델을 창출
- 비즈니스 모델의 고도화를 위한 지속적 멘토링 및 사업화 자금 지원
② 향후 계획
ㅇ 본 사업의 홍보 및 확산
ㅇ 데이터 활용 (말 바꾸기)
- 데이터 분석 및 서비스 제공에 필요한 기능을 Fast-track으로 제공할 수 있는 효율적인 데이터 진단 및 분석의 선순환 구조 체계 구축
- 효과적인 데이터 활용을 위해서 기업과 대학, 기관으로부터 얻을 수 있는 아이디어가 가장 중요하고 대부분은 빅데이터+인공지능으로 실현, 개선 가능
- 전국 대학생, 출연연 연구원, 기업 등을 참여시켜 해커톤을 진행하고 이를 통해 새로운 비즈니스 모델 창출 및 데이터를 활용한 사회공헌(ESG) 솔루션 제공
- 지속된 분야별 데이터분석 과제수행 및 협업 활동을 통해서 데이터 활용 문화 확산 및 현업 아이디어 발굴
- 성균관대학교와 매일경제과 주최하는 경진대회를 통해 데이터 분석 전문가 Pool을 확보하고 분야별 전문 인적 네트워크를 구성하여 전통산업 및 미래혁신 산업에 적용하여 경쟁력 강화, New Biz 창출* 구축/공개될 데이터셋 활용 분야 및 서비스, 향후 유지보수 및 고도화 계획 기술
-
데이터 성능 점수
측정값 (%)기준값 (%)데이터 성능 지표
데이터 성능 지표 번호 측정항목 AI TASK 학습모델 지표명 기준값 점수 측정값 점수 1 문장 유형 분류 정확도 Text Classification BERT F1-Score 0.85 점 0.85 점 2 극성 분류 정확도 Text Classification BERT F1-Score 0.85 점 0.92 점 3 확실성 분류 정확도 Text Classification BERT F1-Score 0.74 점 0.94 점
※ 데이터 성능 지표가 여러 개일 경우 각 항목을 클릭하면 해당 지표의 값이 그래프에 표기됩니다.
※ AI모델 평가 지표에 따라 측정값의 범위, 판단 기준이 달라질 수 있습니다. (ex. 오류율의 경우, 낮을수록 좋은 성능을 내는 것으로 평가됩니다)
-
설명서 및 활용가이드 다운로드
데이터 설명서 다운로드 구축활용가이드 다운로드1. 데이터 정보 요약
데이터 명 문장 유형(예측, 추론 등) 판단 데이터 문장 유형 판단을 위한 텍스트 데이터 문장 속성 텍스트 데이터 활용 분야 가짜 뉴스 탐지 / 콘텐츠 / 마케팅 및 작문 평가 등 관련 산업 및 학계 서비스 데이터 요약 ◦ 뉴스, 매거진, 도서, 블로그 방송 대본 등 대표적인 5개 매체에서 역사, 사회, 금융, 문화, IT·과학, 생활·건강 카테고리별로 원시데이터를 수집·정제, 라벨링하여 인공지능 기술 개발에 필요한 학습용 문장 유형 데이터셋 구축 ◦ 다양한 한국어 원문데이터로부터 정제된 추출 및 문장 유형(대화형, 예측형, 추론형, 대화형) 및 문장의 속성(확실성/ 극성/ 시제) 판단 정보가 태깅된 문장 유형 판단 데이터셋 문장 유형 판단을 목적으로 문장 유형이 사실형, 추론형, 예측형. 대화형인지에 대한 정보가 문장 단위로 라벨링 된 텍스트 데이터 문장 속성 판단을 목적으로 속성 범주가 확실성/ 시제/ 극성에 관한 태깅 정보가 라벨링 된 텍스트 데이터 데이터 출처 ◦ 뉴스(5만4천 건), 매거진(5만4천 건), 도서(3만6천 건), 블로그(1만8천 건), 방송 대본(1만8천 건) 등 대표적인 5개 매체에서 역사, 사회, 금융, 문화, IT·과학, 생활·건강 등 다양한 카테고리별로 기승전결 흐름으로 문서의 완결성을 갖춘 18만개 문장이 포함된 1만건 이상 문건을 원시데이터로 수집 데이터 통계 데이터 구축 규모 다양한 한국어 문장에서 기승전결 흐름으로 문서의 완결성을 갖춘 1만건 이상 문건이 포함된 165,000 문장 구축 데이터 분포 매체별 분포: 뉴스(30%), 매거진(30%), 도서(20%), 블로그(10%), 방송 대본(10%) 카테고리별 분포: 역사(16.7%), 사회(16.7%), 금융(16.7%), 문화(16.7%), IT·과학(16.7%), 생활·건강(16.7%) 데이터 이력 배포 버전 v1.0 개정 이력 신규 작성자/배포자 수행기관(차현주) 2. 데이터 포맷(txt)
2. 데이터 포맷(txt) 구분 No 속성명 타입 속성 및 내용 필수 1 ID/FILENAME string 파일명 필수 2 MEDIA_TYPE string 수집 구분 ① 뉴스 ② 도서 ③ 매거진 ④ 블로그 ⑤ 방송대본 필수 3 MEDIA_NAME string 수집 구분 출처 ① 매일경제신문 ② 매일방송 ③ 매경출판 ④ 컴북스 ⑤ 블로그 필수 4 CATEGORY string 카테고리 ① 역사 ② 사회 ③ 금융 ④ 문화 ⑤ IT·과학 ⑥ 생활·건강 필수 5 PUBDATE string 문서 발행일 필수 6 SENTENCE string 문서 내 문장 갯수 필수 7 length number 1~무한대 필수 8 label string 문장 유형 ① 사실형 ② 추론형 ③ 예측형 ④ 대화형 ⑤ 핵심동사 필수 9 text string 문장 내용 or 동사 필수 10 text_id string 11 word_num number 12 key_word string 필수 13 확실성 string Certainty 여부 ① 확실 ② 불확실 필수 14 시제 string 시제 판단 ① 과거 ② 현재 ③ 미래 필수 15 극성 string Polarity 여부 ① 긍정 ② 부정 ③ 미정 3. 어노테이션 포맷(json)
3. 어노테이션 포맷(json) 구분 항목명 타입 필수 설명 범위 비고 여부 1 metaData 1.1 ID string Y 1.2 FILENAME string Y (예) {ID}.json 1.3 MEDIA_TYPE string Y 수집 구분 ① 뉴스, ② 도서, ③ 매거진, ④ 블로그 ⑤ 방송대본 1.4 MEDIA_NAME string Y 수집 구분 출처 ① 매일경제신문 ② 매일방송 ③ 매경출판 ④ 컴북스 ⑤ 블로그 1.5 CATEGORY string Y 카테고리 ① 역사 ② 사회 ③ 금융 ④ 문화 ⑤ IT·과학 ⑥ 생활·건강 1.6 PUBDATE string Y 문서 발행일 (예) 20221109 1.7 SENTENCE string Y 문서 내, 문장 개수 2 annotations 2.1 object 2.1.1 CharNum string Y 태깅 시작 위치 1~무한대 2.1.2 length number Y 문장길이 1~무한대 2.1.3 label string Y 문장 유형 ① 사실형 ② 추론형 ③ 예측형 ④ 대화형 ⑤ 핵심동사 2.1.4 text string Y 문장 내용 or 동사 - label값이 사실형~대화형이면 문장내용, label값이 핵심동사이면 동사 2.1.5 value 문장/핵심동사 세부 속성 2.1.5.1 text_id string Y 문장 번호 1~무한대 문장 – 핵심동사 매핑 정보 2.1.5.2 word_num number N 문장 구성 어절수 2~무한대 (문장 유형일 경우 태깅) 2.1.5.3 key_word srting N 핵심어절 (핵심동사일 경우 태깅) 2.1.5.4 확실성 string Y Certainty 여부 (핵심동사일 경우 태깅) ① 확실 ② 불확실 2.1.5.5 시제 string Y 시점 판단 (핵심동사일 경우 태깅) ① 과거 ② 현재 ③ 미래 2.1.5.6 극성 string Y Polarity 여부 (핵심동사일 경우 태깅) ① 긍정 ② 부정 ③ 미정 4. 데이터 구성
4. 데이터 구성 폴더 구조 명칭 원천 데이터 (메타 + Text) 라벨링 데이터 (JSON) 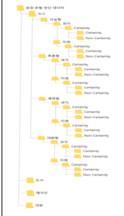



-
데이터셋 구축 담당자
수행기관(주관) : 성균관대 산학협력단
수행기관(주관) 책임자명 전화번호 대표이메일 담당업무 권상희 02-760-0392 skweon@skku.edu 총괄책임, 과제관리 차현주 02-760-0392 top1@skku.edu 총괄책임, 과제관리 수행기관(참여)
수행기관(참여) 기관명 담당업무 KDX 데이터 수집 및 정제 메트릭스 데이터 1차 가공 TNMS 데이터 2차 가공 미소정보기술 데이터 검수(구문 정확성, 통계 다양성), 저작도구 아티피셜소사이어티 모델 검증 데이터 관련 문의처
데이터 관련 문의처 담당자명 전화번호 이메일 권상희 02-760-0392 skweon@skku.edu 차현주 02-760-0392 top1@skku.edu
-
인터넷과 물리적으로 분리된 온라인·오프라인 공간으로 의료 데이터를 포함하여 보안 조치가 요구되는 데이터를 다운로드 없이 접근하고 분석 가능
* 온라인 안심존 : 보안이 보장된 온라인 네트워크를 통해 집, 연구실, 사무실 등 어디서나 접속하여 데이터에 접근하고 분석
* 오프라인 안심존 : 추가적인 보안이 필요한 데이터를 대상으로 지정된 물리적 공간에서만 접속하여 데이터에 접근하고 분석 -
- AI 허브 접속
신청자 - 안심존
사용신청신청자신청서류 제출* - 심사구축기관
- 승인구축기관
- 데이터 분석 활용신청자
- 분석모델반출신청자
- AI 허브 접속
-
1. 기관생명윤리위원회(IRB) 심의 결과 통지서 [IRB 알아보기] [공용IRB 심의신청 가이드라인]
2. 기관생명윤리위원회(IRB) 승인된 연구계획서
3. 신청자 소속 증빙 서류 (재직증명서, 재학증명서, 근로계약서 등 택1)
4. 안심존 이용 신청서 [다운로드]
5. 보안서약서 [다운로드]
※ 상기 신청서 및 첨부 서류를 완비한 후 신청을 진행하셔야 정상적으로 절차가 이루어집니다. -
신청 및 이용관련 문의는 safezone1@aihub.kr 또는 02-525-7708, 7709로 문의
데이터셋 다운로드 승인이 완료 된 후 API 다운로드 서비스를 이용하실 수 있습니다.
API 다운로드 파일은 분할 압축되어 다운로드 됩니다. 분할 압축 해제를 위해서는 분할 압축 파일들의 병합이 필요하며 리눅스 명령어 사용이 필요합니다.
리눅스 OS 계열에서 다운로드 받으시길 권장하며 윈도우에서 파일 다운로드 시 wsl(리눅스용 윈도우 하위 시스템) 설치가 필요합니다.
※ 파일 병합 리눅스 명령어
find "폴더경로" -name "파일명.zip.part*" -print0 | sort -zt'.' -k2V | xargs -0 cat > "파일명.zip"
- 해당 명령어 실행 시, 실행 경로 위치에 병합 압축 파일이 생성됩니다.
- 병합된 파일 용량이 0일 경우, 제대로 병합이 되지 않은 상태이니 "폴더경로"가 제대로 입력되었는지 확인 부탁드립니다.
※ 데이터셋 소개 페이지에서 다운로드 버튼 클릭하여 승인이 필요합니다.
오프라인 데이터 이용 안내
본 데이터는 K-ICT 빅데이터센터에서도 이용하실 수 있습니다.
다양한 데이터(미개방 데이터 포함)를 분석할 수 있는 오프라인 분석공간을 제공하고 있습니다.
데이터 안심구역 이용절차 및 신청은 K-ICT빅데이터센터 홈페이지를 참고하시기 바랍니다.

국방데이터 개방 안내
본 데이터는 국방데이터로 군사 보안에 따라 AI허브에서 데이터를 제공하지 않으며,
군 담당자를 통한 별도의 사용 신청이 필요합니다.