-
데이터 변경이력
데이터 변경이력 버전 일자 변경내용 비고 1.1 2023-12-15 데이터 최종 개방 1.0 2023-07-31 데이터 개방(Beta Version) 데이터 히스토리
데이터 히스토리 일자 변경내용 비고 2024-06-14 산출물 전체 공개 소개
· 비대면 온라인 진로상담을 통해 수집된 진로상담 텍스트 데이터 · 진로상담 기록에서 나타난 학생의 추천 직업군을 분류하여, 진로상담 기록에서 추천 진로를 예측하는 데이터
구축목적
진로상담 과정에서 대화 맥락에 맞는 문장을 구성하여 제공할 수 있는 AI를 학습 · 학생의 상담 데이터를 기반으로 적합한 진로 계열을 예측할 수 있는 AI를 학습
-
메타데이터 구조표 데이터 영역 교육 데이터 유형 텍스트 데이터 형식 txt 데이터 출처 자체 수집 라벨링 유형 내용요약 / 진로분류 라벨링 형식 JSON 데이터 활용 서비스 챗봇 서비스 데이터 구축년도/
데이터 구축량2022년/826,160건 -
원천 데이터, 가공 데이터 통계 구분 파일명 수량 포맷 용량 원천데이터 상담기록 데이터 상담기록_데이터_6500 826,160건 JSON 0.126GB (발화 기준) 학생기초설문 답변데이터 학생기초정보_데이터_6500_202301_check 6,500건 JSON 0.004GB 한국어 직업분류 메타정보 데이터 3. 한국어_직업기초 데이터 43건 JSON 0.001GB 가공데이터 전문가라벨링 데이터 labeling_docs_원천데이터_번역추가_6500_202301 6,500건 JSON 0.07GB 영어 직업분류 메타정보 데이터 영어_직업기초 데이터 43건 JSON 0.001GB 필리핀어 직업분류 메타정보 데이터 필리핀어_직업기초 데이터 43건 JSON 0.001GB 베트남어 직업분류 메타정보 데이터 베트남어_직업기초 데이터 43건 JSON 0.001GB 다양성 통계 품질 검증 항목명 지표 결과 특성 유형 다양성 통계 학년별 분포 구성비 수집 예정 통계 진로카테고리 분포 구성비 수집 예정 통계 추천 직업군 분포 구성비 수집 예정 통계 학생 지역 분포 구성비 응답없음 37.22% 성남시 중원구 15.70% 성남시 분당구 8.35% 성남시 수정구 7.34% 화성시 안녕동 4.81% 성남시 분당구 2.53% 화성시 송산동 2.53% 기타 21.52% 통계 학생 성별 분포 구성비 여 39.75% 응답없음 37.22% 남 23.04% 통계 학생성적등급 분포 구성비 상 33.42% 중 36.71% 하 29.87% 다양성 통계2 품질 검증 항목명 지표 결과 특성 유형 다양성 통계 상담사/학생 별 구성비 범위 건수 비율 상담내용 어절 수 분포 0 ~ 12 67845 86.50% 13 ~ 24 9330 11.89% 25 ~ 36 1033 1.32% 37 ~ 48 147 0.19% 49 ~ 60 56 0.07% 61 ~ 72 14 0.02% 73 ~ 84 7 0.01% 85 ~ 96 5 0.01% 97 ~ 108 0 0% 109 ~ 120 1 0.00% 통계 요약문 구성비 범위 건수 비율 어절 수 분포 0 ~ 8 2 1.82% 9 ~ 16 0 0.00% 17 ~ 24 0 0.00% 25 ~ 32 0 0.00% 33 ~ 40 0 0.00% 41 ~ 48 6 5.45% 49 ~ 56 46 41.82% 57 ~ 64 36 32.73% 65 ~ 72 15 13.64% 73 ~ 80 5 4.55% 요건 학교급 구성비 초등 8.10% 분포 중첩률 중등 34.68% 목표 구성비 고등 57.22% 초등 34% 구성비중첩률 47.91% 중등 44% 고등 22% 요건 상담 구성비 자아이해 19.68% 카테고리 분포 중첩률 직업세계이해 11.90% 목표 구성비 교육기회탐색 18.84% 자아이해 20% 직업정보탐색 15.59% 직업세계이해 20% 기타 33.99% 교육기회탐색 20% 구성비중첩률 75.45% 직업정보탐색 20% 기타 20% -
-
AI 모델 상세 설명서 다운로드
AI 모델 상세 설명서 다운로드 AI 모델 다운로드① 대화형 모델
- 상담기록 데이터의 이전 맥락(약 10턴 내외의 발화)을 입력으로 받아 채팅 답변을 생성하는 일반 교사의 상담 보조 목적 대화형 모델 개발
·학생별로 진행된 상담기록 데이터 전체를 Language Model의 학습 데이터로 삼아, 주어진 이전 대화 맥락(약 10턴 내외)에 이어지는 상담사의 답변을 생성하도록 학습
·모델 성능 평가를 위해 하나의 상담기록 데이터에서 8개 대화세션을 추출하고, 나머지 대화세션 전체를 학습 데이터로 사용
- GPT-NeoX 기반 모델 구조 설계
·EleutherAI에서 오픈소스로 공개한 한국어 언어 모델 Polyglot-5.8B 모델을 기반으로 추가 전이 학습 (Fine-Tuning) 수행
·상담의 맥락을 고려하여 모델의 최대 입력 Token 수를 512로 제한
·상담 대화 채팅의 특성상 GPT가 학습하는 우측 Masking을 그대로 사용하여 학습을 진행할 수 있음
·상담사 대화 시작인 “[1]”을 프롬프트(Prompt)로 사용해 맥락에 맞는 대화를 생성하도록 학습
- 학습된 모델은 MOS, SSA 지표로 성능을 측정하며, 최종 수치는 추후 평가 예정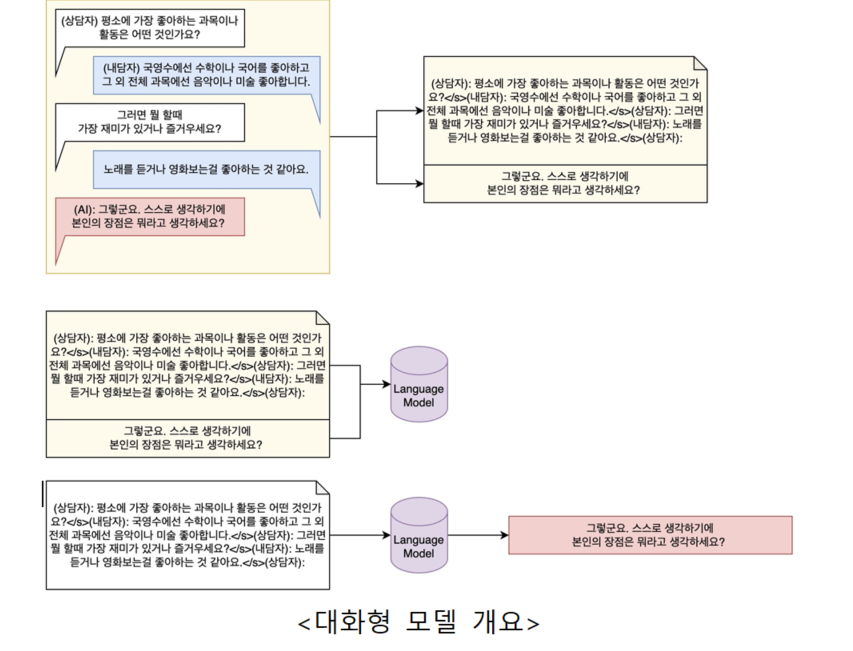
② 분류형 모델
- 대화 형식의 상담기록 데이터를 입력받아 추천 직업군을 예측하는 분류형 모델 개발
· 학생별로 2번에 걸쳐 진행된 상담기록 데이터를 모두 입력으로 받아 43개의 직업 카테고리 중 가장 적합한 것을 출력
· 구축한 데이터셋을 8:1:1 비율로 나눠(Split) 각각 Train/Validation/Test Set으로 활용
- TF-IDF 변형 알고리즘과 한국어 RoBERTa 기반의 모델 구조 설계
· 업스테이지, 네이버 CLOVA 등에서 공개한 Pre-Trained KLUE-RoBERTa-large 모델을 구축 데이터셋으로 추가 전이 학습(Fine-Tuning)
· 상담기록 데이터는 매우 긴 Text Length를 갖는데, 일반적인 Transformer 기반의 Language Model은 이러한 데이터를 처리하기에 적합하지 않음
· 긴 Text Length 데이터를 처리하는 데에 특화된 KoBigBird 모델 구조를 초기에 제안하였으나, 정답을 도출하는 데에 유의미하지 않은 정보가 다수 포함된 입력 데이터 특성상, TF-IDF를 활용하여 주요 키워드를 추출한 후 이를 Language Model에 입력하는 방식이 더 유리하다고 판단
· 추출하는 키워드 집합은 Document Frequency Threshold 값에 따라 달라지는데, Validation Set에서 가장 좋은 성능을 보이는 값(0.3)으로 설정
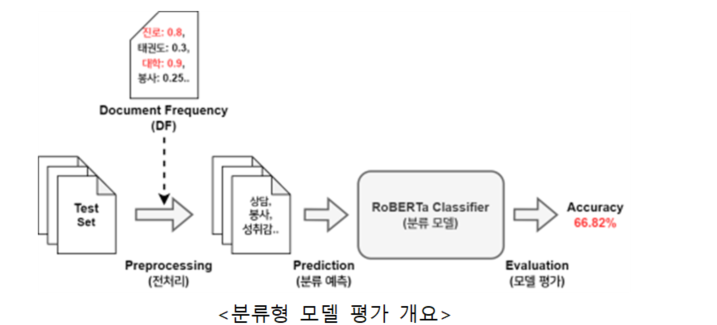
- 학습된 모델은 Accuracy 지표로 성능을 측정하며, 최종적으로 66.82%의 수치를 기록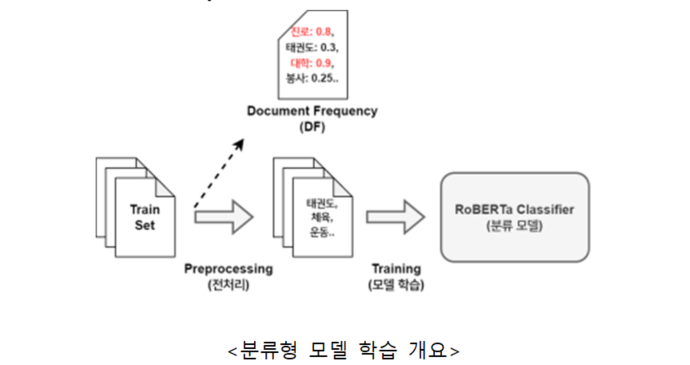
-
데이터 성능 점수
측정값 (%)기준값 (%)데이터 성능 지표
데이터 성능 지표 번호 측정항목 AI TASK 학습모델 지표명 기준값 점수 측정값 점수 1 직업군 추천 성능 Question Answering TF-IDF(변형), RoBERTa AccuracyTop-1 60 % 66.82 % 2 상담사 챗봇 성능 Question Answering GPT-NeoX, Polyglot-5.8b-ko SSA(MOS) 60 % 71.65 %
※ 데이터 성능 지표가 여러 개일 경우 각 항목을 클릭하면 해당 지표의 값이 그래프에 표기됩니다.
※ AI모델 평가 지표에 따라 측정값의 범위, 판단 기준이 달라질 수 있습니다. (ex. 오류율의 경우, 낮을수록 좋은 성능을 내는 것으로 평가됩니다)
-
설명서 및 활용가이드 다운로드
데이터 설명서 다운로드 구축활용가이드 다운로드원천데이터 포맷
원천데이터 포맷 세부 데이터 데이터 포맷 1 상담기록 데이터 json 2 학생기초설문 답변데이터 json 3 한국어 직업분류 메타정보 데이터 json 1) 상담기록 데이터(json)
상담기록 데이터(json) No 속성 속성설명 데이터타입 필수여부 예시 1 meta student idx 학생 ID string Y “S-0001”,“S-0002”... counseling_idx 상담회차 string Y 1,2.. counsellor_idx 상담자 ID string Y “T-0001”.. counselling_purpose 상담목적 string Y “저는 자기자신에 대해 알고 싶고 앞으로 4차산업관련 직업들도 알고 싶어서 신청하게 되었습니다..” counselling_satisfaction 상담만족도 int N 1,2,3,4,5 (likert) counselling_date 상담일시 date Y “2022-08-24” 2 conversation conv_category 대화목적 string Y “자아이해“,”직업탐색“.. self_eval 상담수준 array Y likert array [5,3,4] utterances speaker_idx 발화자ID string Y “S-0001”,“T-0001”... utterance 발화내용 string Y “저는 컴퓨터를 좋아해요!” utterance_idx 발화순서 int Y 1,2,3... utterance_delaytime 발화대기시간 float Y 1.32, 4.62, 14.12, ... // 살짝 합친 형태 Counselling > Conversation > Utterance
[
{ // 1개의 Counselling
"Meta": {
"student idx": "S-0001",
"counseling_idx": 1,
"counsellor_idx": "T-0001",
"CounsellingPurpose": "상담을 받고 싶어요.", “counselling_satisfaction“:4,
“counselling_date“:”2022-08-24“,
},
"Conversation": {
// 1개의 Conversation, 인덱스, Counselling 내부의 구별자.
1: {
"SelfEval": [5,4,5],
"Utterances": [
{
"speaker_idx": "S-0001",
"utterance": "저는~~~",
"utterance_idx": 1,
},
{
"speaker_idx": "T-0001",
"utterance": "컴퓨터를 쓰며~",
"utterance_idx": 2, // Not Unique, Conversation 내부의 순서만.
},
],
},
2: {...},
}
},
{...},
...,
]2) 학생기초정보 데이터(json)
학생기초정보 데이터(json) No 속성 속성설명 데이터타입 필수여부 예시 1 meta_basics index 학생 ID string Y “S-0001”,“S-0002”... school_type 학교급 string Y “초등학교”,“중학교”,“고등학교” region 지역 string N “성남시 수정구” gender 성별 string N “남”,“여”,“무응답” 2 preliminary_inspection grade 성적수준 string Y “초등”, “중등”, “고등” counselling_purpose 상담목적 string Y “저는 자기자신에 대해 알고 싶고 앞으로 4차산업관련 직업들도 알고 싶어서 신청하게 되었습니다..” surveys question 질문문항 string Y “대학교 학과에 대해 들어본 적이 있나요?” answer 답변 int Y 1,2,3,4,5 likert 척도 // student_.json or studentinfo.json
{
"StudentMetaData": {
"MetaBasics": {
"UID": 1234,
"SchoolType": "중학교",
"Region": "성남시 분당구",
"Gender": "남/여/무응답",
},
"PreliminaryInspection": {
"Grade": "상/중/하",
"CounsellingPurpose": "상담을 받고 싶어요.",
"Surveys": [
{
"Question_1": "자기자신에 대해 얼마나 알고있다고 생각하나요?",
"Answer_1": 4,
},
{
"Question_2": "대학교 학과에 대해 들어본 적이 있나요?",
"Answer_2": 5,
},
...
]
}
}
}3) 한국어_직업기초 데이터 (json)
한국어_직업기초 데이터 (json) No 속성 속성설명 데이터타입 필수여부 예시 1 index 직업분류 ID string Y “J-001”,“J-002”... category 직업분류 카테고리 string Y “기술계열,”서비스계열“,”생산계열“,”사무계열“ .. name 직업분류명 string Y “법률직”,“정보통신 설치정비직”... detail_information annual_expectedIncome(KRW) 기대연봉 string Y 80,000,000 required_ability 필요능력 array Y “수리통계능력”,“정보활용능력”... related_departments 관련학과 array Y “통계학과”,“컴퓨터공학과”... [{
"Index": 1,
"Category": "4차산업 ",
"SubCategory": "정보통신계열",
"DetailInformation": {
"AnnualExpectedIncome(KRW)": 80000000,
"RequiredAbility": [
"수리통계능력",
"정보활용능력",
...
],
"RelatedDepartments": [
"통계학과",
"컴퓨터공학과",
...
],
...
},
...
},...]라벨링데이터 포맷
라벨링데이터 포맷 세부 데이터 데이터 포맷 1 전문가라벨링 데이터 json 2 영어 직업분류 메타정보 데이터 json 3 필리핀어 직업분류 메타정보 데이터 json 4 베트남어 직업분류 메타정보 데이터 json 1) 전문가 라벨링 데이터 (json
전문가 라벨링 데이터 (json No 속성 속성설명 데이터타입 필수여부 예시 1 student_idx 학생 ID string Y “S-0001”,“S-0002”... 2 counselling_summaries counseling_idx 상담회차 string Y 1,2.. highlights start_idx 하이라이트 시작 인덱스 int N 10,15.. end_idx 하이라이트 끝 인덱스 int N 20,30.. summary 상담요약 string Y “학생의 흥미는 주로 기계를 다루는 쪽에 집중되어 있는 것으로 보이며 .. ” 3 recommended_job_categories priority 추천순위 int Y 1,2,3... job_category_idx 직업분류 인덱스 string Y “J-001”,“J-002”... job_label 추천직업카테고리 string Y “기술계열,”서비스계열“,”생산계열“,”사무계열“ .. 4 expert_comment ko 전문가 코멘트 (한국어) string “컴퓨터관련 직업이 적합해보이며 문제해결역량을 더 강화하면 도움이 크게 될 것입니다... ” en 전문가 코멘트 (영어) string “Computer-related jobs seem appropriate, and if you strengthen your problem-solving skills, it will be of great help.” tl 전문가 코멘트 (필리핀어) string “Ang mga trabahong nauugnay sa computer ay tila angkop, at kung palalakasin mo ang iyong mga kasanayan sa paglutas ng problema, ito ay magiging malaking tulong” vi 전문가 코멘트 (베트남어) string “Công việc liên quan đến máy tính có vẻ phù hợp và nếu tăng cường năng lực giải quyết vấn đề thì sẽ giúp ích rất nhiều” 5 hashtags 대화특성 array N “#대답을잘함”,“#적극적임”.. [{
"student_idx": "s-00001",
"counselling_summaries": [
{
"counselling_idx": 1,
"highlights": [
{
"start_idx": 10,
"end_idx": 15
}, ...
],
"summary": "~~"
},
{
"counselling_idx": 2,
"highlights": [
{
"start_idx": 120,
"end_idx": 130
}, ...
],
"summary": "~~"
}
],
"recommended_job_categories": [
{
"priority": 1,
"job_category_idx": 7
},
...
],
"expert_comment": {
"ko": "ㅁㄴㅇㄹ",
"en": "aaaa",
"tl": "",
"vi": "",
},
"hashtags": [
"#대답을 잘 함",
"#적극적임",
...
]
}, ...]) -
데이터셋 구축 담당자
수행기관(주관) : ㈜데이터드리븐
수행기관(주관) 책임자명 전화번호 대표이메일 담당업무 김기범 02-875-5075 kb.kim@datadriven.kr 과제 총괄 운영, 전문가 레이블링, AI 학습 및 모델링 수행기관(참여)
수행기관(참여) 기관명 담당업무 데이터헌트(주) 원시데이터 수집, 원천데이터 정제, 크라우드소싱 운영 어니컴(주) 데이터 품질검사, AI 모델 품질검사, 품질 관리기관 대응 성남시 행정지원과 투자, 거버넌스 이슈 대응, 시 차원의 성과 홍보 경기도성남교육지원청 진로교사 자문, 학부모 네트워크 활용, 학교 협력 거버넌스 운영 성남형교육지원단 학교지원 프로그램 운영, 학교 협력체계 구성, 사업 성과 활용방안 기획 데이터 관련 문의처
데이터 관련 문의처 담당자명 전화번호 이메일 김기범 02-875-5075 kb.kim@datadriven.kr
-
인터넷과 물리적으로 분리된 온라인·오프라인 공간으로 의료 데이터를 포함하여 보안 조치가 요구되는 데이터를 다운로드 없이 접근하고 분석 가능
* 온라인 안심존 : 보안이 보장된 온라인 네트워크를 통해 집, 연구실, 사무실 등 어디서나 접속하여 데이터에 접근하고 분석
* 오프라인 안심존 : 추가적인 보안이 필요한 데이터를 대상으로 지정된 물리적 공간에서만 접속하여 데이터에 접근하고 분석 -
- AI 허브 접속
신청자 - 안심존
사용신청신청자신청서류 제출* - 심사구축기관
- 승인구축기관
- 데이터 분석 활용신청자
- 분석모델반출신청자
- AI 허브 접속
-
1. 기관생명윤리위원회(IRB) 심의 결과 통지서 [IRB 알아보기] [공용IRB 심의신청 가이드라인]
2. 기관생명윤리위원회(IRB) 승인된 연구계획서
3. 신청자 소속 증빙 서류 (재직증명서, 재학증명서, 근로계약서 등 택1)
4. 안심존 이용 신청서 [다운로드]
5. 보안서약서 [다운로드]
※ 상기 신청서 및 첨부 서류를 완비한 후 신청을 진행하셔야 정상적으로 절차가 이루어집니다. -
신청 및 이용관련 문의는 safezone1@aihub.kr 또는 02-525-7708, 7709로 문의
데이터셋 다운로드 승인이 완료 된 후 API 다운로드 서비스를 이용하실 수 있습니다.
API 다운로드 파일은 분할 압축되어 다운로드 됩니다. 분할 압축 해제를 위해서는 분할 압축 파일들의 병합이 필요하며 리눅스 명령어 사용이 필요합니다.
리눅스 OS 계열에서 다운로드 받으시길 권장하며 윈도우에서 파일 다운로드 시 wsl(리눅스용 윈도우 하위 시스템) 설치가 필요합니다.
※ 파일 병합 리눅스 명령어
find "폴더경로" -name "파일명.zip.part*" -print0 | sort -zt'.' -k2V | xargs -0 cat > "파일명.zip"
- 해당 명령어 실행 시, 실행 경로 위치에 병합 압축 파일이 생성됩니다.
- 병합된 파일 용량이 0일 경우, 제대로 병합이 되지 않은 상태이니 "폴더경로"가 제대로 입력되었는지 확인 부탁드립니다.
※ 데이터셋 소개 페이지에서 다운로드 버튼 클릭하여 승인이 필요합니다.
오프라인 데이터 이용 안내
본 데이터는 K-ICT 빅데이터센터에서도 이용하실 수 있습니다.
다양한 데이터(미개방 데이터 포함)를 분석할 수 있는 오프라인 분석공간을 제공하고 있습니다.
데이터 안심구역 이용절차 및 신청은 K-ICT빅데이터센터 홈페이지를 참고하시기 바랍니다.

국방데이터 개방 안내
본 데이터는 국방데이터로 군사 보안에 따라 AI허브에서 데이터를 제공하지 않으며,
군 담당자를 통한 별도의 사용 신청이 필요합니다.